基于强化学习 DQN 算法的登月着陆机器人¶
本文基于强化学习 DQN 算法,训练了一个登月着陆机器人。它能够采取向左右移动、向下喷射减缓速度等动作,在有干扰的环境下准确地降落在月球表面的指定区域。
Deep Q-Learning - Lunar Lander¶
In this assignment, you will train an agent to land a lunar lander safely on a landing pad on the surface of the moon.
Reference: https://www.gymlibrary.dev/environments/box2d/lunar_lander/
1 - Import Packages¶
We'll make use of the following packages:
numpyis a package for scientific computing in python.dequewill be our data structure for our memory buffer.namedtuplewill be used to store the experience tuples.- The
gymtoolkit is a collection of environments that can be used to test reinforcement learning algorithms. PIL.Imageandpyvirtualdisplayare needed to render the Lunar Lander environment.- We will use several modules from the
torch.nnframework for building deep learning models. utilsis a module that contains helper functions for this assignment. You do not need to modify the code in this file.
Run the cell below to import all the necessary packages.
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
E: Unable to locate package python-opengl
!pip install pillow
!pip install imageio
!pip install matplotlib
!pip install pandas
!pip install statsmodels
Requirement already satisfied: pillow in /opt/conda/lib/python3.10/site-packages (9.5.0)
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0mRequirement already satisfied: imageio in /opt/conda/lib/python3.10/site-packages (2.28.1)
Requirement already satisfied: numpy in /opt/conda/lib/python3.10/site-packages (from imageio) (1.23.5)
Requirement already satisfied: pillow>=8.3.2 in /opt/conda/lib/python3.10/site-packages (from imageio) (9.5.0)
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0mRequirement already satisfied: matplotlib in /opt/conda/lib/python3.10/site-packages (3.6.3)
Requirement already satisfied: contourpy>=1.0.1 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (1.0.7)
Requirement already satisfied: cycler>=0.10 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (0.11.0)
Requirement already satisfied: fonttools>=4.22.0 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (4.39.3)
Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (1.4.4)
Requirement already satisfied: numpy>=1.19 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (1.23.5)
Requirement already satisfied: packaging>=20.0 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (21.3)
Requirement already satisfied: pillow>=6.2.0 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (9.5.0)
Requirement already satisfied: pyparsing>=2.2.1 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (3.0.9)
Requirement already satisfied: python-dateutil>=2.7 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (2.8.2)
Requirement already satisfied: six>=1.5 in /opt/conda/lib/python3.10/site-packages (from python-dateutil>=2.7->matplotlib) (1.16.0)
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0mRequirement already satisfied: pandas in /opt/conda/lib/python3.10/site-packages (1.5.3)
Requirement already satisfied: python-dateutil>=2.8.1 in /opt/conda/lib/python3.10/site-packages (from pandas) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /opt/conda/lib/python3.10/site-packages (from pandas) (2023.3)
Requirement already satisfied: numpy>=1.21.0 in /opt/conda/lib/python3.10/site-packages (from pandas) (1.23.5)
Requirement already satisfied: six>=1.5 in /opt/conda/lib/python3.10/site-packages (from python-dateutil>=2.8.1->pandas) (1.16.0)
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0mRequirement already satisfied: statsmodels in /opt/conda/lib/python3.10/site-packages (0.13.5)
Requirement already satisfied: pandas>=0.25 in /opt/conda/lib/python3.10/site-packages (from statsmodels) (1.5.3)
Requirement already satisfied: patsy>=0.5.2 in /opt/conda/lib/python3.10/site-packages (from statsmodels) (0.5.3)
Requirement already satisfied: packaging>=21.3 in /opt/conda/lib/python3.10/site-packages (from statsmodels) (21.3)
Requirement already satisfied: scipy>=1.3 in /opt/conda/lib/python3.10/site-packages (from statsmodels) (1.10.1)
Requirement already satisfied: numpy>=1.17 in /opt/conda/lib/python3.10/site-packages (from statsmodels) (1.23.5)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /opt/conda/lib/python3.10/site-packages (from packaging>=21.3->statsmodels) (3.0.9)
Requirement already satisfied: python-dateutil>=2.8.1 in /opt/conda/lib/python3.10/site-packages (from pandas>=0.25->statsmodels) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /opt/conda/lib/python3.10/site-packages (from pandas>=0.25->statsmodels) (2023.3)
Requirement already satisfied: six in /opt/conda/lib/python3.10/site-packages (from patsy>=0.5.2->statsmodels) (1.16.0)
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0m
!pip install swig
!pip install imageio[ffmpeg]
!pip install gym pyvirtualdisplay pyglet
!pip install gym[box2d]
Collecting swig
Downloading swig-4.1.1-py2.py3-none-manylinux_2_5_x86_64.manylinux1_x86_64.whl (1.8 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m1.8/1.8 MB[0m [31m30.6 MB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hInstalling collected packages: swig
Successfully installed swig-4.1.1
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0mRequirement already satisfied: imageio[ffmpeg] in /opt/conda/lib/python3.10/site-packages (2.28.1)
Requirement already satisfied: numpy in /opt/conda/lib/python3.10/site-packages (from imageio[ffmpeg]) (1.23.5)
Requirement already satisfied: pillow>=8.3.2 in /opt/conda/lib/python3.10/site-packages (from imageio[ffmpeg]) (9.5.0)
Collecting imageio-ffmpeg (from imageio[ffmpeg])
Downloading imageio_ffmpeg-0.4.8-py3-none-manylinux2010_x86_64.whl (26.9 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m26.9/26.9 MB[0m [31m48.4 MB/s[0m eta [36m0:00:00[0m00:01[0m00:01[0m
[?25hRequirement already satisfied: psutil in /opt/conda/lib/python3.10/site-packages (from imageio[ffmpeg]) (5.9.3)
