使用下一个非空值的平摊值填充¶
本文记录了一个数据处理的小项目。需求如下:
-
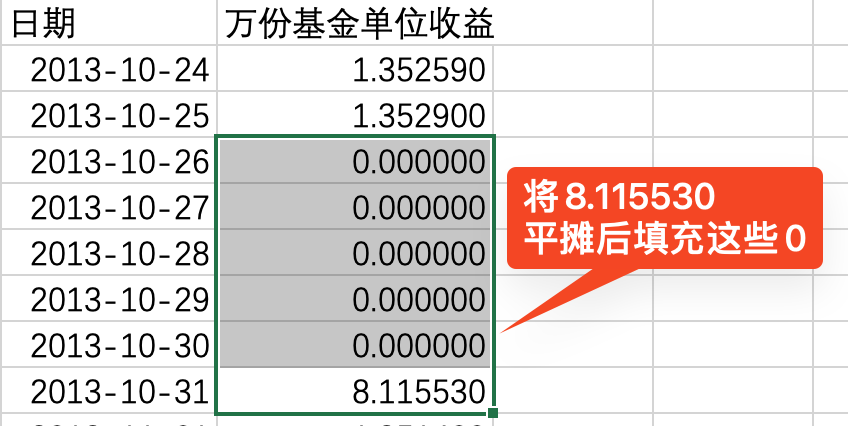
一列数据中 存在零值 。
-
我们需要 用下一个非零值进行填充 。
- 用于填充的值 是“下一个非零值”除以“这一段零值的长度 +1”,也就是将下一个非零值平摊后进行填充。
本文还记录了如何向同一个工作簿中导出多个工作表。
导入包¶
读取数据¶
- 指定
sheet_name=None,可以读取所有工作表。
填充数据¶
关键步骤为:
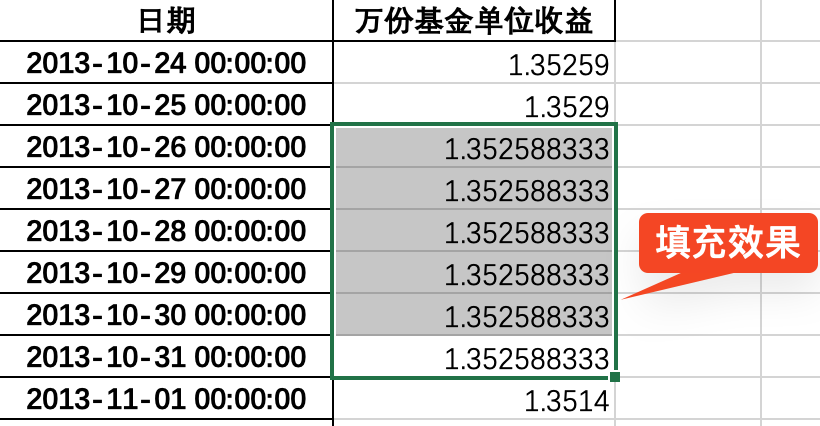
- 创造分组列,用于指定:哪些日期是应该被同一个值进行填充的?这里将数据倒转过来,计算是否不等于 0 得到布尔值,再求
.cumsum(),最后再将数据倒转过来。 - 将 0 用
np.NaN进行填充。 - 使用
transform方法进行分组计算:同一个组应该被同一个值进行填充。 - 填充的值应该用
x.sum() / len(x),而不是x.mean(),因为x.mean()会忽略空值再计算均值,这样就达不到“平摊”的效果。
for fund in data:
df = data[fund]
# 创建分组列
df["分组"] = (df[::-1]["万份基金单位收益"] != 0).cumsum()[::-1]
# 把 0 替换为 NaN
df["万份基金单位收益"] = df["万份基金单位收益"].replace(0, np.NaN)
# 使用 transform 方法进行分组计算
df["万份基金单位收益"] = df.groupby("分组")["万份基金单位收益"].transform(lambda x: x.sum() / len(x))
# 导出数据,向同一个工作簿中导出多个工作表
with pd.ExcelWriter(
"./data.xlsx", mode="a", engine="openpyxl", if_sheet_exists="replace"
) as writer:
df["万份基金单位收益"].to_excel(writer, sheet_name=fund)
向同一个工作簿中导出多个工作表
with pd.ExcelWriter("./data.xlsx", mode='a', engine='openpyxl', if_sheet_exists='replace') as writer:
df.to_excel(writer, sheet_name='XXX')
-
pd.ExcelWriter("./data.xlsx", mode='a', engine='openpyxl', if_sheet_exists='replace'):这是创建一个 ExcelWriter 对象的语句。"./data.xlsx"是要写入的 Excel 文件的路径。mode='a'表示以追加模式打开文件,如果文件不存在,将创建一个新文件。engine='openpyxl'指定使用 openpyxl 引擎进行写入操作,openpyxl 是一个用于读写 Excel 文件的库。if_sheet_exists='replace'表示如果指定的 sheet_name('XXX')已经存在,则替换该 sheet。 -
with writer::这是一个上下文管理器,用于确保在代码块执行完毕后自动关闭 ExcelWriter 对象。这样可以确保在写入完成后,Excel 文件被正确保存和关闭。 -
df.to_excel(writer, sheet_name='XXX'):这是将 DataFrame 写入 Excel 文件的语句。writer是 ExcelWriter 对象,sheet_name='XXX'是要将 DataFrame 写入的工作表名称。to_excel()方法将 DataFrame 写入指定的工作表。
综合起来,这段代码的作用是将 DataFrame(df)写入名为 'XXX' 的工作表中,并将结果保存到 Excel 文件(data.xlsx)中。如果 'XXX' 工作表已经存在,则替换该工作表。