Others 其他¶
Dict 字典¶
保存字典到 JSON 文件¶
从 JSON 文件加载字典¶
对dict按value进行排序(由小到大):¶
对字典进行切片¶
参考:https://stackoverflow.com/a/66535220/16760102
对某个 key 的 value 加 1,若不存在这个 key 则先将这个 key 设为 0 再加 1¶
参考:https://stackoverflow.com/a/2626102/16760102
.get() 的参数:
| Parameter | Description |
|---|---|
| keyname | Required. The keyname of the item you want to return the value from |
| value | Optional. A value to return if the specified key does not exist. Default value None |
将 list 转换为 dict,其中 key 为 list 中的元素,value 为元素在 list 中的索引¶
将两个列表转为字典¶
keys = ["a", "b", "c"]
values = [1, 2, 3]
dictionary = dict(zip(keys, values))
print(dictionary) # {'a': 1, 'b': 2, 'c': 3}
参考:https://stackoverflow.com/a/209854/
统计 list 中各元素出现的次数,并以 dict 形式返回¶
import collections
my_list = [2, 0, 0, 1, 0, 7, 2, 2]
count_dict = collections.Counter(my_list)
# count_dict
# Counter({2: 3, 0: 3, 1: 1, 7: 1})
将 Python 中的字典保存到本地的 JSON 文件中¶
import json
# 定义一个字典
data = {
'name': 'John',
'age': 30,
'city': 'New York'
}
# 将字典保存到 JSON 文件
with open('data.json', 'w') as f:
json.dump(data, f, indent=4) # 使用 indent 参数格式化输出,使 JSON 文件更易读