Installing collected packages: imageio-ffmpeg
Successfully installed imageio-ffmpeg-0.4.8
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0mRequirement already satisfied: gym in /opt/conda/lib/python3.10/site-packages (0.26.2)
Collecting pyvirtualdisplay
Downloading PyVirtualDisplay-3.0-py3-none-any.whl (15 kB)
Collecting pyglet
Downloading pyglet-2.0.7-py3-none-any.whl (841 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m841.0/841.0 kB[0m [31m19.7 MB/s[0m eta [36m0:00:00[0m00:01[0m
[?25hRequirement already satisfied: numpy>=1.18.0 in /opt/conda/lib/python3.10/site-packages (from gym) (1.23.5)
Requirement already satisfied: cloudpickle>=1.2.0 in /opt/conda/lib/python3.10/site-packages (from gym) (2.2.1)
Requirement already satisfied: gym-notices>=0.0.4 in /opt/conda/lib/python3.10/site-packages (from gym) (0.0.8)
Installing collected packages: pyvirtualdisplay, pyglet
Successfully installed pyglet-2.0.7 pyvirtualdisplay-3.0
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0mRequirement already satisfied: gym[box2d] in /opt/conda/lib/python3.10/site-packages (0.26.2)
Requirement already satisfied: numpy>=1.18.0 in /opt/conda/lib/python3.10/site-packages (from gym[box2d]) (1.23.5)
Requirement already satisfied: cloudpickle>=1.2.0 in /opt/conda/lib/python3.10/site-packages (from gym[box2d]) (2.2.1)
Requirement already satisfied: gym-notices>=0.0.4 in /opt/conda/lib/python3.10/site-packages (from gym[box2d]) (0.0.8)
Collecting box2d-py==2.3.5 (from gym[box2d])
Downloading box2d-py-2.3.5.tar.gz (374 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m374.4/374.4 kB[0m [31m11.5 MB/s[0m eta [36m0:00:00[0m
[?25h Preparing metadata (setup.py) ... [?25ldone
[?25hCollecting pygame==2.1.0 (from gym[box2d])
Downloading pygame-2.1.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (18.3 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m18.3/18.3 MB[0m [31m54.2 MB/s[0m eta [36m0:00:00[0m00:01[0m00:01[0m
[?25hRequirement already satisfied: swig==4.* in /opt/conda/lib/python3.10/site-packages (from gym[box2d]) (4.1.1)
Building wheels for collected packages: box2d-py
Building wheel for box2d-py (setup.py) ... [?25ldone
[?25h Created wheel for box2d-py: filename=box2d_py-2.3.5-cp310-cp310-linux_x86_64.whl size=495297 sha256=7d15bd91da1f1b3c3325a224882cd076affce9f2463ddf06326f7343c1a31447
Stored in directory: /root/.cache/pip/wheels/db/8f/6a/eaaadf056fba10a98d986f6dce954e6201ba3126926fc5ad9e
Successfully built box2d-py
Installing collected packages: box2d-py, pygame
Successfully installed box2d-py-2.3.5 pygame-2.1.0
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0m
import time
from collections import deque, namedtuple
import gym
import numpy as np
import PIL.Image
from pyvirtualdisplay import Display
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import base64
import random
from itertools import zip_longest
import imageio
import IPython
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
import numpy as np
import pandas as pd
import torch
from statsmodels.iolib.table import SimpleTable
SEED = 0 # Seed for the pseudo-random number generator.
MINIBATCH_SIZE = 64 # Mini-batch size.
TAU = 1e-3 # Soft update parameter.
E_DECAY = 0.995 # ε-decay rate for the ε-greedy policy.
E_MIN = 0.01 # Minimum ε value for the ε-greedy policy.
random.seed(SEED)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def check_update_conditions(t, num_steps_upd, memory_buffer):
"""
Determines if the conditions are met to perform a learning update.
Checks if the current time step t is a multiple of num_steps_upd and if the
memory_buffer has enough experience tuples to fill a mini-batch (for example, if the
mini-batch size is 64, then the memory buffer should have more than 64 experience
tuples in order to perform a learning update).
Args:
t (int):
The current time step.
num_steps_upd (int):
The number of time steps used to determine how often to perform a learning
update. A learning update is only performed every num_steps_upd time steps.
memory_buffer (deque):
A deque containing experiences. The experiences are stored in the memory
buffer as namedtuples: namedtuple("Experience", field_names=["state",
"action", "reward", "next_state", "done"]).
Returns:
A boolean that will be True if conditions are met and False otherwise.
"""
if (t + 1) % num_steps_upd == 0 and len(memory_buffer) > MINIBATCH_SIZE:
return True
else:
return False
def get_new_eps(epsilon):
"""
Updates the epsilon value for the ε-greedy policy.
Gradually decreases the value of epsilon towards a minimum value (E_MIN) using the
given ε-decay rate (E_DECAY).
Args:
epsilon (float):
The current value of epsilon.
Returns:
A float with the updated value of epsilon.
"""
return max(E_MIN, E_DECAY * epsilon)
def plot_history(point_history, **kwargs):
"""
Plots the total number of points received by the agent after each episode together
with the moving average (rolling mean).
Args:
point_history (list):
A list containing the total number of points the agent received after each
episode.
**kwargs: optional
window_size (int):
Size of the window used to calculate the moving average (rolling mean).
This integer determines the fixed number of data points used for each
window. The default window size is set to 10% of the total number of
data points in point_history, i.e. if point_history has 200 data points
the default window size will be 20.
lower_limit (int):
The lower limit of the x-axis in data coordinates. Default value is 0.
upper_limit (int):
The upper limit of the x-axis in data coordinates. Default value is
len(point_history).
plot_rolling_mean_only (bool):
If True, only plots the moving average (rolling mean) without the point
history. Default value is False.
plot_data_only (bool):
If True, only plots the point history without the moving average.
Default value is False.
