对抗过拟合:时间序列数据的交叉验证¶
时序交叉验证可以避免用到未来信息,更加适合用于检验时序数据的过拟合问题。
本文以华泰金工研究所发表的 《华泰人工智能系列之十四——对抗过拟合:从时序交叉验证谈起》 作为资料,学习时序交叉验证的思路与实证结果。
交叉验证是选择模型最优超参数的重要步骤。在我的本科毕业论文中,使用了随机森林回归对资产的收益率进行预测,其中的训练集和验证集是“随机 7: 3 划分”的。值得反思的是,资产的量价数据具有很强的时间序列属性,基本不符合“独立同分布”的假设。因此,使用常规的交叉验证方法很可能会将未来数据划入训练集、将历史数据划入验证集,即用未来预测历史的“作弊”行为。
防范过拟合的主要方法¶
对人工智能及机器学习的广泛诟病之一在于过拟合:模型通常能完美地拟合样本内数据,但是对样本外数据集的泛化能力较弱。目前防范过拟合的方法主要有:
- 增加样本数量;
- 损失函数中正则化项;
- 树模型的剪枝;
- 交叉验证确定超参数。
模型的参数和超参数¶
我们通常说的“调参”,实际上指的是“调整超参数”。关于“参数”和“超参数”的区别如下:
参数是模型的内部变量,是模型通过学习可以确定的参数。以简单的一元线性回归模型\(y =kx + b\)为例,斜率\(k\)和截距 \(b\)是该模型的参数。支持向量机模型的支持向量,神经网络模型的神经元连接权值都是模型的参数。对于决策树类的模型而言,每一步分裂的规则也属于模型参数的范畴。
超参数是模型的外部变量,是使用者用来确定模型的参数。假设我们希望采用回归模型对一组自变量 x 和因变量 y 进行拟合,究竟使用线性(一次)模型\(y = kx + b\)、二次模型\(y =k_1 x^2 + k_2 x + b\)、三次模型\(y = k_1x^3 + k_2x^2 + k3x + b\)或者更高次的回归模型,这里的多项式次数就是模型的超参数。下图展示了对回归模型中参数和超参数的辨析。

常见的模型超参数有:支持向量机模型中核函数类型、惩罚系数等,随机森林模型的树棵数、最大特征数、剪枝参数等,XGBoost 模型的学习率、最大树深度、行采样比例等、神经网络模型的网络层数、神经元个数、激活函数类型等。
模型的参数可以从训练集学习到,模型的超参数无法从训练集中直接学习到,需要人为地设定。超参数设置不当,可能导致欠拟合和过拟合的问题。
欠拟合和过拟合¶
欠拟合:真实的规律较为复杂,但训练出的模型较为简单,使得模型没有学习到真实的规律。当对新样本进行预测时,预测值虽然很稳定,但一直和真实值偏差较大,所以预测效果不好。