Set 集合¶
add() 和 update() 向集合中添加元素¶
在 Python 的 set 中,.add() 和 .update() 都是向集合中添加元素的方法,但是它们的参数和操作方式有所不同。
.add() 方法是将单个元素添加到集合中。如果添加的元素已经存在于集合中,则不会重复添加。例如:
myset = {"apple", "banana", "cherry"}
myset.add("orange")
print(myset)
# Output: {'banana', 'cherry', 'apple', 'orange'}
myset.add("apple")
print(myset)
# Output: {'banana', 'cherry', 'apple', 'orange'}
.update() 方法可以用于向集合添加多个元素,它的参数可以是列表、元组、集合或其他可迭代对象,这些元素会和原有的元素合并为一个集合。例如:
myset = {"apple", "banana", "cherry"}
myset.update(["orange", "grape"])
print(myset)
# Output: {'banana', 'cherry', 'grape', 'orange', 'apple'}
可以注意到,.update() 方法可以一次性添加多个元素到集合中,如果添加的元素已经存在于集合中,则不会重复添加。需要注意的是,使用元素作为参数调用 .update() 方法时,元素将被迭代并添加到集合中,因此,如果传递的元素本身是集合,则其将被分解并单独添加到结果集中,而不是将整个集合添加为一个元素。
总之,.add() 方法适用于单个元素的添加,而 .update() 方法适用于向集合中添加多个元素。
String 字符串¶
求某个字符的 ASCII 值¶
将某个字符的 ASCII 值转换为字符¶
判断某个字符串是否以某个子字符串开头或结尾¶
f{} 指定字符串格式¶
若 test 是 0.1,则会打印 10%。

对字符串左边填充 0¶
适合填充股票代码。
VS Code¶
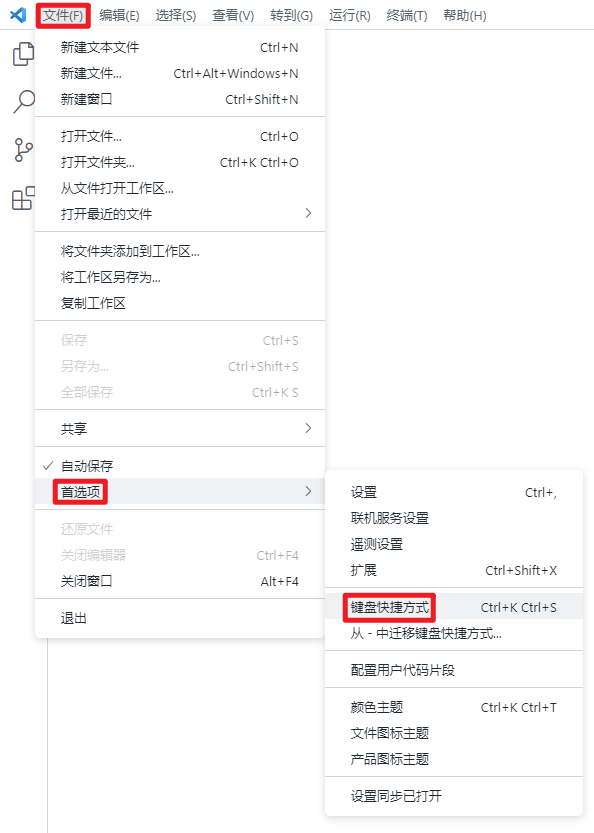
修改 VS Code 键盘快捷键¶
文件 → 首选项 → 键盘快捷方式
或者用快捷键Ctrl+K+S 呼出。
VS Code 滚动界面时保持父级嵌套(如类名和函数名)显示在顶部¶