"""
lower_limit = 0
upper_limit = len(point_history)
window_size = (upper_limit * 10) // 100
plot_rolling_mean_only = False
plot_data_only = False
if kwargs:
if "window_size" in kwargs:
window_size = kwargs["window_size"]
if "lower_limit" in kwargs:
lower_limit = kwargs["lower_limit"]
if "upper_limit" in kwargs:
upper_limit = kwargs["upper_limit"]
if "plot_rolling_mean_only" in kwargs:
plot_rolling_mean_only = kwargs["plot_rolling_mean_only"]
if "plot_data_only" in kwargs:
plot_data_only = kwargs["plot_data_only"]
points = point_history[lower_limit:upper_limit]
# Generate x-axis for plotting.
episode_num = [x for x in range(lower_limit, upper_limit)]
# Use Pandas to calculate the rolling mean (moving average).
rolling_mean = pd.DataFrame(points).rolling(window_size).mean()
plt.figure(figsize=(10, 7), facecolor="white")
if plot_data_only:
plt.plot(episode_num, points, linewidth=1, color="cyan")
elif plot_rolling_mean_only:
plt.plot(episode_num, rolling_mean, linewidth=2, color="magenta")
else:
plt.plot(episode_num, points, linewidth=1, color="cyan")
plt.plot(episode_num, rolling_mean, linewidth=2, color="magenta")
text_color = "black"
ax = plt.gca()
ax.set_facecolor("black")
plt.grid()
plt.xlabel("Episode", color=text_color, fontsize=30)
plt.ylabel("Total Points", color=text_color, fontsize=30)
yNumFmt = mticker.StrMethodFormatter("{x:,}")
ax.yaxis.set_major_formatter(yNumFmt)
ax.tick_params(axis="x", colors=text_color)
ax.tick_params(axis="y", colors=text_color)
plt.show()
def display_table(initial_state, action, next_state, reward, done):
"""
Displays a table containing the initial state, action, next state, reward, and done
values from Gym's Lunar Lander environment.
All floating point numbers in the table are displayed rounded to 3 decimal places
and actions are displayed using their labels instead of their numerical value (i.e
if action = 0, the action will be printed as "Do nothing" instead of "0").
Args:
initial_state (numpy.ndarray):
The initial state vector returned when resetting the Lunar Lander
environment, i.e the value returned by the env.reset() method.
action (int):
The action taken by the agent. In the Lunar Lander environment, actions are
represented by integers in the closed interval [0,3] corresponding to:
- Do nothing = 0
- Fire right engine = 1
- Fire main engine = 2
- Fire left engine = 3
next_state (numpy.ndarray):
The state vector returned by the Lunar Lander environment after the agent
takes an action, i.e the observation returned after running a single time
step of the environment's dynamics using env.step(action).
reward (numpy.float64):
The reward returned by the Lunar Lander environment after the agent takes an
action, i.e the reward returned after running a single time step of the
environment's dynamics using env.step(action).
done (bool):
The done value returned by the Lunar Lander environment after the agent
takes an action, i.e the done value returned after running a single time
step of the environment's dynamics using env.step(action).
Returns:
table (statsmodels.iolib.table.SimpleTable):
A table object containing the initial_state, action, next_state, reward,
and done values. This will result in the table being displayed in the
Jupyter Notebook.
"""
action_labels = [
"Do nothing",
"Fire right engine",
"Fire main engine",
"Fire left engine",
]
# Do not use column headers.
column_headers = None
# Display all floating point numbers rounded to 3 decimal places.
with np.printoptions(formatter={"float": "{:.3f}".format}):
table_info = [
("Initial State:", [f"{initial_state}"]),
("Action:", [f"{action_labels[action]}"]),
("Next State:", [f"{next_state}"]),
("Reward Received:", [f"{reward:.3f}"]),
("Episode Terminated:", [f"{done}"]),
]
# Generate table.
row_labels, data = zip_longest(*table_info)
table = SimpleTable(data, column_headers, row_labels)
return table
def embed_mp4(filename):
"""
Embeds an MP4 video file in a Jupyter notebook.
Args:
filename (string):
The path to the the MP4 video file that will be embedded (i.e.
"./videos/lunar_lander.mp4").
Returns:
Returns a display object from the given video file. This will result in the
video being displayed in the Jupyter Notebook.
"""
video = open(filename, "rb").read()
b64 = base64.b64encode(video)
tag = """
<video width="840" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>""".format(
b64.decode()
)
return IPython.display.HTML(tag)
def create_video(filename, env, q_network, fps=30):
"""
Creates a video of an agent interacting with a Gym environment.
The agent will interact with the given env environment using the q_network to map
states to Q values and using a greedy policy to choose its actions (i.e it will
choose the actions that yield the maximum Q values).
The video will be saved to a file with the given filename. The video format must be
specified in the filename by providing a file extension (.mp4, .gif, etc..). If you
want to embed the video in a Jupyter notebook using the embed_mp4 function, then the
video must be saved as an MP4 file.
Args:
filename (string):
The path to the file to which the video will be saved. The video format will
be selected based on the filename. Therefore, the video format must be
specified in the filename by providing a file extension (i.e.
"./videos/lunar_lander.mp4"). To see a list of supported formats see the
imageio documentation: https://imageio.readthedocs.io/en/v2.8.0/formats.html
env (Gym Environment):
The Gym environment the agent will interact with.
q_network (torch.nn.Sequential):
A Torch Sequential model that maps states to Q values.
fps (int):
The number of frames per second. Specifies the frame rate of the output
video. The default frame rate is 30 frames per second.
"""
with imageio.get_writer(filename, fps=fps) as video:
done = False
state, info = env.reset()
frame = env.render()
video.append_data(frame)
while not done:
state_qn = torch.from_numpy(
np.expand_dims(state, axis=0)
) # state needs to be the right shape for the q_network
state_qn = state_qn.to(device)
q_values = q_network(state_qn)
action = torch.argmax(q_values.detach()).item()
state, _, done, _, _ = env.step(action)
frame = env.render()
video.append_data(frame)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Set up a virtual display to render the Lunar Lander environment.
# run on linux
Display(visible=0, size=(840, 480)).start()
import random
random.seed(0)
# Set the random seed for Torch
torch.manual_seed(0)
torch.cuda.manual_seed_all(0)
np.random.seed(0)
2 - Hyperparameters¶
Run the cell below to set the hyperparameters.
