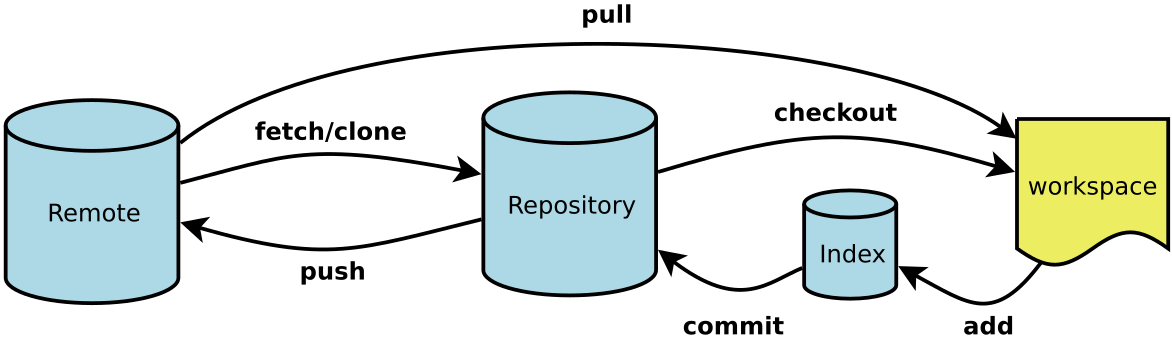
Python 进阶教程系列 5:获取和修改被保护的属性
本文是 Python 进阶教程系列 5,主要介绍了 Python 私有化及 _ 下划线命名用途,以及使用 getter 、 setter 和 property 来修改被保护的属性。
本文部分转载了 Python 私有化及 _ 下划线命名用途,已获得原作者授权。
Python 中没有真正的私有属性或方法,但有一些和命名有关的约定,让编程人员处理一些需要私有化的情况。我们常常需要区分私有方法、属性和公有方法、属性以方便管理和调用,在 Python 中如何做呢?
在变量、方法命名中有下列几种情况:
xx公有变量/方法_xx前置单下划线__xx前置双下划线__xx__前后双下划线xx_后置单下划线
接下来分别介绍这几种带下划线命名的特性与区别。