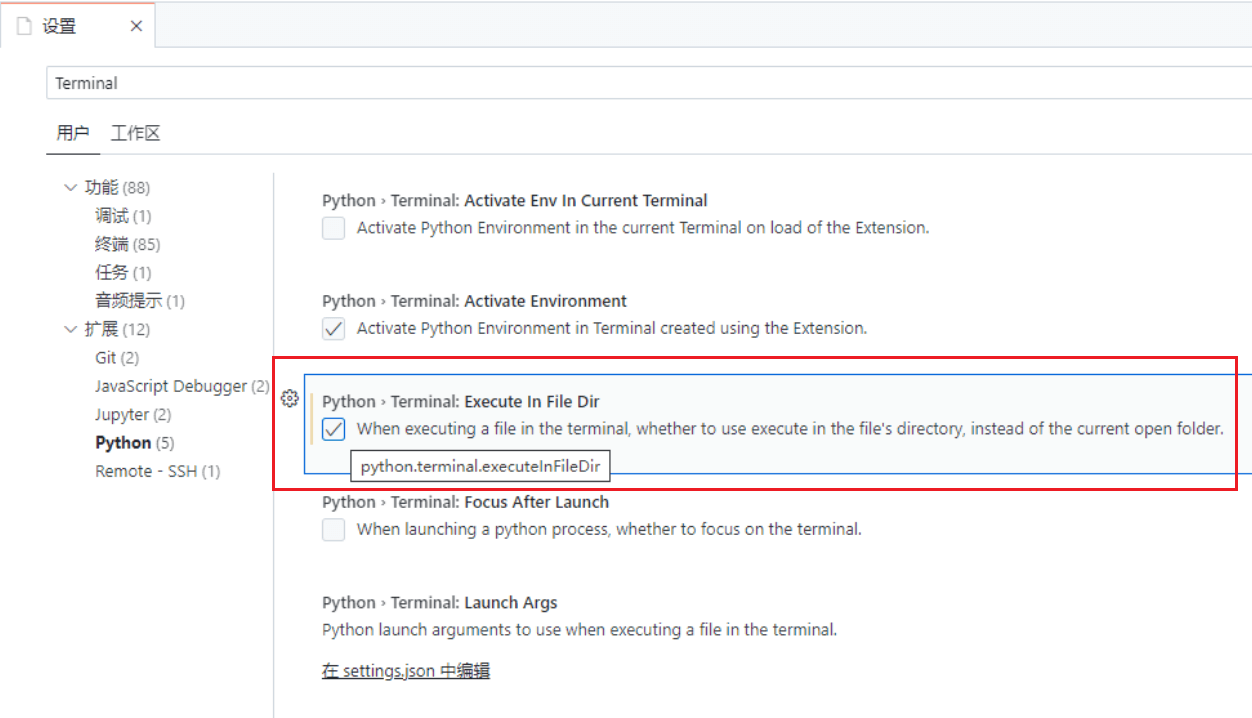
VS Code 运行 Python 脚本时,在当前脚本文件的路径执行终端命令¶
一些相对路径总是不能很好地被识别,这是一个很困扰的问题。勾选下图后就可以在当前脚本文件的路径执行终端命令,而不是在打开的文件夹路径执行。
VS Code 中 Python 无法跳转到函数定义¶
将 Python: Language Server 设成 Jedi。
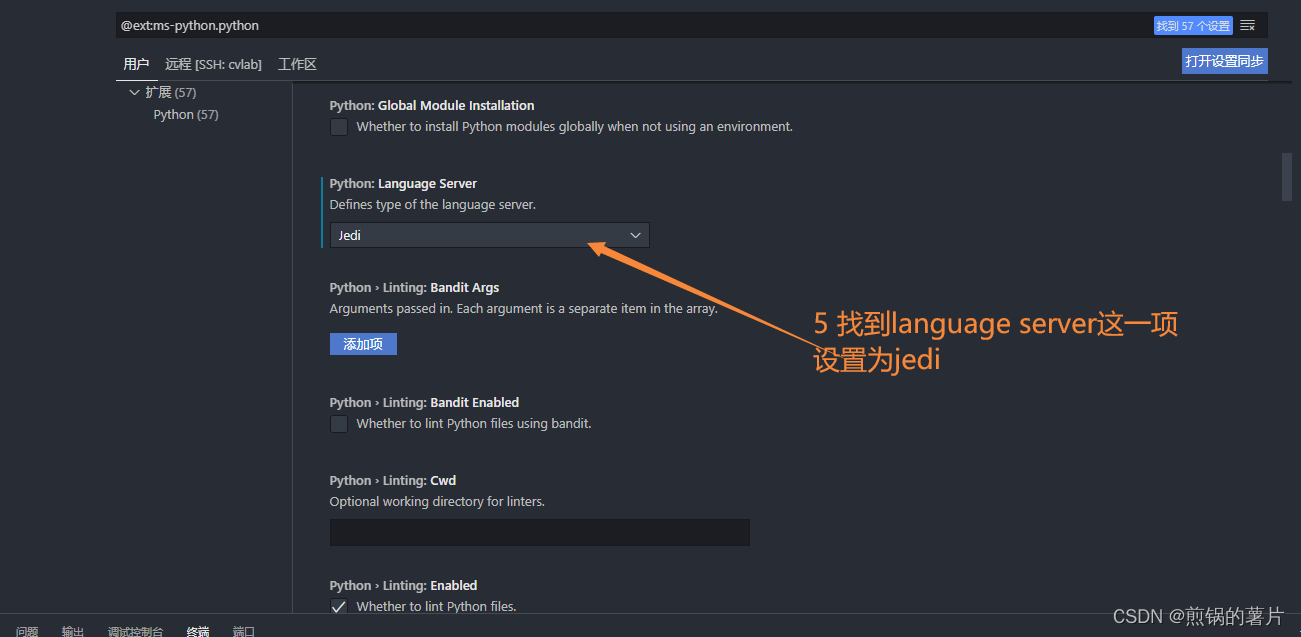
参考 https://blog.csdn.net/singxsy/article/details/123730161
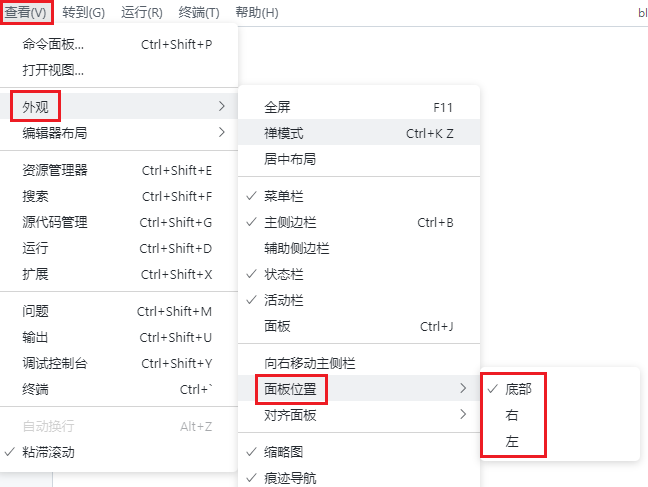
修改 VS Code 终端显示的布局(居右显示 or 底部显示)¶
一键折叠或展开代码¶
一键折叠所有代码:Ctrl+K+0
一键折叠所有代码:Ctrl+K+J
只折叠当前区域的代码:Ctrl+Shift+[
只展开当前区域的代码:Ctrl+Shift+]
调试代码时,包括引入的库代码¶
默认的调试模式是“Just my code”,也就是只有在自己编写的代码打的断点才有效。如果需要调试引入的库代码,可以在设置中将“Debug Just My Code”取消勾选。

Regular Expression 正则表达式¶
替换匹配的文本¶
参考:¶
https://www.dongchuanmin.com/archives/471.html
替换前的内容:
需要在 static 目录后面再加一个 css 目录。
打开 VS Code,然后 Ctrl+F,把搜索功能调出来,点击下查找框左边向下展开的箭头,把替换框也展现出来。
点击查找框后面的第三个按钮,如下图,表示启用正则表达式匹配,你会看到文档中被成功匹配的内容被标色了,然后再点击批量替换就可以了。

从上面的代码可以看出,(.) 表示了斜杠和标点之间所有的内容,$1 代表了上面 (.) 匹配出的值。
现在有一个新需求,就是把一篇文章里的 A 标签全部删掉,但是要保留 A 标签里的关键词。整理下文章里所有 A 标签的案例,如下:
<a href="http://www.xxoo.com">关键词一</a>
<a href="http://www.xxoo.com" title="xxoo">关键词二</a>
<a href="http://www.xxoo.com" target="_blank">关键词三</a>
