matplotlib 动态绘图——神经网络训练过程可视化
本文使用 matplotlib 实现动态绘图,可以用于查看神经网络训练过程的损失值和评估指标的变化情况。
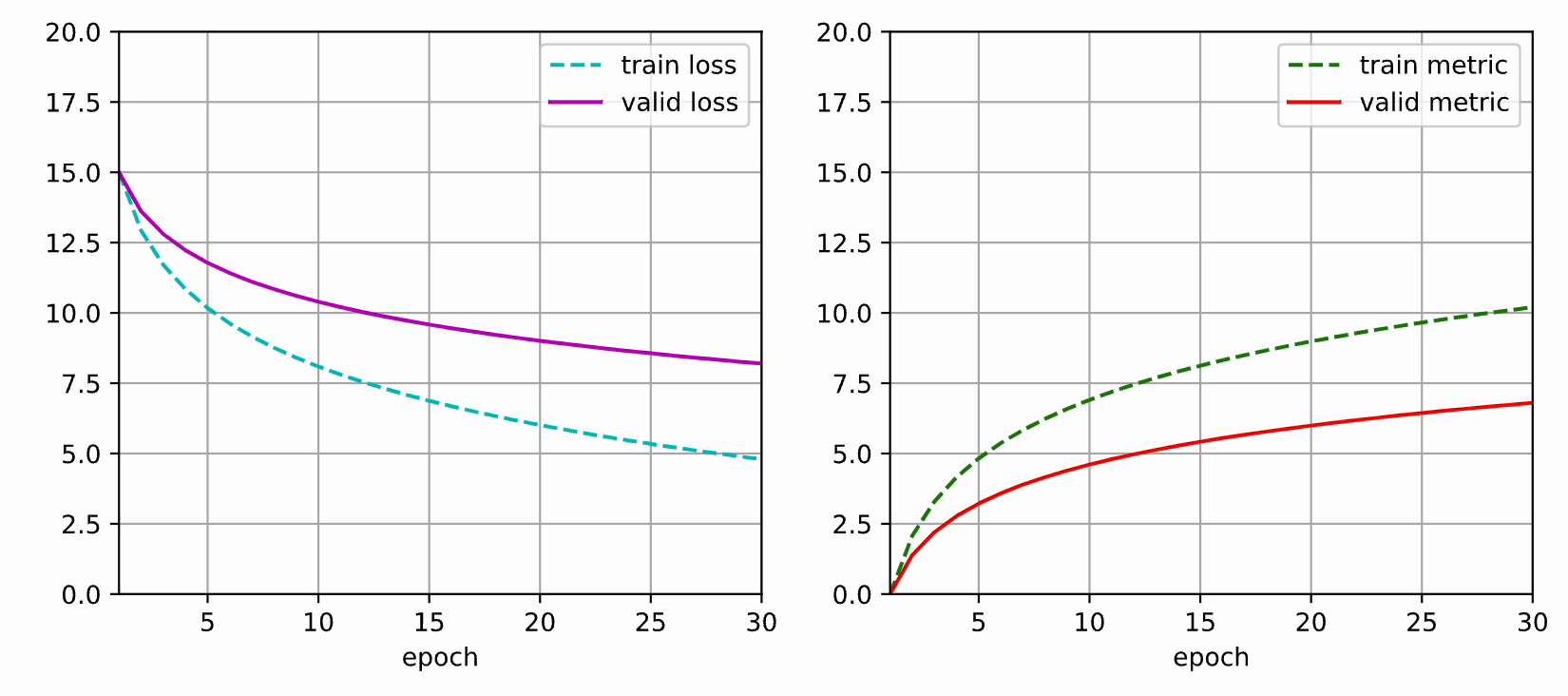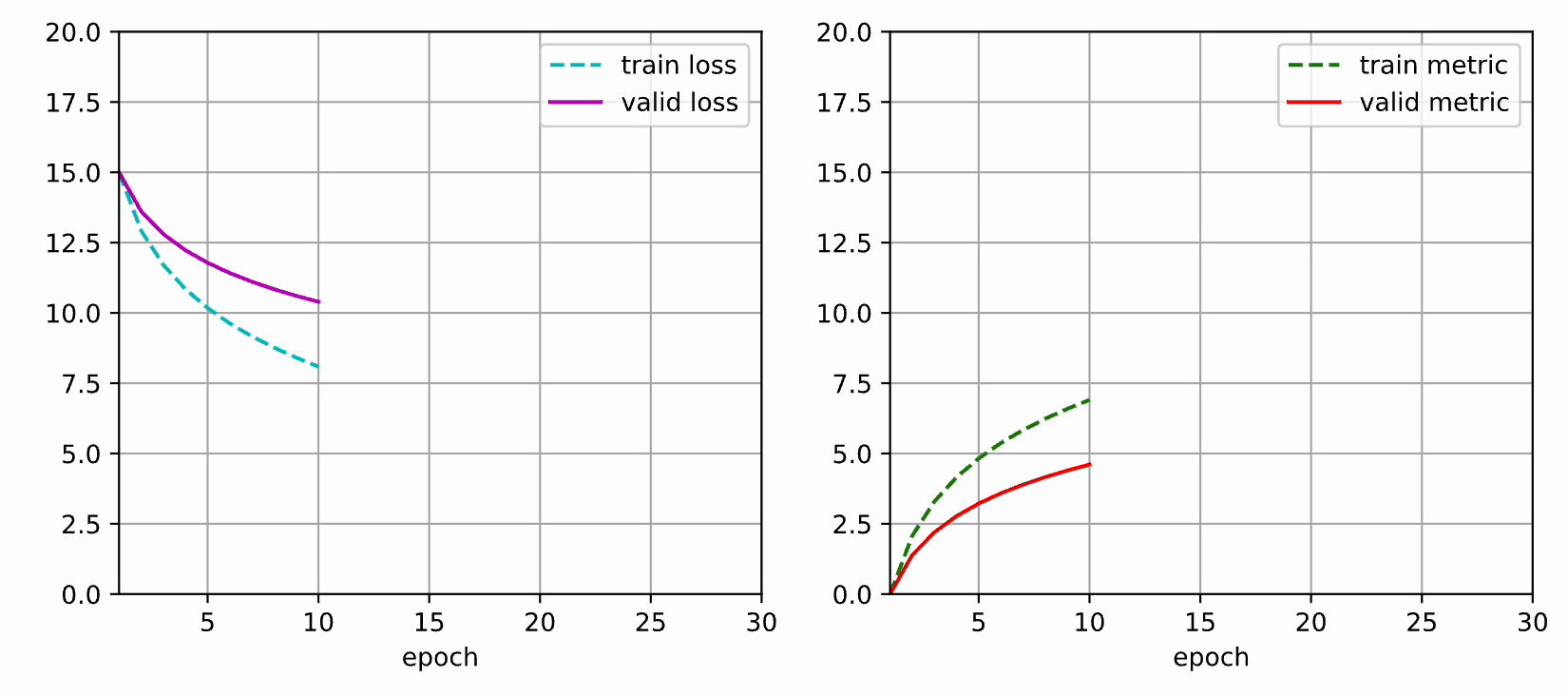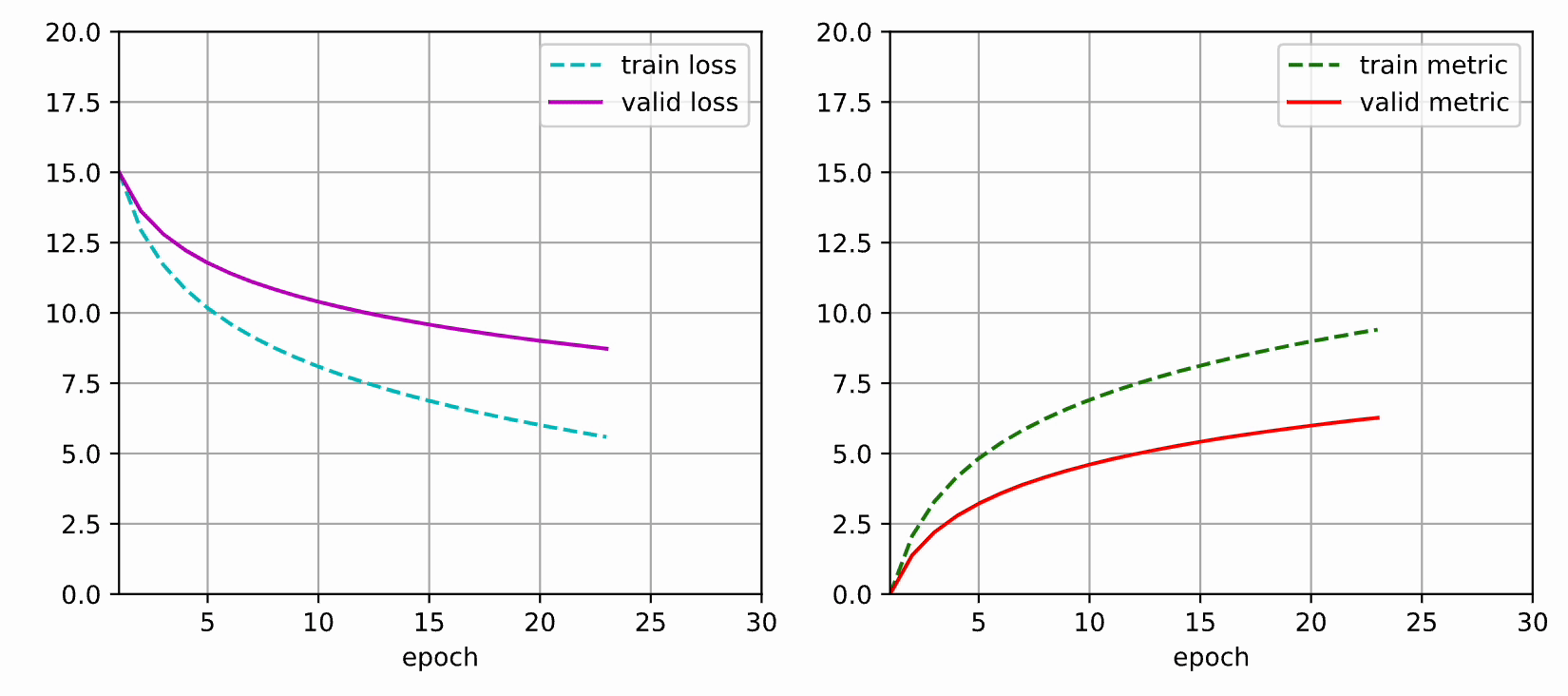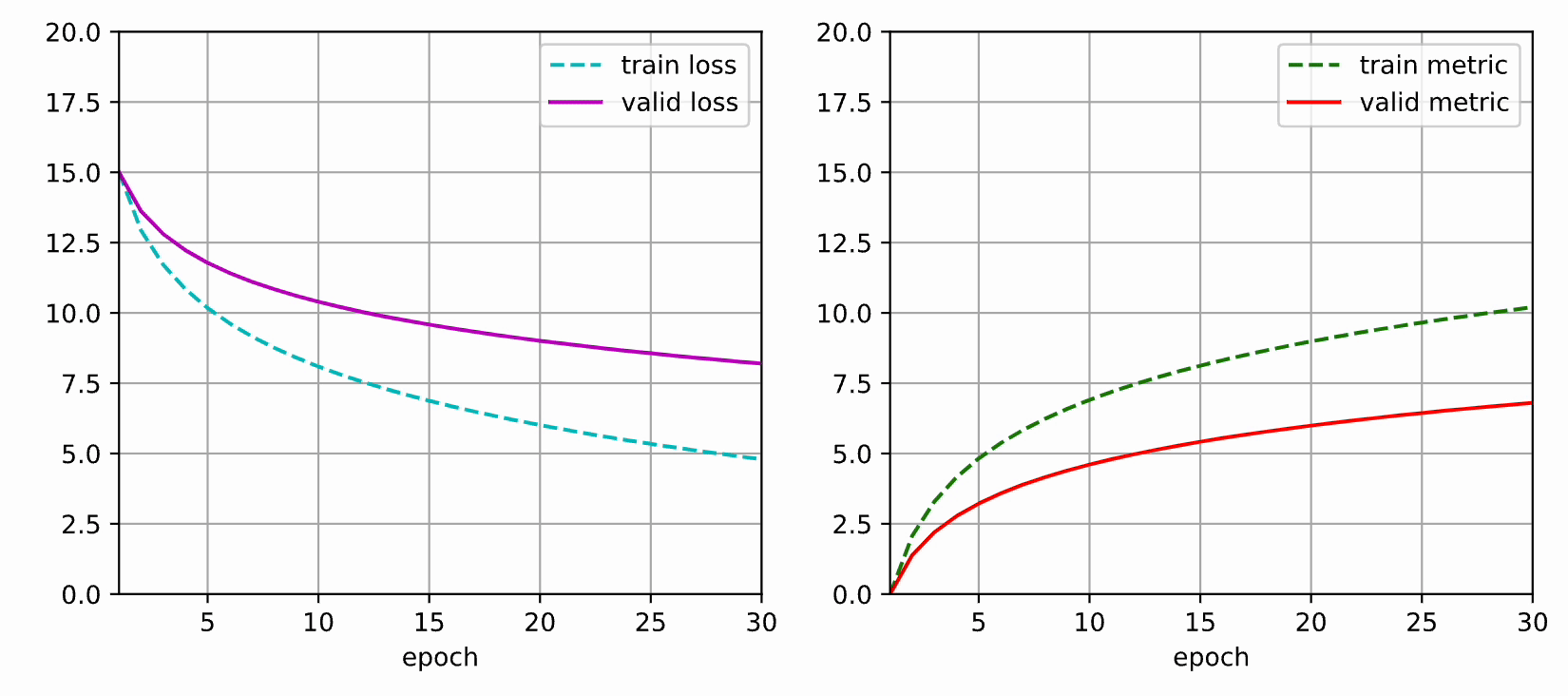