MEMORY_SIZE = 100_000 # size of memory buffer
GAMMA = 0.995 # discount factor
ALPHA = 1e-3 # learning rate
NUM_STEPS_FOR_UPDATE = 4 # perform a learning update every C time steps
3 - The Lunar Lander Environment¶
In this notebook we will be using OpenAI's Gym Library. The Gym library provides a wide variety of environments for reinforcement learning. To put it simply, an environment represents a problem or task to be solved. In this notebook, we will try to solve the Lunar Lander environment using reinforcement learning.
The goal of the Lunar Lander environment is to land the lunar lander safely on the landing pad on the surface of the moon. The landing pad is designated by two flag poles and it is always at coordinates (0,0) but the lander is also allowed to land outside of the landing pad. The lander starts at the top center of the environment with a random initial force applied to its center of mass and has infinite fuel. The environment is considered solved if you get 200 points.
3.1 Action Space¶
The agent has four discrete actions available:
- Do nothing.
- Fire right engine.
- Fire main engine.
- Fire left engine.
Each action has a corresponding numerical value:
3.2 Observation Space¶
The agent's observation space consists of a state vector with 8 variables:
- Its \((x,y)\) coordinates. The landing pad is always at coordinates \((0,0)\).
- Its linear velocities \((\dot x,\dot y)\).
- Its angle \(\theta\).
- Its angular velocity \(\dot \theta\).
- Two booleans, \(l\) and \(r\), that represent whether each leg is in contact with the ground or not.
3.3 Rewards¶
The Lunar Lander environment has the following reward system:
- Landing on the landing pad and coming to rest is about 100-140 points.
- If the lander moves away from the landing pad, it loses reward.
- If the lander crashes, it receives -100 points.
- If the lander comes to rest, it receives +100 points.
- Each leg with ground contact is +10 points.
- Firing the main engine is -0.3 points each frame.
- Firing the side engine is -0.03 points each frame.
3.4 Episode Termination¶
An episode ends (i.e the environment enters a terminal state) if:
-
The lunar lander crashes (i.e if the body of the lunar lander comes in contact with the surface of the moon).
-
The absolute value of the lander's \(x\)-coordinate is greater than 1 (i.e. it goes beyond the left or right border)
You can check out the Open AI Gym documentation for a full description of the environment.
4 - Load the Environment¶
We start by loading the LunarLander-v2 environment from the gym library by using the .make() method. LunarLander-v2 is the latest version of the Lunar Lander environment and you can read about its version history in the Open AI Gym documentation.
Once we load the environment we use the .reset() method to reset the environment to the initial state. The lander starts at the top center of the environment and we can render the first frame of the environment by using the .render() method.
5 - Interacting with the Gym Environment¶
The Gym library implements the standard “agent-environment loop” formalism:
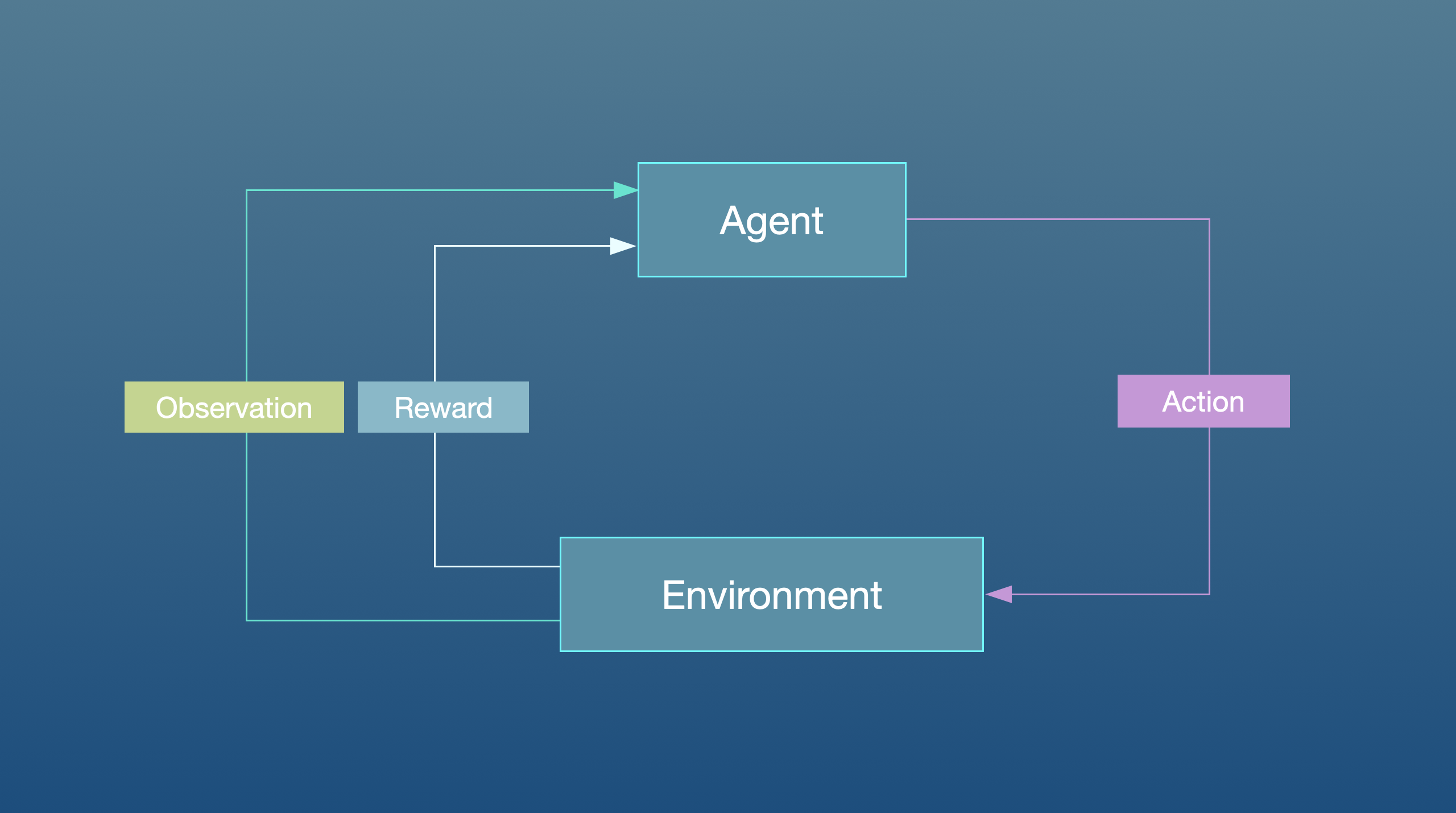
In the standard “agent-environment loop” formalism, an agent interacts with the environment in discrete time steps \(t=0,1,2,...\). At each time step \(t\), the agent uses a policy \(\pi\) to select an action \(A_t\) based on its observation of the environment's state \(S_t\). The agent receives a numerical reward \(R_t\) and on the next time step, moves to a new state \(S_{t+1}\).