在查找框输入:<a href="(.*)>(.*)</a>
在替换框输入:$2
批量替换即可。从上面按钮可以看到,查找用了 2 个 (.*) 分别匹配 2 个值,然后替换时,$2 表示保留第二个值。
有时候(.*)不能精确匹配出想要的结果,可能跟开启了贪婪模式有关,此时可以改用:([^//]*)
Nginx¶
运行 Nginx¶
查看正在运行的 Nginx 进程¶
通过默认http://127.0.0.1访问 8050 端口¶
将 nginx.conf 中的 server 改为:
# 代理本机 8050 端口
server {
listen 80;
location / {
proxy_pass http://127.0.0.1:8050; # 应用服务器 HTTP 地址
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
参考:https://blog.csdn.net/jackuhan/article/details/78796205
平滑退出所有 Nginx 进程¶
强制立即停止 Nginx 命令¶
两种退出方法的区别
这两个命令都是用来停止 Nginx 服务器的,但是存在一些区别:
nginx -s quit 命令是向 Nginx 主进程发送一个信号,告诉它优雅地关闭并停止。
具体来说,这个命令会让 Nginx 在处理完当前所有的请求之后再停止,确保所有正在进行的连接都正常关闭。这种方式的好处是可以确保服务器关闭的平滑,避免由于未处理完的连接导致数据丢失等问题。
nginx -s stop 命令也是停止 Nginx 服务器,但是它会直接杀死主进程,不会优雅地关闭。
这种方式的好处是可以立即停止服务器,但是也可能会导致正在进行的连接出现异常,造成数据丢失等问题。
因此,在正常情况下,推荐使用 nginx -s quit 命令来关闭 Nginx 服务器,只在需要立即停止服务器的时候使用 nginx -s stop 命令。
重启 Nginx¶
nginx -s reload (热重载):Nginx 服务不会终止,使用主进程检查配置,如果配置文件语法正确,则主进程会启动一个新的工作进程处理新来的请求。主进程发送消息给原来的工作进程,通知旧的进程不在接受请求,处理完现有的请求后退出(优雅退出);如果语法不正确,则继续使用旧的进程继续处理请求。
安装 SSL 证书¶
注意下载对应服务器的证书文件,不要下载错了!