本文部分代码参考了《动手学深度学习》的
utils.py中的函数。
matplotlib 动态绘图——神经网络训练过程可视化本文使用 matplotlib 实现动态绘图,可以用于查看神经网络训练过程的损失值和评估指标的变化情况。
本文部分代码参考了《动手学深度学习》的
utils.py中的函数。
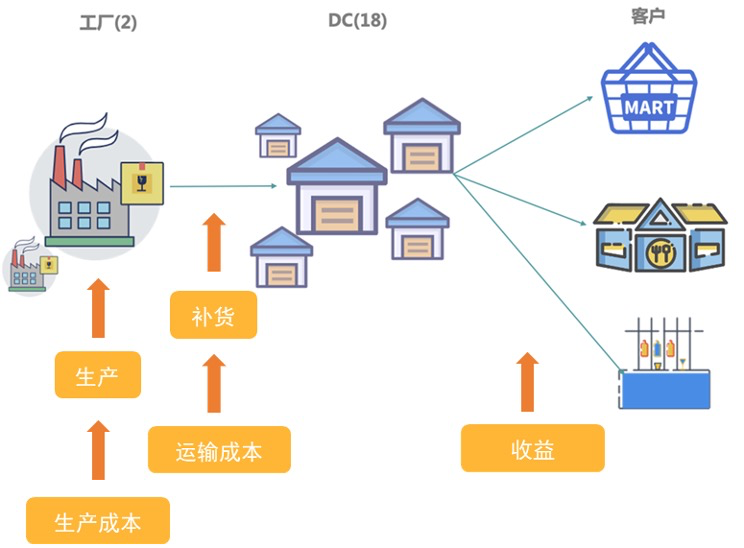