5.1 Exploring the Environment's Dynamics¶
In Open AI's Gym environments, we use the .step() method to run a single time step of the environment's dynamics. In the version of gym that we are using the .step() method accepts an action and returns four values:
-
observation(object): an environment-specific object representing your observation of the environment. In the Lunar Lander environment this corresponds to a numpy array containing the positions and velocities of the lander as described in section 3.2 Observation Space. -
reward(float): amount of reward returned as a result of taking the given action. In the Lunar Lander environment this corresponds to a float of typenumpy.float64as described in section 3.3 Rewards. -
done(boolean): When done isTrue, it indicates the episode has terminated and it’s time to reset the environment. -
info(dictionary): diagnostic information useful for debugging. We won't be using this variable in this notebook but it is shown here for completeness.
To begin an episode, we need to reset the environment to an initial state. We do this by using the .reset() method.

In order to build our neural network later on we need to know the size of the state vector and the number of valid actions. We can get this information from our environment by using the .observation_space.shape and action_space.n methods, respectively.
state_size = env.observation_space.shape
num_actions = env.action_space.n
print("State Shape:", state_size)
print("Number of actions:", num_actions)
State Shape: (8,)
Number of actions: 4
Once the environment is reset, the agent can start taking actions in the environment by using the .step() method. Note that the agent can only take one action per time step.
In the cell below you can select different actions and see how the returned values change depending on the action taken. Remember that in this environment the agent has four discrete actions available and we specify them in code by using their corresponding numerical value:
# Select an action
action = 0
# Run a single time step of the environment's dynamics with the given action.
next_state, reward, done, truncated, info = env.step(action)
# Display table with values. All values are displayed to 3 decimal places.
display_table(initial_state, action, next_state, reward, done)
| Initial State: | (array([0.002, 1.412, 0.199, 0.049, -0.002, -0.045, 0.000, 0.000], dtype=float32), {}) |
|---|---|
| Action: | Do nothing |
| Next State: | [0.004 1.413 0.198 0.023 -0.004 -0.044 0.000 0.000] |
| Reward Received: | 0.211 |
| Episode Terminated: | False |
In practice, when we train the agent we use a loop to allow the agent to take many consecutive actions during an episode.
6 - Deep Q-Learning¶
In cases where both the state and action space are discrete we can estimate the action-value function iteratively by using the Bellman equation:
This iterative method converges to the optimal action-value function \(Q^*(s,a)\) as \(i\to\infty\). This means that the agent just needs to gradually explore the state-action space and keep updating the estimate of \(Q(s,a)\) until it converges to the optimal action-value function \(Q^*(s,a)\). However, in cases where the state space is continuous it becomes practically impossible to explore the entire state-action space. Consequently, this also makes it practically impossible to gradually estimate \(Q(s,a)\) until it converges to \(Q^*(s,a)\).
In the Deep \(Q\)-Learning, we solve this problem by using a neural network to estimate the action-value function \(Q(s,a)\approx Q^*(s,a)\). We call this neural network a \(Q\)-Network and it can be trained by adjusting its weights at each iteration to minimize the mean-squared error in the Bellman equation.
Unfortunately, using neural networks in reinforcement learning to estimate action-value functions has proven to be highly unstable. Luckily, there's a couple of techniques that can be employed to avoid instabilities. These techniques consist of using a Target Network and Experience Replay. We will explore these two techniques in the following sections.
6.1 Target Network¶
We can train the \(Q\)-Network by adjusting it's weights at each iteration to minimize the mean-squared error in the Bellman equation, where the target values are given by:
where \(w\) are the weights of the \(Q\)-Network. This means that we are adjusting the weights \(w\) at each iteration to minimize the following error:
Notice that this forms a problem because the \(y\) target is changing on every iteration. Having a constantly moving target can lead to oscillations and instabilities. To avoid this, we can create a separate neural network for generating the \(y\) targets. We call this separate neural network the target \(\hat Q\)-Network and it will have the same architecture as the original \(Q\)-Network. By using the target \(\hat Q\)-Network, the above error becomes:
where \(w^-\) and \(w\) are the weights the target \(\hat Q\)-Network and \(Q\)-Network, respectively.
In practice, we will use the following algorithm: every \(C\) time steps we will use the \(\hat Q\)-Network to generate the \(y\) targets and update the weights of the target \(\hat Q\)-Network using the weights of the \(Q\)-Network. We will update the weights \(w^-\) of the the target \(\hat Q\)-Network using a soft update. This means that we will update the weights \(w^-\) using the following rule:
where \(\tau\ll 1\). By using the soft update, we are ensuring that the target values, \(y\), change slowly, which greatly improves the stability of our learning algorithm.
Exercise 1¶
In this exercise you will create the \(Q\) and target \(\hat Q\) networks and set the optimizer. Remember that the Deep \(Q\)-Network (DQN) is a neural network that approximates the action-value function \(Q(s,a)\approx Q^*(s,a)\). It does this by learning how to map states to \(Q\) values.
To solve the Lunar Lander environment, we are going to employ a DQN with the following architecture:
-
A
Linearlayer withstate_size[0]input units,64output units -
A
reluactivation function layer. -
A
Linearlayer with64input units,64output units -
A
reluactivation function layer. -
A
Linearlayer with64input units,num_actionsoutput units
In the cell below you should create the \(Q\)-Network and the target \(\hat Q\)-Network using the model architecture described above. Remember that both the \(Q\)-Network and the target \(\hat Q\)-Network have the same architecture.