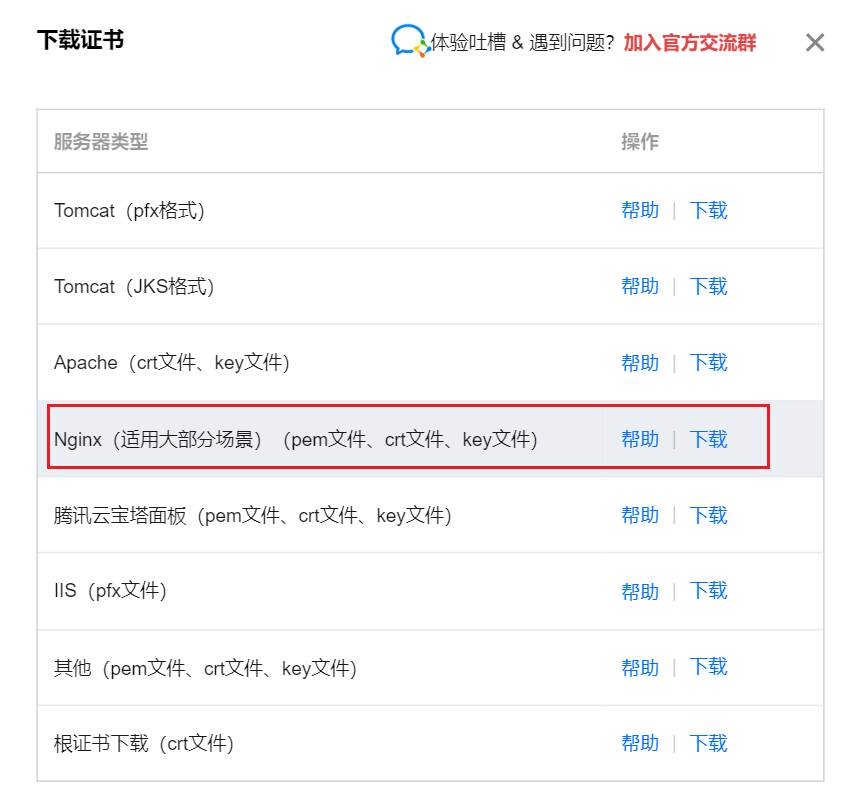
参考:https://cloud.tencent.com/document/product/1207/47027
其他¶
在jupyter notebook中重新导入模块¶
最推荐的方法:
若functions中的代码有更改并保存,那么在调用functions中的函数时会自动用新的函数,甚至不需要手动再运行from functions import *这段代码了,非常方便。
参考:https://ipython.org/ipython-doc/3/config/extensions/autoreload.html
另一种方法:
如果只是用from functions import *,那么当functions.py文件中的内容改动后,jupyter notebook觉得之前已经导入过functions.py了,因此并不会识别出functions.py更新的内容。
如果使用这种方法,当functions中的代码有更改并保存时,需要再次运行上面的代码片段才能够更新functions中的函数。
导入指定文件夹下的模块¶
情况 1:需要导入的模块位于上一级目录中¶
例如,有下面的目录结构:
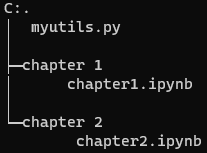
情况 2:需要导入的模块位于上一级目录的子目录中¶
例如,有下面的目录结构:
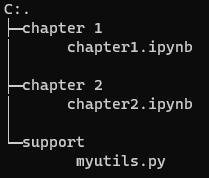
我需要在 chapter1.ipynb 和 chapter2.ipynb 中都能导入 support/myutils.py,可以在chapter1.ipynb 和 chapter2.ipynb 中写入:
import os
import sys
sys.path.insert(0, os.path.abspath("../"))
import support.myutils as myutils
这里的sys.path.insert(0, os.path.abspath('../'))将../添加到系统路径中。
自定义模块带有多个文件时,交叉导入¶
在 Python 中使用相对导入语法 from .module_name import class_name 时,如果出现 "ImportError: attempted relative import with no known parent package" 异常,通常是由于 Python 无法确定当前模块的父包所在位置而引起的。此时,可以通过以下方式解决该问题:
将当前模块作为包中的一个模块来处理,即在该目录下创建一个 __init__.py 文件。__init__.py 文件可以是一个空文件,或者包含一些初始化代码的 Python 模块。如果你不需要进行任何初始化操作,则可以保持该文件为空。如果需要进行初始化操作,则可以在该文件中添加相应代码。
记录代码的运行时间¶
修改 VS Code 运行 Python 的路径为当前脚本所在路径¶
GitLens 插件禁止在行内显示信息¶
将设置中的 gitlens.currentLine.enabled 取消勾选。

如果某个包不存在,则安装它¶
import importlib
try:
importlib.import_module('library_name')
print('Library exists.')
except ImportError:
!pip install library_name
print('Library installed.')
