均值方差模型的有效前沿曲线¶
在无做空限制的情形下推导均值方差模型的有效前沿曲线,本质上是求解一个带有等式约束的最优化问题。
问题描述¶
已知\(N\)个资产的预期收益率\(\mu_{N\times1}\),收益率协方差矩阵\(\Sigma_{N\times N}\),均值方差模型需要求解的是:给定投资组合的预期收益率为\(\mu_0\),找到一个最优的权重向量\(w_{N\times1}\),使得投资组合收益率的方差最小。
假设投资组合可以任意做空,则可以用如下最优化问题表示均值方差模型:
其中,\(e\)是\(N\times1\)的单位向量。
拉格朗日乘数法求解最优化问题¶
对于上述带有等式约束的最优化问题,写出对应的拉格朗日函数:
对\(\mathcal{L}\left(w, \lambda_1, \lambda_2\right)\)的三个自变量求一阶偏导,并令其等于 0:
由公式\(\eqref{1}\)可知:
将公式\(\eqref{4}\)代入公式\(\eqref{2}\)和公式\(\eqref{3}\),得:
整理得:
这是一个关于\(\lambda_1\)和\(\lambda_2\)的线性方程组,为简化表示,可以记:
用消元法可以容易解出:
将\(\lambda_1\)和\(\lambda_2\)代入公式\(\eqref{4}\),得:
这就是最优化问题\(\eqref{0}\)的解。
从最优权重向量到有效前沿曲线¶
由最优化问题\(\eqref{0}\)可知,每一个预期收益水平\(\mu_0\)都对应一个最优权重\(w^\ast\)。在\(w^\ast\)下,投资组合的⽅差为(详细推导见公式\(\eqref{13}\)):
可⻅,\(\sigma^2\)是关于\(\mu_0\)的二次函数。但有效前沿曲线的横轴是\(\sigma\),而不是\(\sigma^2\)。对公式\(\eqref{10}\)做一定的变换,可得如下形式:
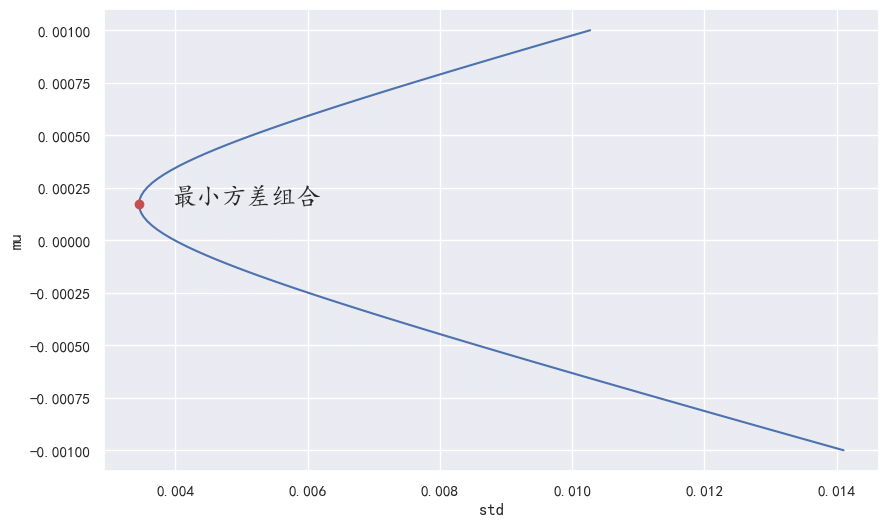
因此\(\mu_0\)关于\(\sigma\)的函数图像是一个双曲线。
最小方差组合¶
由公式\(\eqref{10}\)可知,当
时,\(\sigma^2\left(\mu_0\right)\)取最小值。
将公式\(\eqref{12}\)代入公式\(\eqref{9}\),可得最小方差组合的权重向量。
数值模拟¶
基于 16 个全球指数的历史日线数据,计算有效前沿曲线。
import qstock as qs
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["KaiTi"]
plt.rcParams["axes.unicode_minus"] = False