Lastly, you should set Adam as the optimizer with a learning rate equal to ALPHA. Recall that ALPHA was defined in the Hyperparameters section. We should note that for this exercise you should use the already imported packages:
# Create the Q-Network
q_network = nn.Sequential(
### START CODE HERE ###
nn.Linear(state_size[0], 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, num_actions)
### END CODE HERE ###
)
# Create the target Q^-Network
target_q_network = nn.Sequential(
### START CODE HERE ###
nn.Linear(state_size[0], 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, num_actions)
### END CODE HERE ###
)
### START CODE HERE ###
optimizer = optim.Adam(q_network.parameters(), lr=ALPHA)
### END CODE HERE ###
# Make them have the same initial parameters.
for target_param, param in zip(target_q_network.parameters(), q_network.parameters()):
target_param.data.copy_(param.data)
6.2 Experience Replay¶
When an agent interacts with the environment, the states, actions, and rewards the agent experiences are sequential by nature. If the agent tries to learn from these consecutive experiences it can run into problems due to the strong correlations between them. To avoid this, we employ a technique known as Experience Replay to generate uncorrelated experiences for training our agent. Experience replay consists of storing the agent's experiences (i.e the states, actions, and rewards the agent receives) in a memory buffer and then sampling a random mini-batch of experiences from the buffer to do the learning. The experience tuples \((S_t, A_t, R_t, S_{t+1})\) will be added to the memory buffer at each time step as the agent interacts with the environment.
For convenience, we will store the experiences as named tuples.
# Store experiences as named tuples
experience = namedtuple(
"Experience", field_names=["state", "action", "reward", "next_state", "done"]
)
By using experience replay we avoid problematic correlations, oscillations and instabilities. In addition, experience replay also allows the agent to potentially use the same experience in multiple weight updates, which increases data efficiency.
7 - Deep Q-Learning Algorithm with Experience Replay¶
Now that we know all the techniques that we are going to use, we can put them together to arrive at the Deep Q-Learning Algorithm With Experience Replay.

Exercise 2¶
In this exercise you will implement line 12 of the algorithm outlined in Fig 3 above and you will also compute the loss between the \(y\) targets and the \(Q(s,a)\) values. In the cell below, complete the compute_loss function by setting the \(y\) targets equal to:
Here are a couple of things to note:
-
The
compute_lossfunction takes in a mini-batch of experience tuples. This mini-batch of experience tuples is unpacked to extract thestates,actions,rewards,next_states, anddone_vals. You should keep in mind that these variables are Pytorch Tensors whose size will depend on the mini-batch size. For example, if the mini-batch size is64then bothrewardsanddone_valswill be Pytorch Tensors with64elements. -
Using
if/elsestatements to set the \(y\) targets will not work when the variables are tensors with many elements. However, notice that you can use thedone_valsto implement the above in a single line of code. To do this, recall that thedonevariable is a Boolean variable that takes the valueTruewhen an episode terminates at step \(j+1\) and it isFalseotherwise. Taking into account that a Boolean value ofTruehas the numerical value of1and a Boolean value ofFalsehas the numerical value of0, you can use the factor(1 - done_vals)to implement the above in a single line of code. Here's a hint: notice that(1 - done_vals)has a value of0whendone_valsisTrueand a value of1whendone_valsisFalse.
Lastly, compute the loss by calculating the Mean-Squared Error (MSE) between the y_targets and the q_values. To calculate the mean-squared error you should use F.mse_loss:
def compute_loss(experiences, gamma, q_network, target_q_network):
"""
Calculates the loss.
Args:
experiences: (tuple) tuple of ["state", "action", "reward", "next_state", "done"] namedtuples
gamma: (float) The discount factor.
q_network: (torch.nn.Sequential) PyTorch model for predicting the q_values
target_q_network: (torch.nn.Sequential) PyTorch model for predicting the targets
Returns:
loss: (PyTorch Tensor) the Mean-Squared Error between the y targets and the Q(s,a) values.
"""
# Unpack the mini-batch of experience tuples
states, actions, rewards, next_states, done_vals = experiences
### START CODE HERE ###
# Compute max Q^(s,a) using torch.max and target_q_network, pay attendion to the `dim` parameter.
max_qsa = torch.max(target_q_network(next_states), dim=-1)[0]
# Set y = R if episode terminates(done_vals are the boolean values indicating if the episode ended)
# otherwise set y = R + γ max Q^(s,a).
y_targets = rewards + (gamma * max_qsa * (1 - done_vals))
# Get the q_values from q_network
q_values = q_network(states)
# Comprehend what `gather` does in the following line.
q_values = q_values.gather(1, actions.long().unsqueeze(1))
# Compute the loss using F.mse_loss between q_values and y_targets. You may need to use `unsqueeze` on y_targets.
loss = F.mse_loss(q_values, y_targets.unsqueeze(1))
### END CODE HERE ###
return loss
8 - Update the Network Weights¶
We will use the agent_learn function below to implement lines 12 -14 of the algorithm outlined in Fig 3. The agent_learn function will update the weights of the \(Q\) and target \(\hat Q\) networks using a custom training loop.
The last line of this function updates the weights of the target \(\hat Q\)-Network using a soft update. If you want to know how this is implemented in code we encourage you to take a look at the utils.update_target_network function in the utils module.
def update_target_network(q_network, target_q_network):
"""
Updates the weights of the target Q-Network using a soft update.
The weights of the target_q_network are updated using the soft update rule:
w_target = (TAU * w) + (1 - TAU) * w_target
where w_target are the weights of the target_q_network, TAU is the soft update
parameter, and w are the weights of the q_network.
Args:
q_network (torch.nn.Module):
The Q-Network.
target_q_network (torch.nn.Module):
The Target Q-Network.
"""
TAU = 1e-3 # Soft update parameter.
for target_param, param in zip(
target_q_network.parameters(), q_network.parameters()
):
target_param.data.copy_(TAU * param.data + (1.0 - TAU) * target_param.data)
MINIBATCH_SIZE = 64 # Mini-batch size.
def get_experiences(memory_buffer):
"""
Returns a random sample of experience tuples drawn from the memory buffer.