以上代码中,'library_name'需要用实际库名替换。如果库已经存在,则输出'Library exists.',否则将使用!pip install 命令进行安装,并输出'Library installed.'。
修改pip install的默认镜像¶
会覆盖如下配置文件:
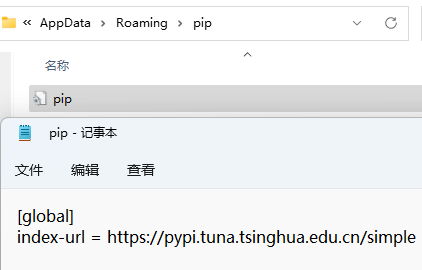
临时修改安装源¶
可以通过在命令行中使用-i参数来指定默认源。例如:
pip展示已安装包的信息¶
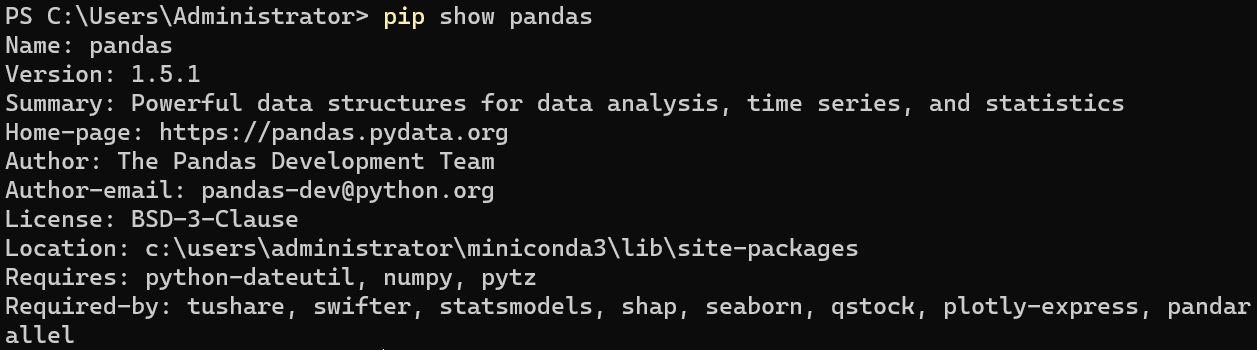
更新包¶
从 requirements.txt 中安装包¶
遍历文件夹¶
for dirname, _, filenames in os.walk("./folder/"):
for filename in filenames:
print(os.path.join(dirname, filename))
assert 检查表达式是否符合预期¶
若表达式不符合预期,可以报错提示用户需要检查。
pdb 调试代码¶

查看导入外部包的文件路径¶
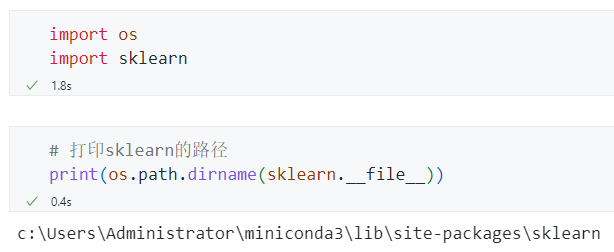
仅当作为主文件时运行¶
复制、移动文件¶
import shutil
# 复制文件到新的路径,可同时修改文件名
shutil.copy("oldname", "renamedfiles/newname")
# 移动文件到新的路径,可同时修改文件名
shutil.move("oldname", "renamedfiles/newname")
参考:https://stackoverflow.com/a/42542180/16760102
新建文件夹,若存在则不新建¶
命令行切换到 D 盘¶
直接输入
声明编码格式¶
告诉编程语言解释器编码格式为 UTF-8,以便正确解析和处理文本数据。UTF-8 是一种通用的编码标准,它支持多种语言字符集,如英语、中文、日语、阿拉伯语等。如果不指定编码格式,可能会导致文本处理错误,如无法正确显示字符、无法读取或写入文件等。
查看电池信息¶
报错后记将值写入到文本文件¶
在 except 语句块中,我们打开文本文件并把 'bar' 添加到最后一行。如果文本文件不存在,则创建一个新的文件。
try:
foo = func("bar")
except:
with open("error_log.txt", mode="a") as f:
f.write("bar" + "\n")
注意,这里的 with open 语句中用到的参数 a 表示向文本文件中追加内容,如果文件不存在,则创建一个新文件。write() 方法添加新的字符串时,在字符串的末尾添加 \n,这样可以确保每一行文本的末尾都有一个换行符。
禁用 homebrew 自动更新¶
若每次 brew install 时都自动执行 brew update --auto-update,可以禁用掉每次安装前的更新:
需要更新包了,可以执行:
brew update && brew upgrade && brew cleanup ; say mission complete
brew update && brew upgrade brew-cask && brew cleanup ; say mission complete
参考:https://learnku.com/articles/18908#reply100531
通过命令行查看 ip 地址¶
网页端查看:
使用 pandoc 转换文件¶
要将 .r 文件转换为 markdown 文件,需要执行以下步骤:
- 在终端中安装 pandoc,如果已经安装可以跳过此步骤。
- 在终端中使用 pandoc 从 .r 文件生成 markdown 文件:
其中,example.R 是你要转换的 .r 文件的文件名,example.md 是输出文件的文件名。这个命令将会把 example.R 文件转换为 example.md 文件。
- 你现在可以在终端中使用 cat 命令查看生成的 markdown 文件:
这个命令将会在终端中输出 example.md 文件的内容。
argparse 接收命令行参数¶
以下是一个简单的示例代码,使用 argparse 模块处理命令行参数:
import argparse
parser = argparse.ArgumentParser(description="命令行参数示例程序")
# 添加位置参数
parser.add_argument("name", metavar="NAME", help="名字")
parser.add_argument("age", type=int, metavar="AGE", help="年龄")
