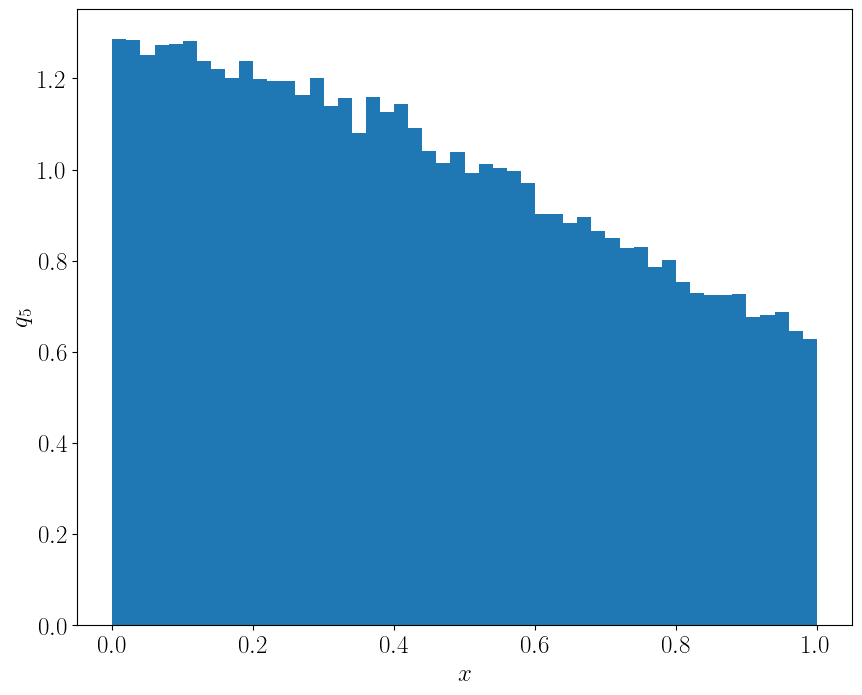
因子半衰期
对于一个时间序列,我们可以构建一个逐渐衰减的时间序列模型来估计其半衰期。本文介绍了两个模型,用于估计一个时间序列的半衰期。
在量化研究中,了解各个因子的衰减情况,可以更有效地动态分配因子权重,以适应市场变化。
对于一个时间序列,我们可以构建一个逐渐衰减的时间序列模型来估计其半衰期。本文介绍了两个模型,用于估计一个时间序列的半衰期。
在量化研究中,了解各个因子的衰减情况,可以更有效地动态分配因子权重,以适应市场变化。
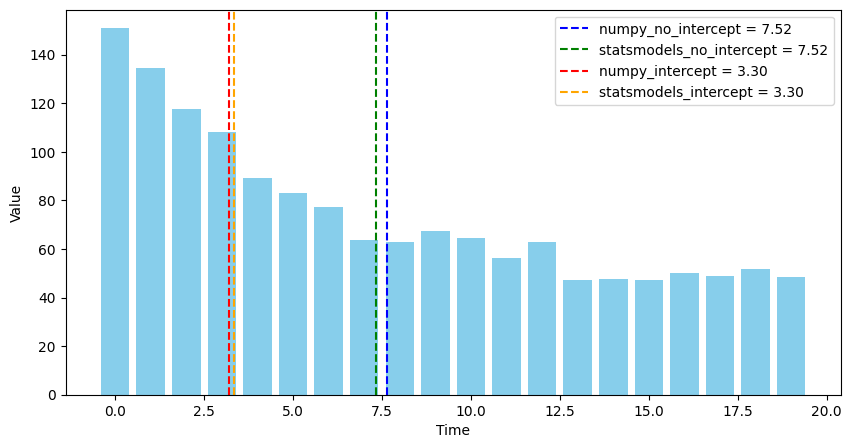
本文使用相关系数的矩阵表达形式,实现了计算部分相关系数矩阵的加速算法,并实证检验了三种计算相关系数矩阵方法的运行速度。
.corr() 方法提速约 2180 倍,比 Numpy .corrcoef() 方法提速约 115 倍。.corrcoef() 方法比自定义的加速算法略快 \(10\%\),比 Pandas .corr() 方法快约 20 倍。本文使用 8 种经典的分类器,基于逆概率错误进行 Conformal Learning。
本文使用了 nonconformist 包,它在使用 Conformal Learning 进行分类预测时的核心步骤是:
InverseProbabilityErrFunc,它等于 1-predict_probability[true_y]。例如,某个样本的真实标签是 1,而模型预测出该样本属于标签 1 的概率是 0.9,则 ErrFunc 的值是 1-0.9=0.1。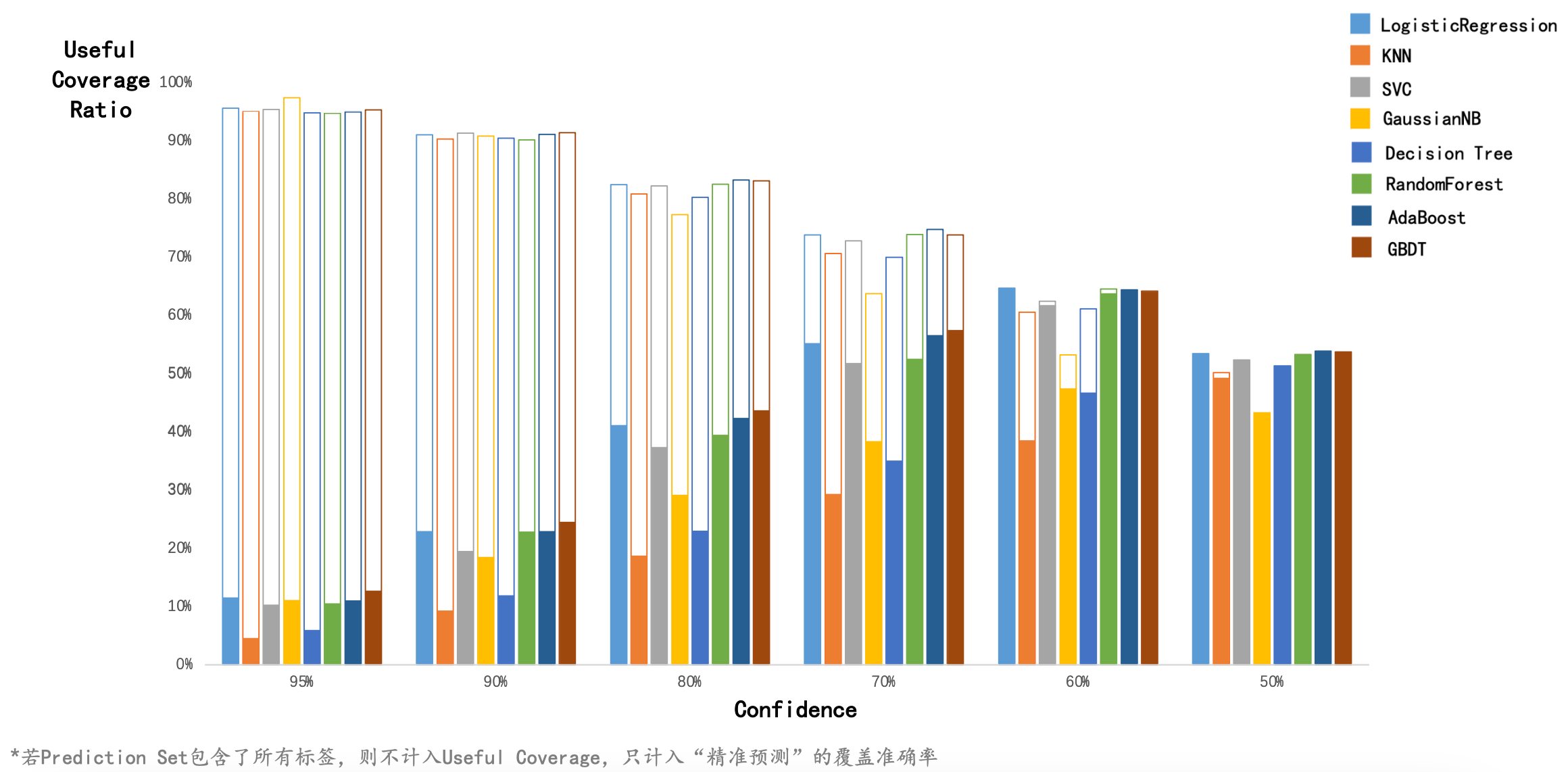
本项目的完整展示文件在这里。
Conformal Learning 是一种非参数统计方法,利用“样本属于某个标签时的离群程度”来进行回归和分类。本文分别使用“老忠实泉的爆发和等待时间数据”进行回归预测,使用“玻璃分类数据”进行多标签分类预测。
参考文献:A Tutorial on Conformal Prediction
回归问题
