使用 MapReduce 进行分布式计算¶
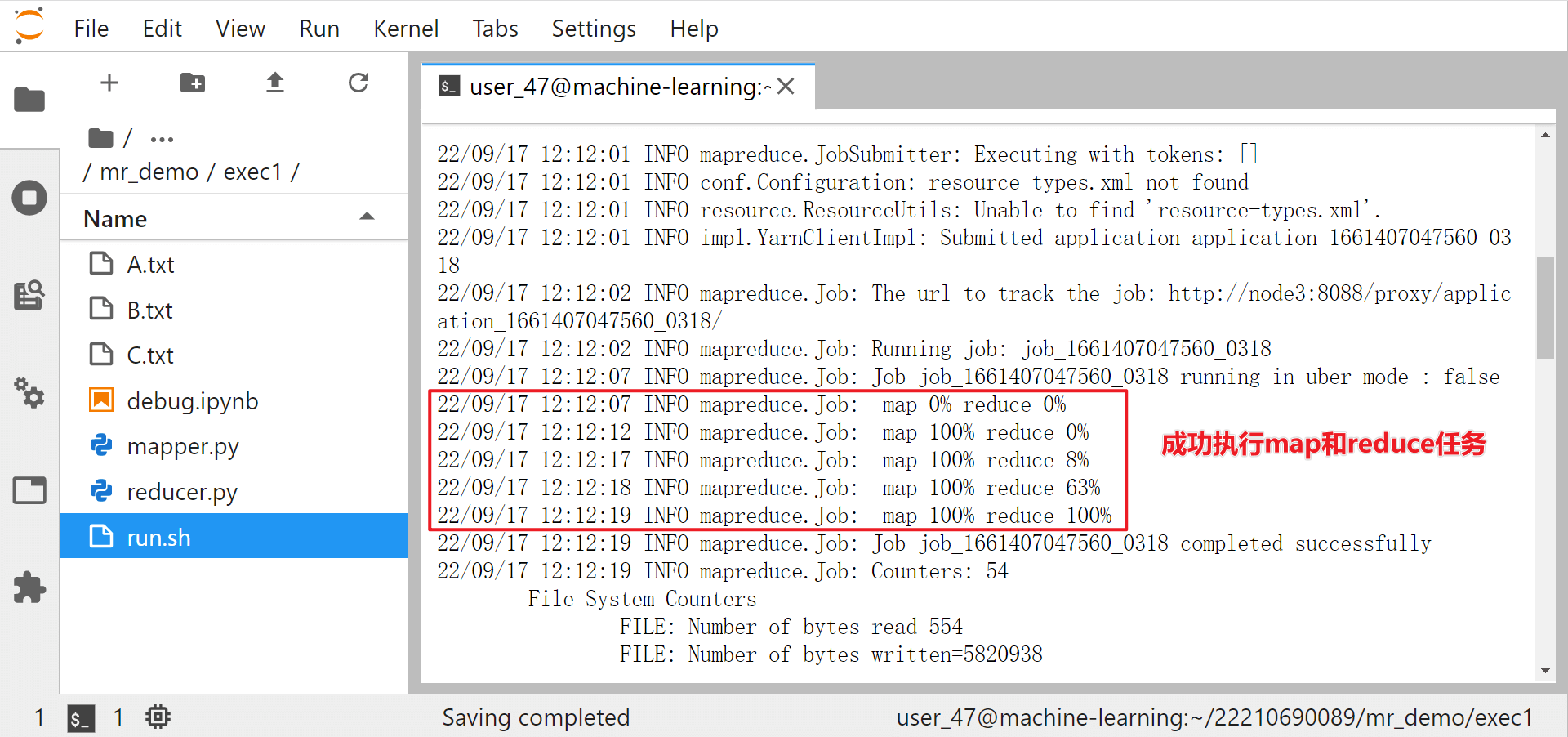
使用 MapReduce 进行分布式计算的工作流程,包括输入输出文件路径、map 和 reduce 文件、执行文件 run.sh 的编写以及查看输出文件。
问题描述¶
我们需要将两个文件A.txt和B.txt去重后合并为C.txt。利用 MapReduce 分布式计算完成这一任务。
在 HDFS 上存放输入文件¶
现在A.txt和B.txt还存放在本地,因此我们需要将这两个输入文件上传到 HDFS 上。
Bash
# 在Hadoop的/user/22210690089/目录下,创建项目目录
hdfs dfs -mkdir /user/22210690089/compose
# 再创建input目录,用于存放输入文件
hdfs dfs -mkdir /user/22210690089/compose/input
# 再创建output目录,用于存放输出文件
hdfs dfs -mkdir /user/22210690089/compose/output
# 将本地的`A.txt`和`B.txt`上传到input目录中
hdfs dfs -put ./*.txt /user/22210690089/compose/input
编写mapper.py和reducer.py¶
设计mapper.py和reducer.py,处理输入数据,并得到输出数据。
mapper.py¶
-
for line in sys.stdin:就是遍历输入数据A.txt和B.txt的每一行。 -
print(field+"::"+field)并不会在 Hadoop 服务器上打印什么东西,它是中间输出,会作为reducer.py的输入,在reducer.py中继续进行运算。
Python
# mapper.py
import sys
# loop for each line
for line in sys.stdin:
field = line.strip()
print(field + "::" + field)
reducer.py¶
Python
# reducer.py
import sys
result = {}
for line in sys.stdin:
kvs = line.strip().split("::")
k = kvs[0]
v = kvs[1]
if not (k in result):
result[k] = v
for k, v in result.items():
print(v)
for line in sys.stdin:就是遍历mapper.py最后的每一个print(field+"::"+field)。
注意事项:mapper.py和reducer.py不能有中文¶
mapper.py和reducer.py不能有中文,注释也不能有中文。虽然在本地执行mapper.py和reducer.py的时候,有中文的注释不会报错,但在 MapReduce 端,由于 MapReduce 的底层代码是用 Java 写的,在编译代码的时候可能会报错。
配置run.sh¶
现在mapper.py和reducer.py都在本地,我们需要告诉 MapReduce:将本地的mapper.py和reducer.py作为执行计算任务的脚本。
INPUT_FILE_PATH是 HDFS 上的输入文件所在的目录。OUTPUT_PATH是 HDFS 上的输出文件所在的目录。# Step 1.下面的代码用了很多\,这是为了阅读起来更方便,所以将代码换行。在运行的时候,$后面的所有文本实际上都是一行命令。-mapper "python mapper.py"中的mapper.py是执行 Map 任务的脚本。-file ./mapper.py是执行 Map 任务的脚本的本地文件路径。-reducer "python reducer.py"中的reducer.py是执行 Reduce 任务的脚本。-file ./reducer.py是执行 Reduce 任务的脚本的本地文件路径。
Bash
HADOOP_CMD="/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/bin/hadoop"
STREAM_JAR_PATH="/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hadoop-streaming-3.0.0-cdh6.3.2.jar"
INPUT_FILE_PATH="/user/22210690089/compose/input/"
OUTPUT_PATH="/user/22210690089/compose/output/"
$HADOOP_CMD fs -rm -r -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH \
-output $OUTPUT_PATH \
-mapper "python mapper.py" \
-reducer "python reducer.py" \
-file ./mapper.py \
-file ./reducer.py
将run.sh的权限设置为所有者可执行,组用户和其他用户只读¶
执行run.sh¶
然后就可以直接在本地终端输入
即可执行 MapReduce 任务。
查看输出文件¶
可以看到,输出文件分布式地存储在各个文件中。
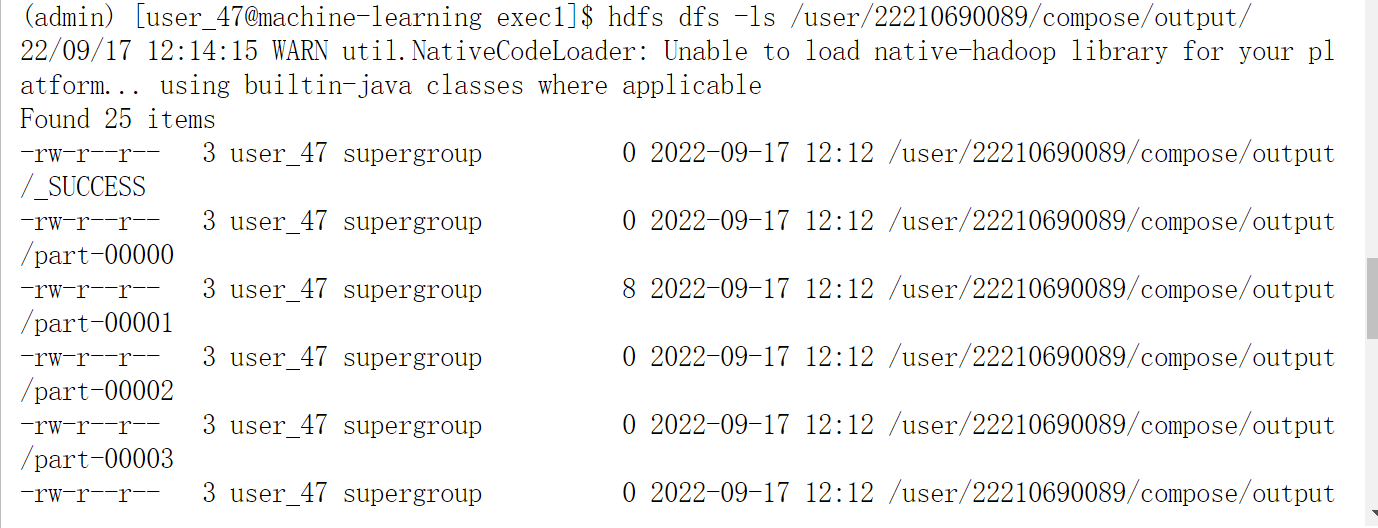
可以用cat查看。
