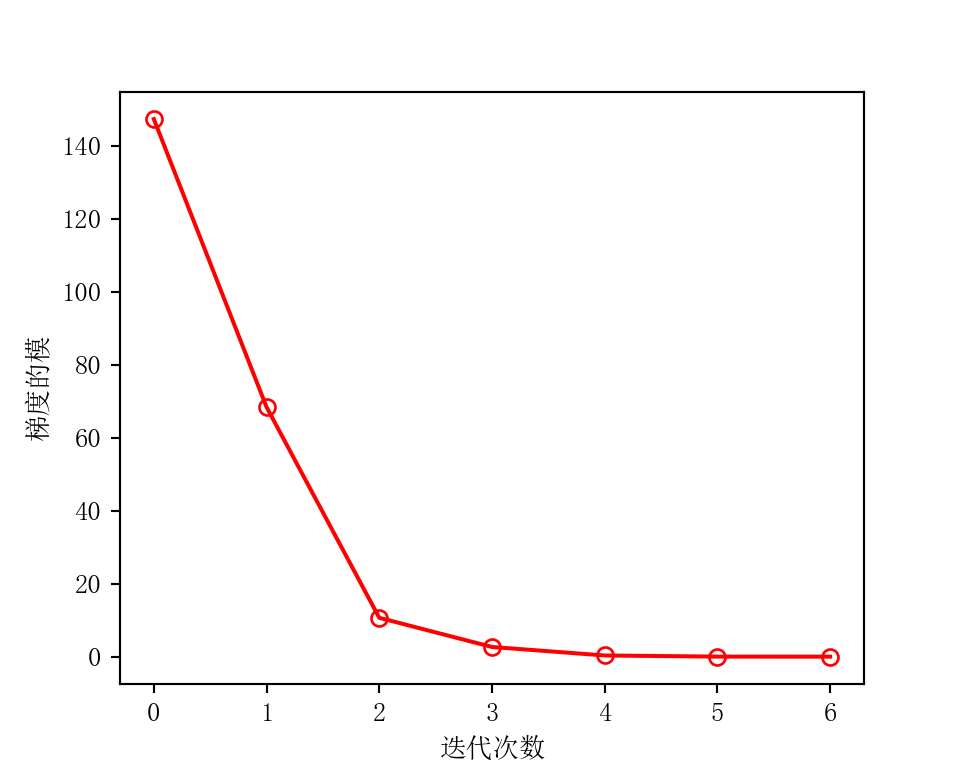
使用 Conformal Learning 预测企业信贷违约情况
本文使用 8 种经典的分类器,基于逆概率错误进行 Conformal Learning。
本文使用了 nonconformist 包,它在使用 Conformal Learning 进行分类预测时的核心步骤是:
- 在训练集上训练,这一步和常规的机器学习训练相同。
- 在校准集上校准,得到每个校准集样本属于每个标签的预测概率。
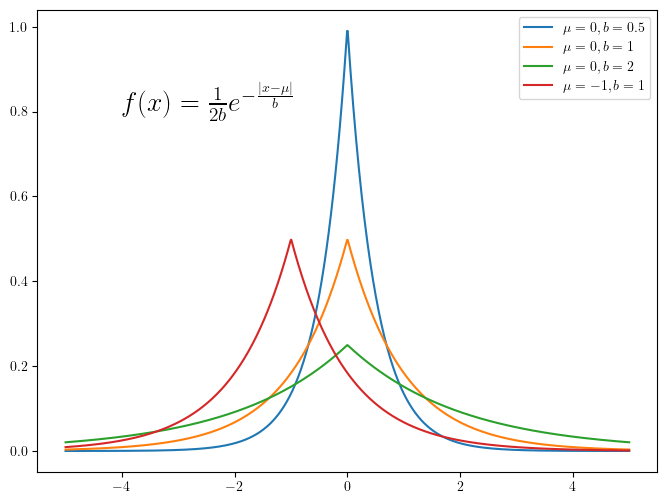
- 用一个 ErrFunc 衡量每个校准集样本的预测效果,作为 nonconformity score。最简单的是
InverseProbabilityErrFunc,它等于1-predict_probability[true_y]。