对于训练集的某一个样本 \(i\),找到离样本 \(i\) 最近的样本。
若最近的样本只有一个,记为样本 \(j\),则计算样本 \(i\) 和 样本 \(j\) 的标签之间的差值的绝对值;
若最近的样本有多个,则先计算这多个样本的标签的中位数,再将样本 \(i\) 的标签值与该中位数做差后取绝对值。
此“绝对值”就衡量了样本 \(i\) 的离群程度。
对于一个新样本 \(n\),同样找到离样本 \(n\) 最近的样本,用“离样本 \(n\) 最近的一个或多个样本的标签的中位数”作为新样本的标签预测值。
根据信心水平 \(level\)(例如 \(90\%\)),选定一个离群程度,使得该离群程度在所有训练样本的离群程度中的大小排名分位数是 \(1-level\)(例如 \(10\%\),即100个数中第10大的数)。
在该预测值的基础上加减上一步选定的离群程度,就得到新样本标签值的预测区间。
分类问题
本文使用 Benjamini-Hochberg Procedure 和 Adaptive z-value Procedure 进行多重假设检验,在实际数据上验证了后者的优势,并展示了估计原假设的分布参数的重要性。

在学习多重假设检验时,提到了“P 值是均匀分布的”这个结论。本文对“单边检验”和“双边检验”的情形,证明了 P 值是均匀分布的。
直觉理解
以单边左侧检验为例(单边检验最好理解,不用考虑两侧的情况),可以这样想:
P 值小于 \(0.25\) 意味着什么?意味着观测到的统计量要小于 \(0.25\) 分位数。
观测到的统计量小于 \(0.25\) 分位数的概率是多少?就是 \(0.25\)。
也就是说,P 值小于 \(0.25\) 的概率就是 \(0.25\)。
把 \(0.25\) 换成任何一个 \(0\) 到 \(1\) 之间的值,都可以得到:P 值小于某个数的概率就是这个数本身。这就是均匀分布。
本文使用 SCAD、LASSO、Ridge 和 Garrote 惩罚项对线性回归进行了建模,在模拟数据下验证了不同惩罚项设计的对稀疏系数的选择能力。
原始论文的标题叫做 Variable Selection via Nonconcave Penalized Likelihood and Its Oracle Properties。对于 Oracle Properties,在 统计之都上有一个非常精彩的解释:
Oracle 这个词对应的中文翻译叫做“神谕”,就是神的启示,它是指通过媒介(男女祭司或器物)传达神的难以捉摸或谜一般的启示或言语。在罚函数(比如 LASSO) 的研究领域,Oracle 指的是以下的渐进性质:
- 真值为 0 的参数的估计也为 0。
- 真值不为 0 的参数的估计值一致收敛到真值,并且协方差矩阵不受那些真值为 0 的参数估计的影响。
简而言之:罚函数的估计结果就好像事先已经得到了神的启示,知道哪些是真值为 0 的参数一样。
在使用最小二乘法估计线性模型的参数时,我们通常会将目标函数写成最小化均方误差的形式: $$ \hat\beta = \min_{\beta} \sum_{i=1}^n {\color{red}{(y_i - x_i^T \beta)^2}} $$
为什么我们要用 均方误差 作为损失函数?而不是绝对值误差、绝对值的三次方误差等其他形式?本文推导了极大似然估计与最小均方误差的等价性,说明最小均方误差是一种合理的做法。
高维协方差矩阵的一个重要特征就是许多维度之间的协方差非常接近于 0,一个自然的想法就是将矩阵中绝对值太小的元素设为 0,这种方法就是 Thresholding(门限):通过设定某个门限,将绝对值小于该门限的元素设为 0,只保留绝对值大于或等于该门限的元素。
通过 Thresholding 估计方法,我们可以得到一个比样本协方差矩阵更稀疏的估计。学术界提出了两种设置 Thresholding 的方法:Universal thresholding(统一截断)和 Adaptive thresholding(自适应截断)。前者对矩阵中的每一个元素均采用相同的门限标准,而后者基于样本协方差估计的标准误自适应地为每个元素设定门槛。