import seaborn as sb
global_indexs = [
"道琼斯",
"标普 500",
"纳斯达克",
"恒生指数",
"英国富时",
"法国 CAC40",
"德国 DAX",
"日经 225",
"韩国 KOSPI",
"澳大利亚标普 200",
"印度孟买 SENSEX",
"俄罗斯 RTS",
"加拿大 S&P",
"台湾加权",
"美元指数",
"路透 CRB 商品指数",
]
df = qs.get_price(global_indexs, start="20200101")
# 将数据转换为日收益率
df = df.pct_change().dropna()
# 计算历史收益率均值,作为预期收益率
mu = df.mean()
# 计算历史收益率协方差矩阵,作为预期协方差矩阵
cov = df.cov()
100%|██████████| 16/16 [00:03<00:00, 4.65it/s]
标普500 0.000340
道琼斯 0.000306
纳斯达克 0.000351
韩国KOSPI 0.000126
英国富时全股 0.000051
德国DAX30 0.000218
澳大利亚标普200 0.000122
法国CAC40 0.000239
美元指数 0.000114
加拿大S&P/TSX 0.000254
印度孟买SENSEX 0.000626
俄罗斯RTS -0.000192
台湾加权 0.000294
恒生指数 -0.000306
路透CRB商品指数 0.000604
日经225 0.000239
dtype: float64
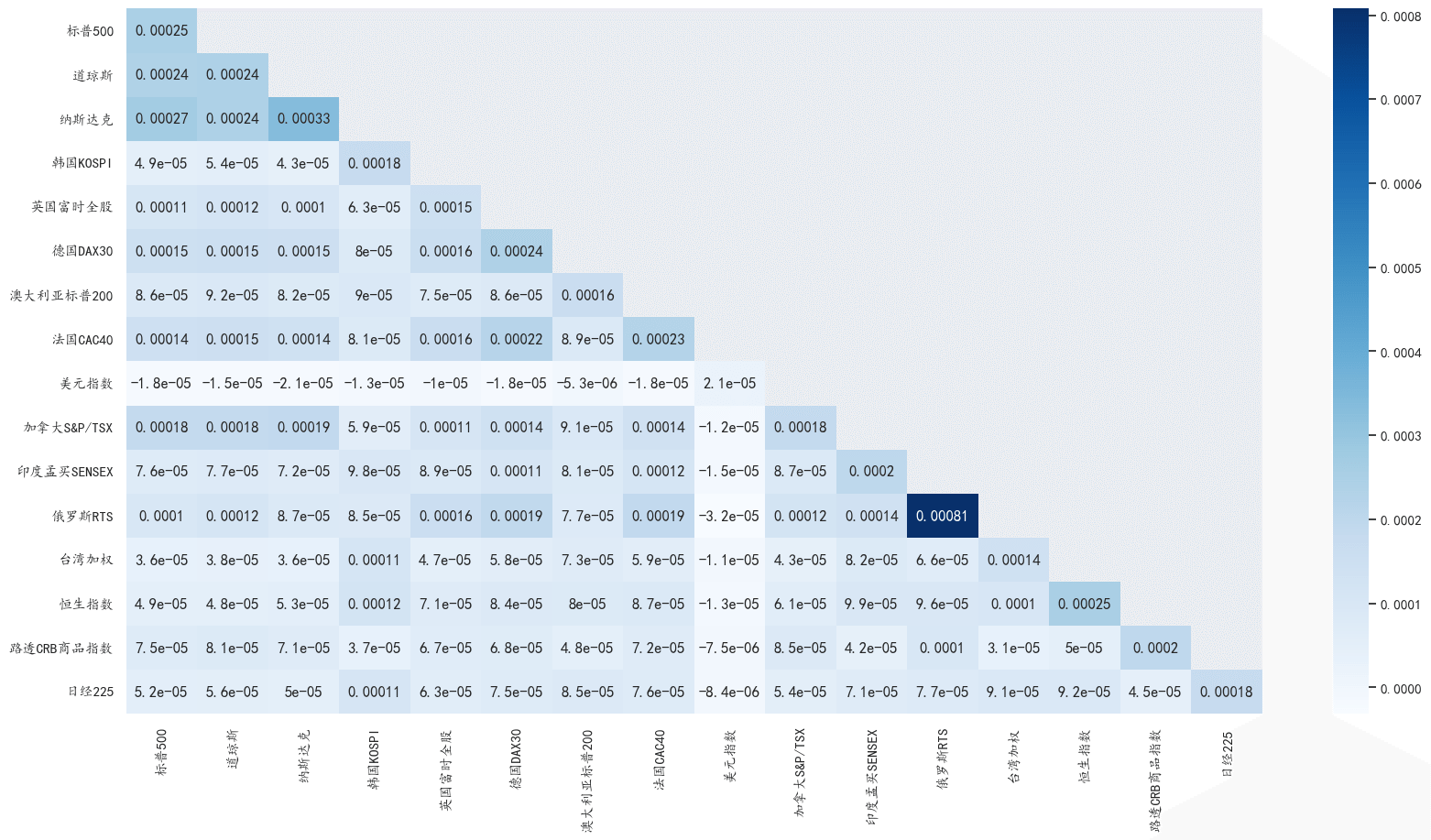
# 历史协方差矩阵热力图
# 设置图片大小
fig, ax = plt.subplots(figsize=(20, 10))
# 生成热力图。cmap 是颜色,annot 是是否显示相关系数,mask 是上三角形矩阵
# 生成 mask,覆盖上三角形矩阵,包括对角线
matrix = np.triu(cov, k=1)
sb.heatmap(cov, cmap="Blues", annot=True, mask=matrix)
plt.show()
def get_optimal_weight(mu, cov, mu_0):
"""
Args:
mu: 期望收益率
cov: 协方差矩阵
mu_0: 给定的目标收益率
Returns:
optimal_weight: 最优权重
"""
# 协方差矩阵的逆
cov_inv = np.linalg.inv(cov)
# 单位向量
ones = np.ones(len(mu))