例如,某个样本的真实标签是 1,而模型预测出该样本属于标签 1 的概率是 0.9,则 ErrFunc 的值是 1-0.9=0.1。 - 在测试集上测试,得到每个测试集样本属于每个标签的预测概率。
- 用 ErrFunc 衡量每个测试集样本的预测效果。
- 对每一个测试集样本,计算:有多少比例的校准集样本的 nonconformity score 大于或等于当前测试样本的 nonconformity score,记为 p。p 越大,说明校准集中有非常多的样本比当前测试集样本的预测效果更差,说明第 j 个测试样本属于第 i 个类的可能性越大。
- 返回 p > significance。得到一个 N*2 的 True 和 False 组成的二维矩阵,每一行代表一个测试集样本,每一列代表是否将该标签纳入该样本的 prediction set 中。
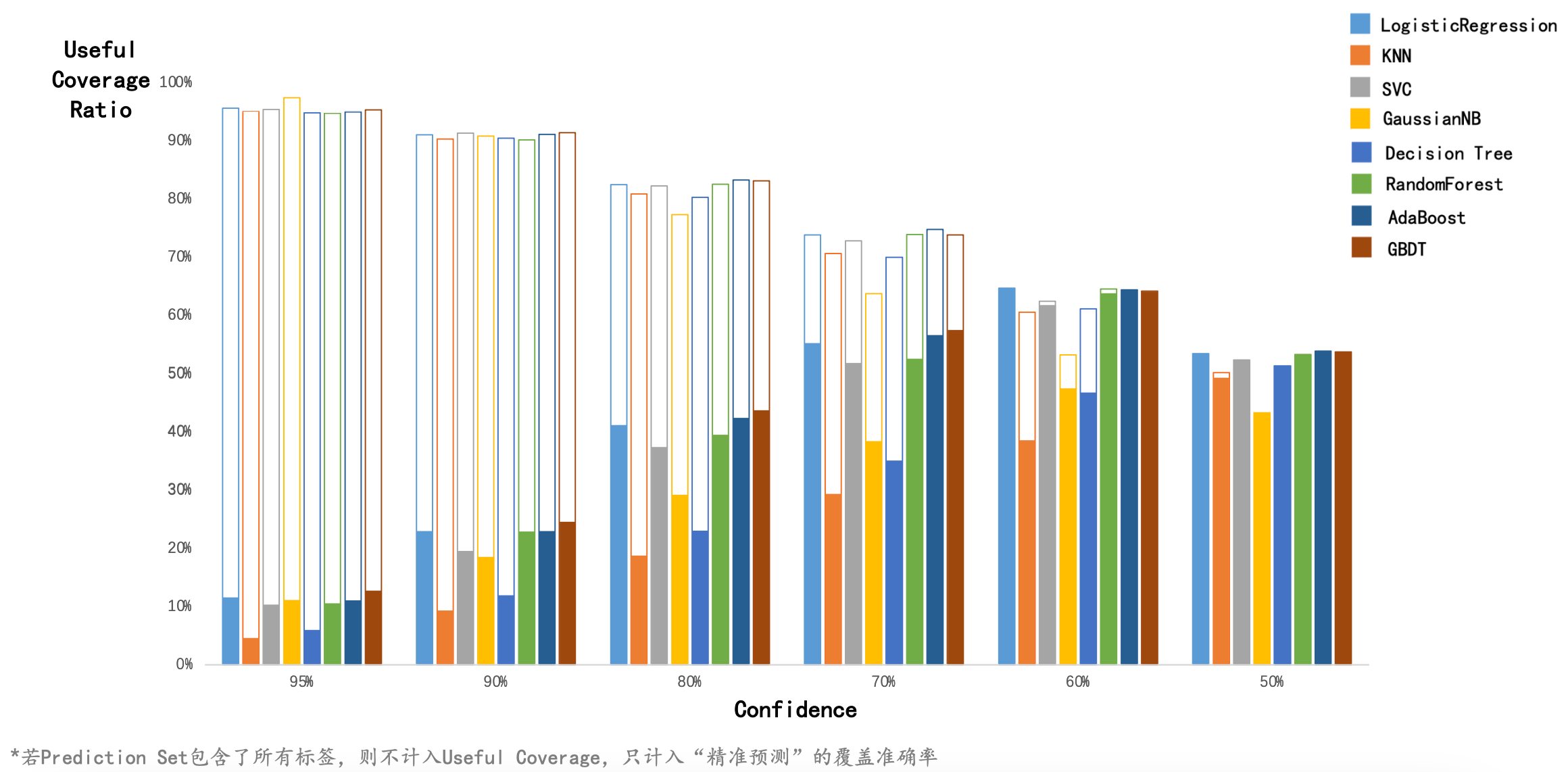
本项目的完整展示文件在这里。