本文使用模拟的高斯分布数据和真实的高维 DNA 基因数据,比较了 Universal thresholding 和 Adaptive thresholding 的估计效果,所得结果与 Tony Cai & Weidong Liu (2011) 中的结果基本一致。

手动实现交叉验证的收获
在实现交叉验证时,要清楚一共有几个循环。每一个候选的超参数,都要在所有折上做训练和验证!
例如,一共有 10 个候选的超参数,进行 5 折交叉验证,那么需要对这 10 个超参数都训练、验证 5 次,一共训练、验证 50 次。
在编码的过程中,我最开始误将一个参数在一个折上做训练和验证,这样做并不能达到交叉验证的效果。
利用线性变换和雅可比矩阵,推导多元正态分布的线性变换的性质。
假设 1-4 可推出:普通最小二乘估计是最小方差线性无偏估计(BLUE)。
假设 1-3 与假设 5 可推出:普通最小二乘估计具有一致性。
假设 6 并不影响普通最小二乘估计是最小方差线性无偏估计,它是为了便于在有限样本下对回归系数进行统计检验。
本文计算了普通最小二乘估计的方差,并证明了高斯 - 马尔可夫定理。
普通最小二乘估计的方差:
高斯 - 马尔可夫定理(Gauss-Markov Theorem)
在线性回归模型中,如果线性模型满足高斯马尔可夫假定,则回归系数的最佳线性无偏估计(BLUE, Best Linear Unbiased Estimator)就是普通最小二乘法估计。
本文证明了普通最小二乘估计的无偏性和一致性。
无偏性:
一致性

本文推导了线性回归的普通最小二乘估计量的矩阵形式,并在一元线性回归的情境下给出了求和形式的表达式。 $$ Y=X \widehat{\beta}+e $$
在一元线性回归的情境下:
本文使用梯度下降法、随机梯度下降法、坐标下降法和基于贝叶斯后验的 MCMC 采样法实现带有 L1 惩罚项的逻辑回归,并在银行客户流失数据集上进行实证检验。

样本方差的分母是 n-1,这使得样本方差是总体方差的无偏估计。
pandas 默认的.var()方法计算的是样本方差,即自由度为\(N-1\)。若想计算总体方差,需指定参数ddof=0(1)。
ddof时,计算方差的分母为N-ddof。总结
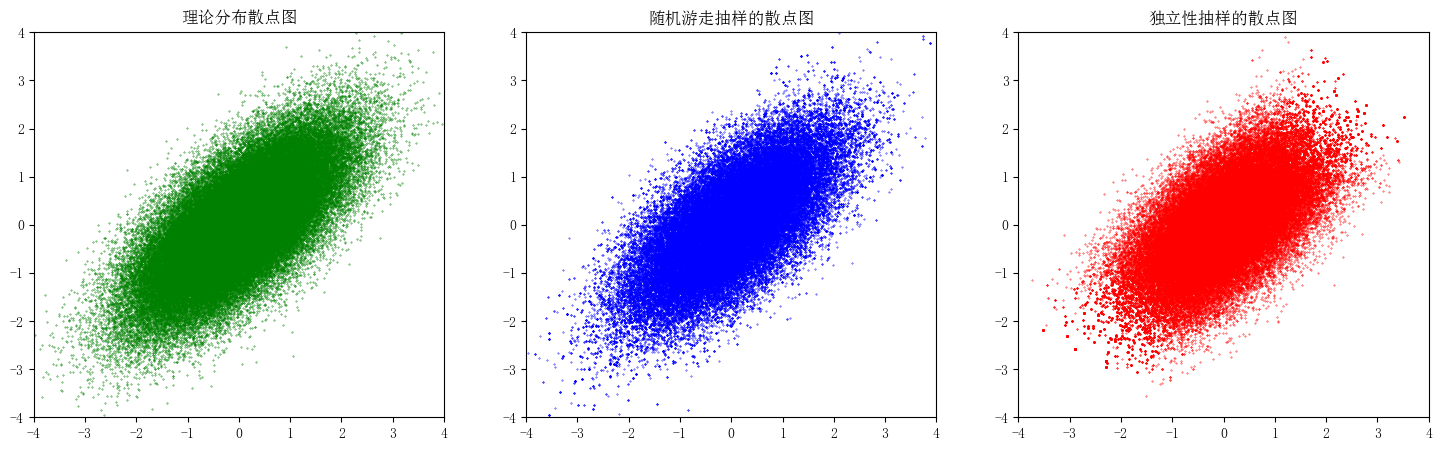
var()默认的自由度是 n-1,即var(ddof=1);var()默认的自由度是 n,即var(ddof=0);var(ddof=0)相当于 NumPy 中的 var()。MCMC 算法是一种随机抽样算法。借助建议分布,可以在各个样本状态之间进行转移,最终得到目标分布的样本。本文使用了逐分量 MCMC、随机游走和独立性抽样构造 Ising 分布和二元正态分布的随机样本。
应用重期望公式,证明方差分解公式。 $$ \operatorname{Var}(X)=\operatorname{Var}(\mathrm{E}[X \mid Y])+\mathrm{E}[\operatorname{Var}(X \mid Y)] $$
使用条件期望法降低蒙特卡洛模拟得到的估计量的方差。
Box-Muller 变换是一种采样方法,它通过服从均匀分布的随机变量,来构建服从高斯分布的样本。
基于 EM 算法,推导多元高斯混合模型聚类的参数迭代公式,并使用 Python 对数据集进行聚类和各类别的参数求解。
在编写代码的过程中,遇到了一个非常简单但一直没发现的 Bug。
定义数组用
all_density = np.array([0]*K),再用all_density[k] = k_density并不会让all_density的第k个元素改变。这是因为all_density是介于 0 到 1 之间的,而在定义all_density的时候没有指定数组内部的数据类型,默认是不支持小数的,因此赋值之后all_density的第k个元素仍然是 0。解决方法:定义数组的时候一定要指定元素的数据类型,指定为
dtype=flout64就可以存储高精度的浮点数。

使用 Lagrangian 乘子法、投影梯度算法、罚函数法求解有约束的优化问题。

用数值近似法求函数在某点的梯度,用回溯线搜索法控制步长,应用梯度下降法求函数极值。
梯度下降的思想是:对某一初始值,不断改变这一初始值,且每一步都朝着能使函数值减小的方向改变,最终函数值几乎不再变小,我们就认为达到了极小值点。