Retrieves a random sample of experience tuples from the given memory_buffer and
returns them as PyTorch Tensors. The size of the random sample is determined by
the mini-batch size (MINIBATCH_SIZE).
Args:
memory_buffer (deque):
A deque containing experiences. The experiences are stored in the memory
buffer as namedtuples: namedtuple("Experience", field_names=["state",
"action", "reward", "next_state", "done"]).
Returns:
A tuple (states, actions, rewards, next_states, done_vals) where:
- states are the starting states of the agent.
- actions are the actions taken by the agent from the starting states.
- rewards are the rewards received by the agent after taking the actions.
- next_states are the new states of the agent after taking the actions.
- done_vals are the boolean values indicating if the episode ended.
All tuple elements are PyTorch Tensors whose shape is determined by the
mini-batch size and the given Gym environment. For the Lunar Lander environment
the states and next_states will have a shape of [MINIBATCH_SIZE, 8] while the
actions, rewards, and done_vals will have a shape of [MINIBATCH_SIZE]. All
PyTorch Tensors have elements with dtype=torch.float32.
"""
experiences = random.sample(memory_buffer, k=MINIBATCH_SIZE)
states = torch.tensor(
[e.state for e in experiences if e is not None],
dtype=torch.float32,
device=device,
)
actions = torch.tensor(
[e.action for e in experiences if e is not None],
dtype=torch.float32,
device=device,
)
rewards = torch.tensor(
[e.reward for e in experiences if e is not None],
dtype=torch.float32,
device=device,
)
next_states = torch.tensor(
[e.next_state for e in experiences if e is not None],
dtype=torch.float32,
device=device,
)
done_vals = torch.tensor(
[e.done for e in experiences if e is not None],
dtype=torch.float32,
device=device,
)
return (states, actions, rewards, next_states, done_vals)
def agent_learn(experiences, gamma):
"""
Updates the weights of the Q networks.
Args:
experiences: (tuple) tuple of ["state", "action", "reward", "next_state", "done"] namedtuples
gamma: (float) The discount factor.
"""
# Unpack the mini-batch of experience tuples
states, actions, rewards, next_states, done_vals = experiences
# Calculate the loss
loss = compute_loss(
(states, actions, rewards, next_states, done_vals),
gamma,
q_network,
target_q_network,
)
# Compute gradients and update weights of q_network
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Update the weights of target_q_network
update_target_network(q_network, target_q_network)
9 - Train the Agent¶
We are now ready to train our agent to solve the Lunar Lander environment. In the cell below we will implement the algorithm in Fig 3 line by line (please note that we have included the same algorithm below for easy reference. This will prevent you from scrolling up and down the notebook):
-
Line 1: We initialize the
memory_bufferwith a capacity of \(N =\)MEMORY_SIZE. Notice that we are using adequeas the data structure for ourmemory_buffer. -
Line 2: We skip this line since we already initialized the
q_networkin Exercise 1. -
Line 3: We initialize the
target_q_networkby setting its weights to be equal to those of theq_network. -
Line 4: We start the outer loop. Notice that we have set \(M =\)
num_episodes = 2000. This number is reasonable because the agent should be able to solve the Lunar Lander environment in less than2000episodes using this notebook's default parameters. -
Line 5: We use the
.reset()method to reset the environment to the initial state and get the initial state. -
Line 6: We start the inner loop. Notice that we have set \(T =\)
max_num_timesteps = 1000. This means that the episode will automatically terminate if the episode hasn't terminated after1000time steps. -
Line 7: The agent observes the current
stateand chooses anactionusing an \(\epsilon\)-greedy policy. Our agent starts out using a value of \(\epsilon =\)epsilon = 1which yields an \(\epsilon\)-greedy policy that is equivalent to the equiprobable random policy. This means that at the beginning of our training, the agent is just going to take random actions regardless of the observedstate. As training progresses we will decrease the value of \(\epsilon\) slowly towards a minimum value using a given \(\epsilon\)-decay rate. We want this minimum value to be close to zero because a value of \(\epsilon = 0\) will yield an \(\epsilon\)-greedy policy that is equivalent to the greedy policy. This means that towards the end of training, the agent will lean towards selecting theactionthat it believes (based on its past experiences) will maximize \(Q(s,a)\). We will set the minimum \(\epsilon\) value to be0.01and not exactly 0 because we always want to keep a little bit of exploration during training. If you want to know how this is implemented in code we encourage you to take a look at theutils.get_actionfunction in theutilsmodule. -
Line 8: We use the
.step()method to take the givenactionin the environment and get therewardand thenext_state. -
Line 9: We store the
experience(state, action, reward, next_state, done)tuple in ourmemory_buffer. Notice that we also store thedonevariable so that we can keep track of when an episode terminates. This allowed us to set the \(y\) targets in Exercise 2. -
Line 10: We check if the conditions are met to perform a learning update. We do this by using our custom
utils.check_update_conditionsfunction. This function checks if \(C =\)NUM_STEPS_FOR_UPDATE = 4time steps have occured and if ourmemory_bufferhas enough experience tuples to fill a mini-batch. For example, if the mini-batch size is64, then ourmemory_buffershould have more than64experience tuples in order to pass the latter condition. If the conditions are met, then theutils.check_update_conditionsfunction will return a value ofTrue, otherwise it will return a value ofFalse. -
Lines 11 - 14: If the
updatevariable isTruethen we perform a learning update. The learning update consists of sampling a random mini-batch of experience tuples from ourmemory_buffer, setting the \(y\) targets, performing gradient descent, and updating the weights of the networks. We will use theagent_learnfunction we defined in Section 8 to perform the latter 3. -
Line 15: At the end of each iteration of the inner loop we set
next_stateas our newstateso that the loop can start again from this new state. In addition, we check if the episode has reached a terminal state (i.e we check ifdone = True). If a terminal state has been reached, then we break out of the inner loop. -
Line 16: At the end of each iteration of the outer loop we update the value of \(\epsilon\), and check if the environment has been solved. We consider that the environment has been solved if the agent receives an average of
200points in the last100episodes. If the environment has not been solved we continue the outer loop and start a new episode.