# 添加可选参数
parser.add_argument(
"-s", "--sex", choices=["male", "female"], default="male", help="性别"
)
parser.add_argument("-p", "--password", required=True, help="密码")
args = parser.parse_args()
print("名字:", args.name)
print("年龄:", args.age)
print("性别:", args.sex)
print("密码:", args.password)
该程序接收四个命令行参数:
- 位置参数
name:名字,必需的 - 位置参数
age:年龄,必需的 - 可选参数
--sex或-s:性别,选择性的,默认值为male - 可选参数
--password或-p:密码,必需的
可以通过运行以下命令来运行程序:
输出结果如下:
在 Jupyter Notebook 中使用时需要注意
如果将上述代码放在 Jupyter Notebook 中执行,在执行 args = parser.parse_args() 时会报错:error: unrecognized arguments: --ip=127.0.0.1 --stdin=9008 --control=9006 --hb=9005 ...
我们可以用
就可以避免报错了。
参考:
如果默认参数是一个列表,例如有两个参数:
那么可以将两个参数分别用单引号扩起来,两个参数之间用空格间隔开(注意,不需要加方括号和逗号):
打印出对象实例的所有属性¶
可以使用内置函数 dir() 来获取一个对象的所有属性名称,然后通过 getattr() 函数可以获取对象的每个属性的值,最后将属性名称和属性值打印即可。
示例代码:
class MyClass:
def __init__(self):
self.a = "hello"
self.b = 123
self.c = [1, 2, 3]
my_instance = MyClass()
for attr_name in dir(my_instance):
value = getattr(my_instance, attr_name)
print(attr_name, ":", value)
注意,在 dir() 获取对象的所有属性名称时,还会包括一些特殊方法和属性,比如__class__、__dict__等,这些属性并不是我们在类中定义的属性,但也可以通过 getattr() 函数获取它们的值。
如果不需要以两个下划线开头的特殊方法,可以使用内置函数callable()来判断属性值是否可调用 (callable)。如果属性值可调用,就不要打印它。下面是一个示例代码:
class MyClass:
def __init__(self):
self.prop1 = "foo"
self._prop2 = "bar"
self.__prop3 = "baz"
def method1(self):
return "method 1"
def _method2(self):
return "method 2"
def __method3(self):
return "method 3"
my_instance = MyClass()
for attr_name in dir(my_instance):
if not attr_name.startswith("__"):
attr_value = getattr(my_instance, attr_name)
if not callable(attr_value):
print(attr_name, ":", attr_value)
这样就可以只打印除了以双下划线开头的特殊属性以外的所有属性名称和对应的值了。
代码计时¶
import time
start_time = time.time()
for i in range(10000):
pass
end_time = time.time()
elapsed_time = end_time - start_time
print(elapsed_time)
将 import 语句进行排序¶
在命令行中使用:
仅查看 isort 将做出的变更,但并不应用:
适用于 .py 脚本,不适用于 .ipynb 文件。
参考:https://muzing.top/posts/38b1b99e/
在终端中检索文本¶
-
-r表示递归搜索。该参数使grep在指定的目录及其子目录中递归搜索文件。 -
-n表示显示行号。该参数使grep在输出结果中显示匹配行的行号。 -
--include参数用于指定要搜索的文件的模式或模式列表。它允许你限制搜索只在符合指定模式的文件中进行。
在终端中运行 .ipynb 文件¶
方法一:
方法二: