计算部分相关系数矩阵¶
本文使用相关系数的矩阵表达形式,实现了计算部分相关系数矩阵的加速算法,并实证检验了三种计算相关系数矩阵方法的运行速度。
- 在计算部分相关系数矩阵时,自定义的加速算法 相比 Pandas
.corr()方法提速约 2180 倍,比 Numpy.corrcoef()方法提速约 115 倍。 - 在计算全部相关系数矩阵时,Numpy
.corrcoef()方法比自定义的加速算法略快 \(10\%\),比 Pandas.corr()方法快约 20 倍。
问题描述¶
我们需要计算若干列的相关系数矩阵的一部分。例如,原始数据有 10000 列、100 行,如果直接对这 10000 列数据计算相关系数矩阵,那么会得到一个 \(10000 \times 10000\) 的矩阵,但我们只需要计算某 10 列与其他列的相关系数,那么我们只需要得到 \(10000 \times 10\) 的矩阵即可。
第一种方法是,先计算出 \(10000 \times 10000\) 的矩阵(这用 Pandas 的 .corr() 很容易实现),然后再取出我们需要的 \(10000 \times 10\) 的矩阵。但这样做的问题是,计算出的 \(10000 \times 10000\) 的矩阵的运算量非常大,这其中有很多值是我们不需要的,因此计算速度很慢。虽然 Numpy 中的 .corrcoef() 的计算速度比 Pandas 中的 .corr() 快很多,但是它仍然进行了很多不必要的运算。
第二种方法是,从相关系数的矩阵表达形式进行推导,手动用向量化运算得到我们需要的 10000x10 的矩阵。它的结果保证准确,且不会进行不必要的计算。