本文基于某饮料企业的工厂、仓库与商品相关的历史信息,结合随机模拟的售价与成本数据,构建了多工厂、多仓库的生产与补货优化模型。
数值试验表明,本文构建的优化后的生产与补货模型能够比基线模型(简单基于历史销量而固定生产量)多获得约 500 万元的利润,且在补货行为上更具优势。对工厂和仓库容量的灵敏度分析表明,工厂 2 和 DC4、5、7、14 多具有当前容量较小、运输成本低、历史销量高等特点,对它们进行扩容能够取得显著的回报增益。对整托约束的松弛表明,整托运输虽以节省运输成本为目的,但实际却可能造成运输资源的浪费,而考虑适当放松整托约束有潜力能够提高约 100 万元的利润。
本文使用 8 种经典的分类器,基于逆概率错误进行 Conformal Learning。
本文使用了 nonconformist 包,它在使用 Conformal Learning 进行分类预测时的核心步骤是:
InverseProbabilityErrFunc,它等于 1-predict_probability[true_y]。例如,某个样本的真实标签是 1,而模型预测出该样本属于标签 1 的概率是 0.9,则 ErrFunc 的值是 1-0.9=0.1。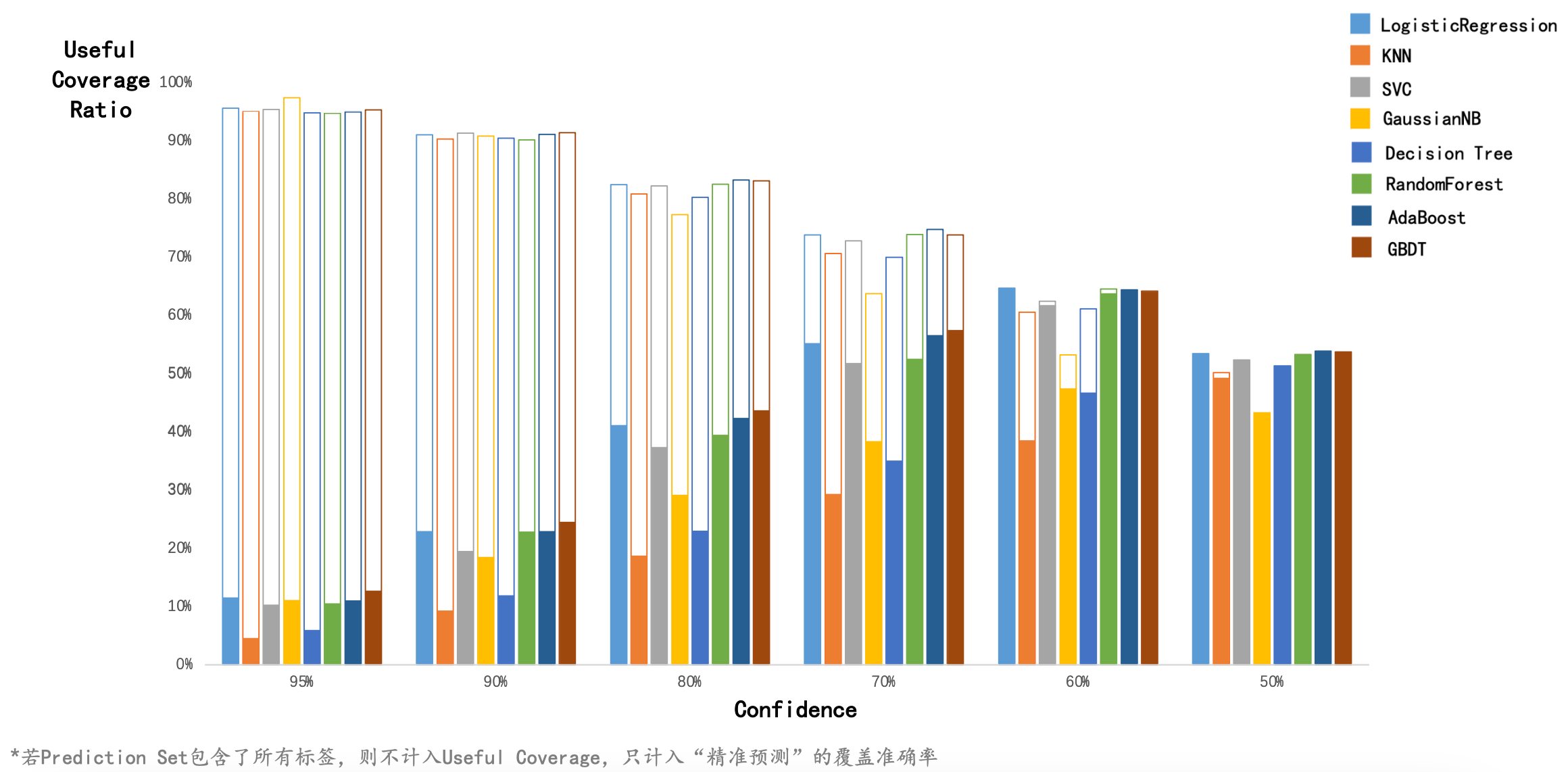
本项目的完整展示文件在这里。
本文整理了深度学习期末考试 Cheat Sheet。内容包括:
PDF 版 Cheat Sheet 在这里。