Finally, we wanted to note that we have included some extra variables to keep track of the total number of points the agent received in each episode. This will help us determine if the agent has solved the environment and it will also allow us to see how our agent performed during training. We also use the time module to measure how long the training takes.
def get_action(q_values, epsilon=0.0):
"""
Returns an action using an ε-greedy policy.
This function will return an action according to the following rules:
- With probability epsilon, it will return an action chosen at random.
- With probability (1 - epsilon), it will return the action that yields the
maximum Q value in q_values.
Args:
q_values (torch.Tensor):
The Q values returned by the Q-Network. For the Lunar Lander environment
this PyTorch Tensor should have a shape of [1, 4] and its elements should
have dtype=torch.float32.
epsilon (float):
The current value of epsilon.
Returns:
An action (numpy.int64). For the Lunar Lander environment, actions are
represented by integers in the closed interval [0,3].
"""
if random.random() > epsilon:
### START CODE HERE ###
return torch.argmax(q_values).item()
### END CODE HERE ###
else:
### START CODE HERE ###
return random.randint(0, 3)
### END CODE HERE ###
# %debug
start = time.time()
num_episodes = 2000
max_num_timesteps = 1000
total_point_history = []
num_p_av = 100 # number of total points to use for averaging
epsilon = 1.0 # initial ε value for ε-greedy policy
# Create a memory buffer D with capacity N
memory_buffer = deque(maxlen=MEMORY_SIZE)
q_network = q_network.to(device)
target_q_network = target_q_network.to(device)
# Set the target network weights equal to the Q-Network weights
target_q_network.load_state_dict(q_network.state_dict())
for i in range(num_episodes):
# Reset the environment to the initial state and get the initial state
state, info = env.reset()
total_points = 0
for t in range(max_num_timesteps):
# From the current state S choose an action A using an ε-greedy policy
state_qn = torch.from_numpy(
np.expand_dims(state, axis=0)
) # state needs to be the right shape for the q_network
state_qn = state_qn.to(device)
q_values = q_network(state_qn)
action = get_action(q_values, epsilon)
# Take action A and receive reward R and the next state S'
next_state, reward, done, truncated, info = env.step(action)
# Store experience tuple (S,A,R,S') in the memory buffer.
# We store the done variable as well for convenience.
memory_buffer.append(experience(state, action, reward, next_state, done))
# Only update the network every NUM_STEPS_FOR_UPDATE time steps.
update = check_update_conditions(t, NUM_STEPS_FOR_UPDATE, memory_buffer)
if update:
# Sample random mini-batch of experience tuples (S,A,R,S') from D
experiences = get_experiences(memory_buffer)
# Set the y targets, perform a gradient descent step,
# and update the network weights.
agent_learn(experiences, GAMMA)
state = next_state.copy()
total_points += reward
if done:
break
total_point_history.append(total_points)
av_latest_points = np.mean(total_point_history[-num_p_av:])
# Update the ε value
epsilon = get_new_eps(epsilon)
print(
f"\rEpisode {i+1} | Total point average of the last {num_p_av} episodes: {av_latest_points:.2f}",
end="",
)
if (i + 1) % num_p_av == 0:
print(
f"\rEpisode {i+1} | Total point average of the last {num_p_av} episodes: {av_latest_points:.2f}"
)
# We will consider that the environment is solved if we get an
# average of 200 points in the last 100 episodes.
if av_latest_points >= 200.0:
print(f"\n\nEnvironment solved in {i+1} episodes!")
torch.save(q_network, "lunar_lander_model.pt")
break
tot_time = time.time() - start
print(f"\nTotal Runtime: {tot_time:.2f} s ({(tot_time/60):.2f} min)")
Episode 100 | Total point average of the last 100 episodes: -160.81
Episode 200 | Total point average of the last 100 episodes: -94.379
Episode 300 | Total point average of the last 100 episodes: -66.97
Episode 400 | Total point average of the last 100 episodes: -19.23
Episode 500 | Total point average of the last 100 episodes: 135.43
Episode 600 | Total point average of the last 100 episodes: 196.77
Episode 607 | Total point average of the last 100 episodes: 200.16
Environment solved in 607 episodes!
Total Runtime: 775.11 s (12.92 min)
We can plot the total point history along with the moving average to see how our agent improved during training. If you want to know about the different plotting options available in the utils.plot_history function we encourage you to take a look at the utils module.
# Plot the total point history along with the moving average
plot_history(total_point_history)
10 - See the Trained Agent In Action¶
Now that we have trained our agent, we can see it in action. We will use the utils.create_video function to create a video of our agent interacting with the environment using the trained \(Q\)-Network. The utils.create_video function uses the imageio library to create the video. This library produces some warnings that can be distracting, so, to suppress these warnings we run the code below.
In the cell below we create a video of our agent interacting with the Lunar Lander environment using the trained q_network. The video is saved to the videos folder with the given filename. We use the utils.embed_mp4 function to embed the video in the Jupyter Notebook so that we can see it here directly without having to download it.
We should note that since the lunar lander starts with a random initial force applied to its center of mass, every time you run the cell below you will see a different video. If the agent was trained properly, it should be able to land the lunar lander in the landing pad every time, regardless of the initial force applied to its center of mass.
11 - Congratulations!¶
You have successfully used Deep Q-Learning with Experience Replay to train an agent to land a lunar lander safely on a landing pad on the surface of the moon. Congratulations!
12 - References¶
If you would like to learn more about Deep Q-Learning, we recommend you check out the following papers.
-
Mnih, V., Kavukcuoglu, K., Silver, D. et al. Human-level control through deep reinforcement learning. Nature 518, 529–533 (2015).
-
Lillicrap, T. P., Hunt, J. J., Pritzel, A., et al. Continuous Control with Deep Reinforcement Learning. ICLR (2016).
-
Mnih, V., Kavukcuoglu, K., Silver, D. et al. Playing Atari with Deep Reinforcement Learning. arXiv e-prints. arXiv:1312.5602 (2013).