生成数据¶
本例中,我们生成一个 100 * 10000 的 Pandas 数据框,用于比较各种计算协方差矩阵方法的速度。

使用不同方法计算相关系数矩阵¶
使用 Pandas 的 .corr() 方法计算相关系数矩阵¶

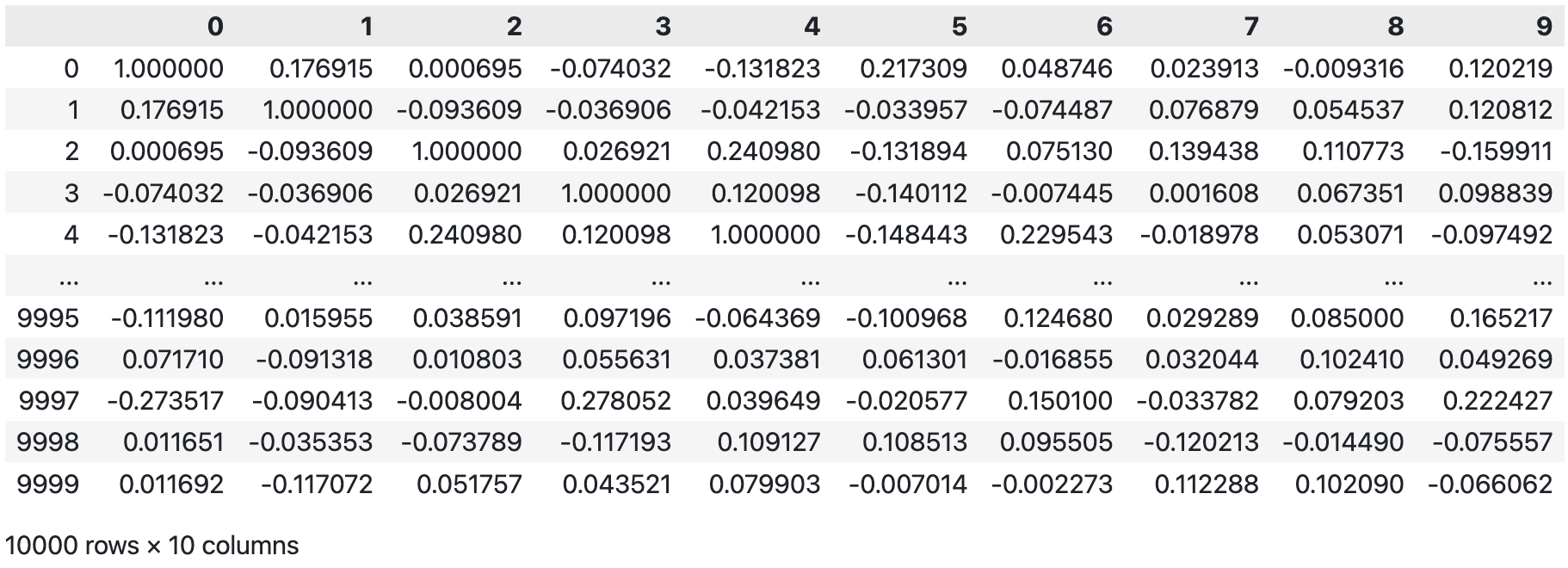
如果我们只需要得到某 10 列与其他列的相关系数矩阵,那么我们只需要取出相关系数矩阵中的这 10 列即可。
使用 Numpy 的 .corrcoef() 方法计算相关系数矩阵¶
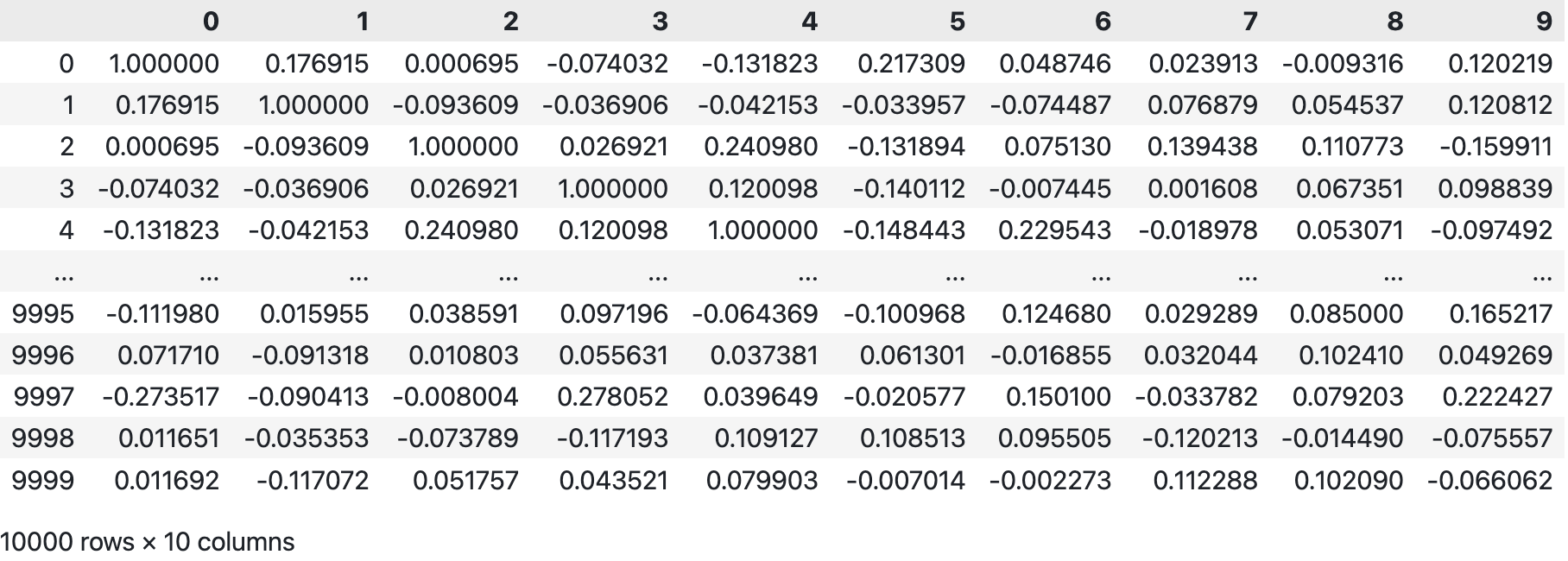
Numpy 的 .corrcoef() 方法的调用中,需要注意将 rowvar 参数设置为 False,表示每一列为一个变量,每一行为一个观测值。
使用矩阵表达式计算相关系数矩阵¶
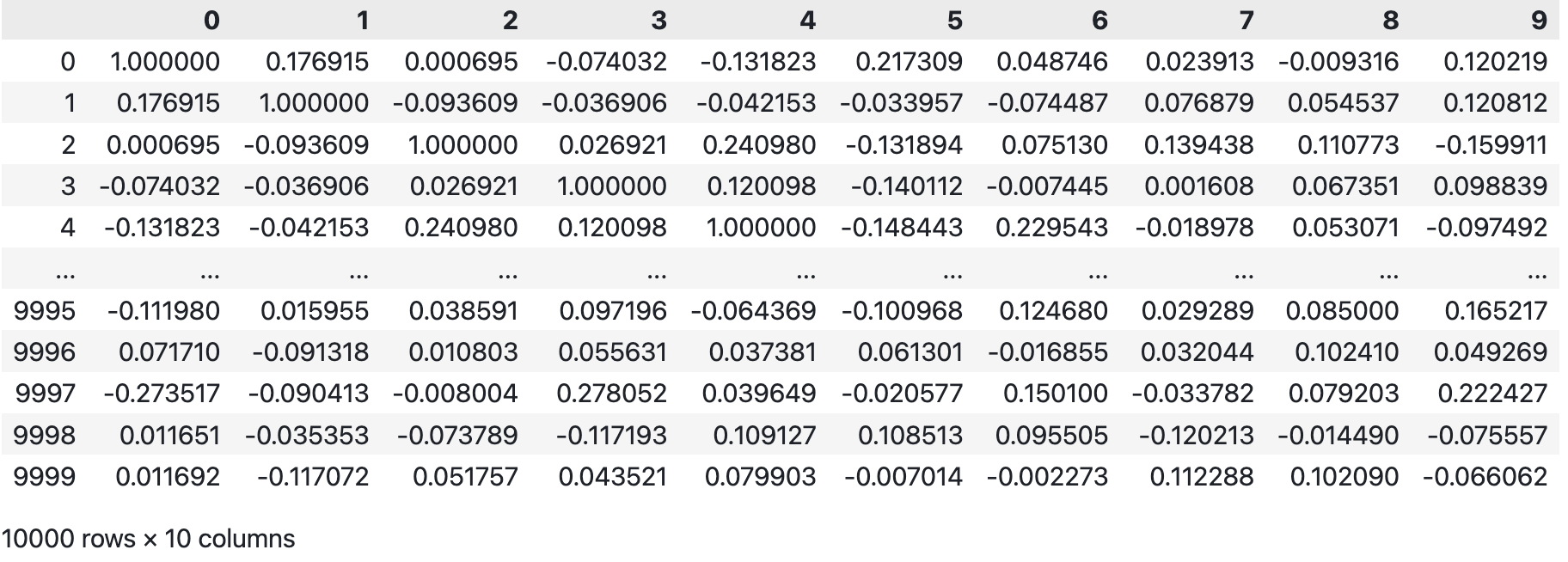
相关系数的矩阵表达形式的数学原理,可以参考 Quickest way to calculate subset of correlation matrix - stackoverflow。

def cal_corr(x, select_cols):
n = x.shape[0]
xsum = np.sum(x, 0, keepdims=True)
xstd = np.std(x, 0, keepdims=True)
return (
np.dot(x.T, x[:, select_cols]) - np.dot(xsum.T, xsum[:, select_cols]) / n
) / (np.dot(xstd.T, xstd[:, select_cols]) * n)
检验各方法计算结果的一致性¶
True
True
比较各方法的计算速度¶
若只需要计算某 10 列与其他列的相关系数,那么:
- 使用矩阵表达式的方法的计算速度最快,因为它不会进行不必要的计算。
- 其次是 Numpy 的
.corrcoef()方法。 - 最慢的是 Pandas 的
.corr()方法。
10.9 s ± 85.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
587 ms ± 22.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
5.08 ms ± 334 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
若需要计算所有列之间的相关系数,那么:
- Numpy 的
.corrcoef()方法的计算速度最快。 - 其次是矩阵表达式的方法。
- 最慢的是 Pandas 的
.corr()方法。
11 s ± 92.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
576 ms ± 14.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
674 ms ± 50.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)