# 生成 A、B 和 C
a = ones.dot(cov_inv).dot(ones)
b = ones.dot(cov_inv).dot(mu)
c = mu.dot(cov_inv).dot(mu)
# 计算 lambda_1
lambda_1 = (b * mu_0 - c) / (a * c - b**2)
# 计算 lambda_2
lambda_2 = (b - a * mu_0) / (a * c - b**2)
# 计算最优权重
optimal_weight = -lambda_1 * cov_inv.dot(ones) - lambda_2 * cov_inv.dot(mu)
return optimal_weight
# 最小方差组合
# 协方差矩阵的逆
cov_inv = np.linalg.inv(cov)
# 单位向量
ones = np.ones(len(mu))
# 生成 A、B 和 C
a = ones.dot(cov_inv).dot(ones)
b = ones.dot(cov_inv).dot(mu)
# 计算最小方差组合的预期收益率
u_min_var = b / a
# 计算最小方差组合权重
w_min_var = get_optimal_weight(mu, cov, u_min_var)
# 计算最小方差组合的预期标准差
std_min_var = np.sqrt(w_min_var.T.dot(cov).dot(w_min_var.T))
# 对不同的目标收益率,计算最优权重
mu_0_list = np.linspace(-0.001, 0.001, 100)
optimal_weight_list = np.array(
[get_optimal_weight(mu, cov, mu_0) for mu_0 in mu_0_list]
)
# 计算有效前沿
std_list = [
np.sqrt(optimal_weight.T.dot(cov).dot(optimal_weight.T))
for optimal_weight in optimal_weight_list
]
# 绘制有效前沿
# plt.style.use('seaborn')
plt.figure(figsize=(10, 6))
plt.plot(std_list, mu_0_list)
plt.plot(std_min_var, u_min_var, "ro")
# 文字注释
plt.text(std_min_var + 0.0005, u_min_var, "最小方差组合", fontsize=18)
plt.xlabel("std")
plt.ylabel("mu")
plt.show()