过拟合:训练出的模型非常复杂,但仅仅是对样本内的数据规律掌握得很好。一旦样本稍作变换,预测值容易发生剧烈变化(即预测值的方差很大),预测效果不好。
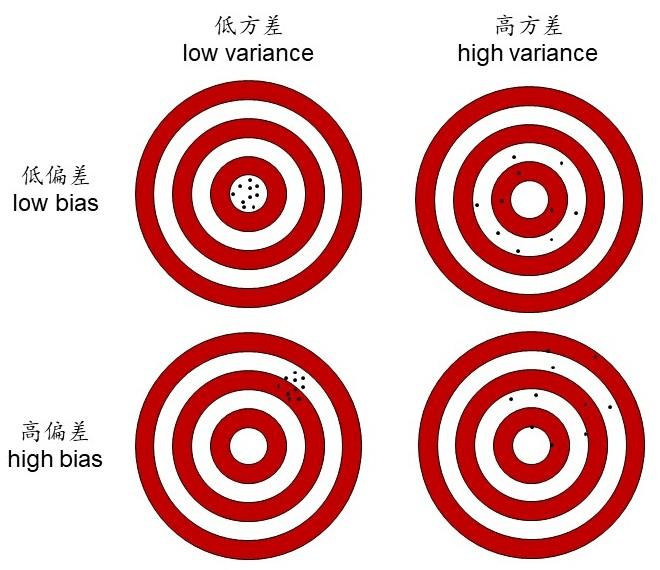
下面的图片形象地说明了偏差和方差是如何影响准确度的。欠拟合属于高偏差、低方差(左下角),过拟合属于低偏差、高方差(右上角)。
交叉验证的方法¶
Stone 和 Geisser 在 1974 年分别独立地提出,在评价某个统计模型的表现时,应使用在估计模型环节未使用过的数据。这和学生考试的情形类似,要想考察学生是否掌握了某个知识点,不能使用课堂上讲过的“例题”,而应当使用相似的“习题”。
交叉验证的核心思想是先将全部样本划分成两部分,一部分用来训练模型,称为训练集;另外一部分用来验证模型,称为验证集。随后考察模型在训练集和验证集的表现是否接近。如果两者接近,说明模型具备较好的预测性能;如果训练集的表现远优于验证集,说明模型存在过拟合的风险。
根据训练集和验证集的划分方式,交叉验证方法又可以细分为简单交叉验证、K 折交叉验 证、留一法、留 P 法和时序交叉验证。
简单交叉验证¶
从总样本中随机选取一定比例(如 30%)的样本作为验证集。这也是我的论文中使用的方法。
优点:
- 只需要训练一次模型,速度较快。
缺点:
-
有一部分数据从未参与训练,可能削弱模型的准确性,在极端情况下,当验证集中数据本身就是整体数据的“噪点”时,模型的准确度将会大大降低;
-
最终的模型评价结果可能受到训练集和验证集划分过程中的随机因素干扰。
K 折交叉验证¶
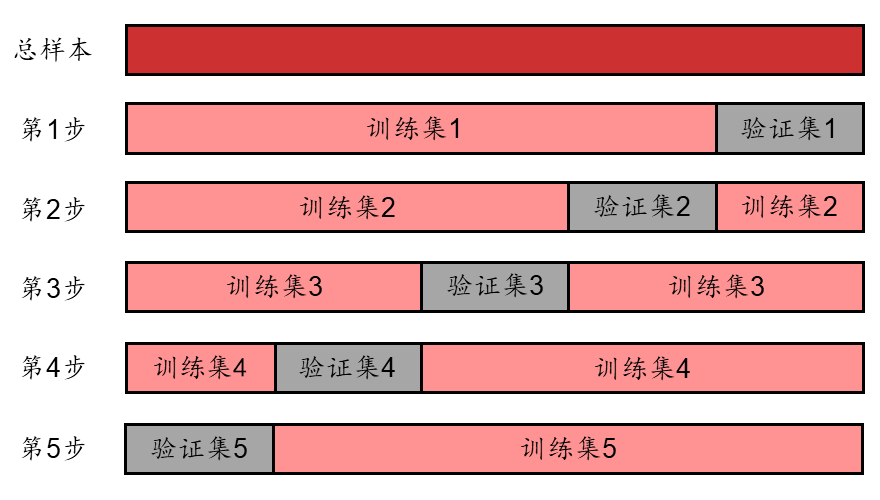
随机将全体样本分为 K 个部分(K 在 3~20 之间),每次用其中的一部分作为验证集,其余部分作为训练集。重复 K 次,直到所有部分都被验证过。最终将得到 5 个验证集的均方误差(或其它损失函数形式),取均值作为验证集的平均表现。
留一法和留 P 法¶
假设样本量为\(N\),如果每次取一个样本验证,把其余样本用来训练,重复\(N\)次,这种方法称为留一法交叉验证(leave-one-out cross-validation,LOOCV)。还可以每次取 P 个样本验证,重复\(C_N^P\)次,这种方法称为留 P 法(leave-p-out cross-validation,LPOCV)。
如果数据量很大,就不适合用留一法和留 P 法,因为这需要重复验证非常多次。
时序交叉验证¶
以上四种传统交叉验证方法成立的前提是样本服从独立同分布。时间序列数据的特点是,过去和未来的数据存在相关关系,因此通常不满足独立同分布的假设。如果依然采用传统交叉验证方法,可能会将未来时刻的数据划入训练集,历史时刻的数据划入验证集,进而出现用未来规律预测历史结果的“作弊”行为。
时序交叉验证的思想是:既能尽可能多的利用数据,又能避免用未来信息预测历史信息的行为。
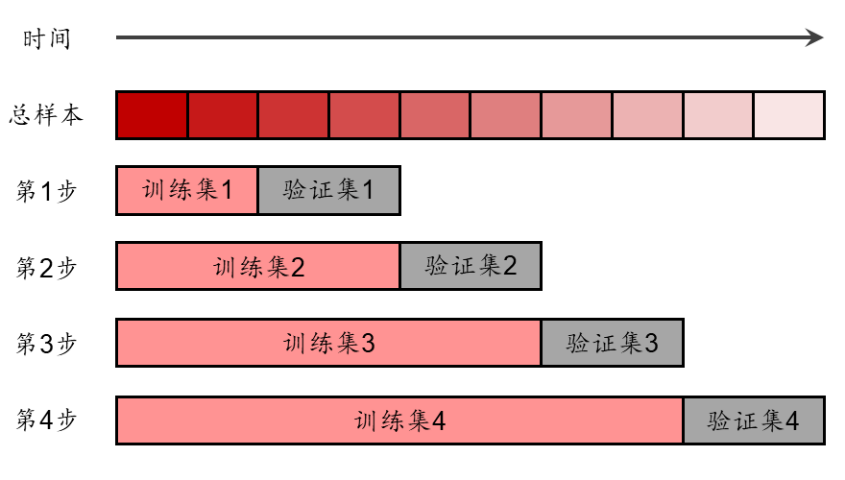
下图展示了时序交叉验证的数据划分方法。在第 1 步,只用较少的数据,前期的数据作训练集,后期的数据作验证集。第 2 步将扩大训练集,验证集的大小不变,但需要往后推移。以此类推,最后一步时,训练集和测试集充分利用了全体数据,且保证了验证集在训练集之后。
实证检验¶
机器学习公共数据集(包含时序数据和非时序数据)¶
报告原文使用 K 折交叉验证和时序交叉验证对几个数据集进行了检验。主要结论是:
- 将复杂机器学习方法应用于时间序列数据时,传统 K 折交叉验证表现出一定的过拟合倾向;而时序交叉验证的过拟合程度较低,泛化能力较强。
- 对于简单机器学习方法(如逻辑回归、线性 SVM)而言,由于模型本身拟合能力不强,K 折交叉验证和时序交叉验证的表现接近。
- 时序交叉验证在时间开销上也具有一定优势。一般来说,时序交叉验证的验证时间是 K 折交叉验证的\(\frac{1}{2}\)。这是因为时序交叉验证总体的训练数据较少。普通的 K 折交叉验证每次都要用到全部的数据做训练和验证,时序交叉验证在前期只用到少部分数据做训练,未来的数据是不能用的。
- 在应用于非时间序列数据时,K 折交叉验证和时序交叉验证没有明显差异。
A 股数据集并构建策略进行回测¶
报告的最后对 A 股因子数据进行了检验,并构建策略进行回测,主要结论是:
- 因子数据具备较强的序列相关性,不满足传统交叉验证所需要的样本独立同分布原则。
- 时序交叉验证选择了更“简单”的模型,更不容易出现过拟合。
- 时序交叉验证方法的测试集正确率、AUC 和 RankIC 值更高,样本内正确率更低,表明时序交叉验证的过拟合程度较低,而 K 折交叉验证表现出明显的过拟合。
- 从策略回测结果来看,对于简单的逻辑回归模型,时序交叉验证与 K 折交叉验证表现接近;对于复杂的 XGBoost 模型,时序交叉验证具备明显优势。