GPT 论文精读笔记¶
Generative Pre-trained Transformer(GPT)系列是由 OpenAI 提出的非常强大的预训练语言模型,这一系列的模型可以在非常复杂的 NLP 任务中取得非常惊艳的效果,例如文章生成,代码生成,机器翻译,问答等,而完成这些任务甚至 并不需要有监督学习进行模型微调 。
本文梳理了 GPT 系列文章中介绍的的关键技术,包括:
- GPT-1 的解码器、微调、输入形式;
- GPT-2 的 Zero-shot 和 Prompt;
- GPT-3 的 Few-shot;
- Instruct GPT 如何通过基于人类反馈的强化学习生成有帮助的和安全的文本。
GPT-1¶
提出动机¶
在自然语言处理任务中,存在大量无标签的语料数据,而有标签的语料数据相对较少,因此基于有监督训练的模型性能的提升大大受限于数据集。为了解决这个问题,作者提出:
先在大量的无标签数据上训练一个语言模型,然后再在下游具体任务的有标签数据集上进行微调。
使用没有标注的文本进行建模的困难¶
- 应该设计何种目标函数?对于不同的子任务来说,有不同的函数适合作为优化目标。一个目标函数在一些子任务上表现较好,但可能在另一些子任务上表现较差,并没有一个通用的目标函数可以适用于所有的子任务。
- 如何将学习到的文本表示迁移到子任务上?并没有一个统一有效的方式使得一种文本表示能够很好地迁移到各种子任务上。
无监督学习使用的语言模型¶

GPT-1 使用的是一个标准的语言模型,也就是:用第 \(i-k\) 到第 \(i-1\) 的一共 \(k\) 个词,来预测第 \(i\) 个词。因此,这个语言模型的目标函数就是 最大化正确预测每个词的概率 。为了让模型能学习到比较长期的文本依赖关系,\(k\) 可能需要取几十到几百,甚至上千。
GPT-1 和 BERT 的区别¶
GPT-1 使用解码器¶
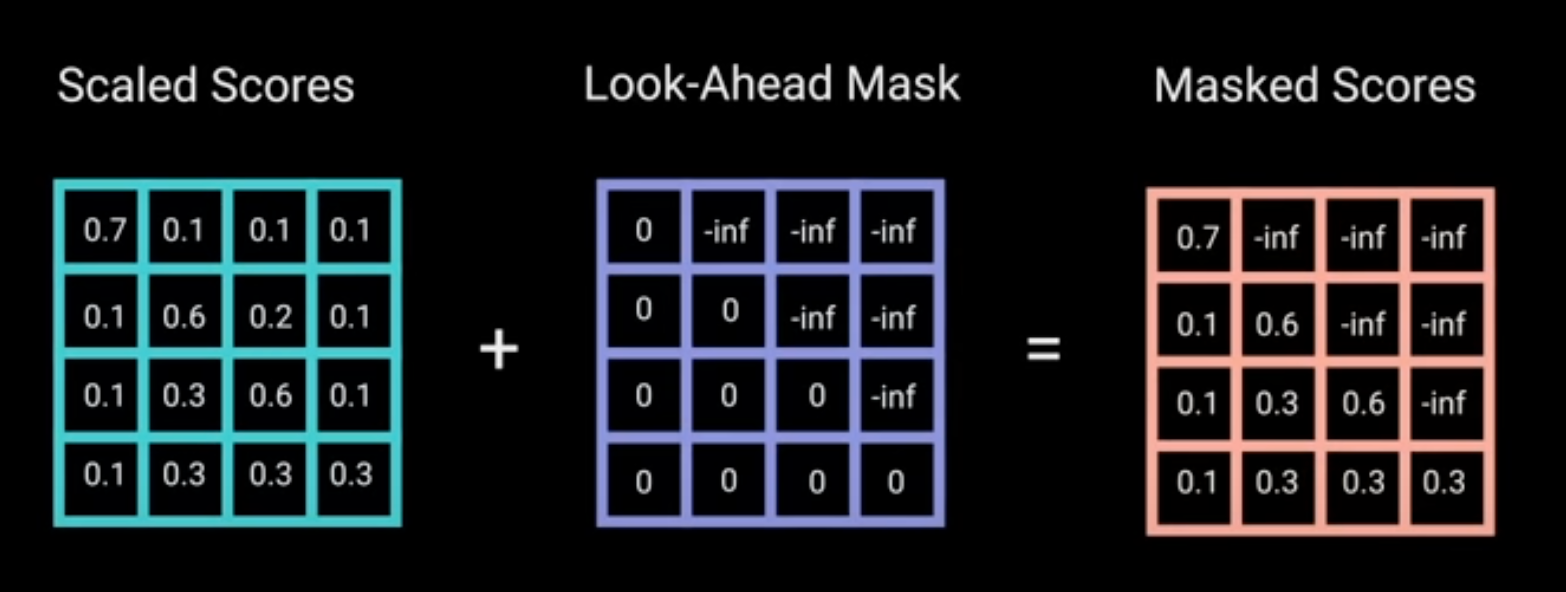
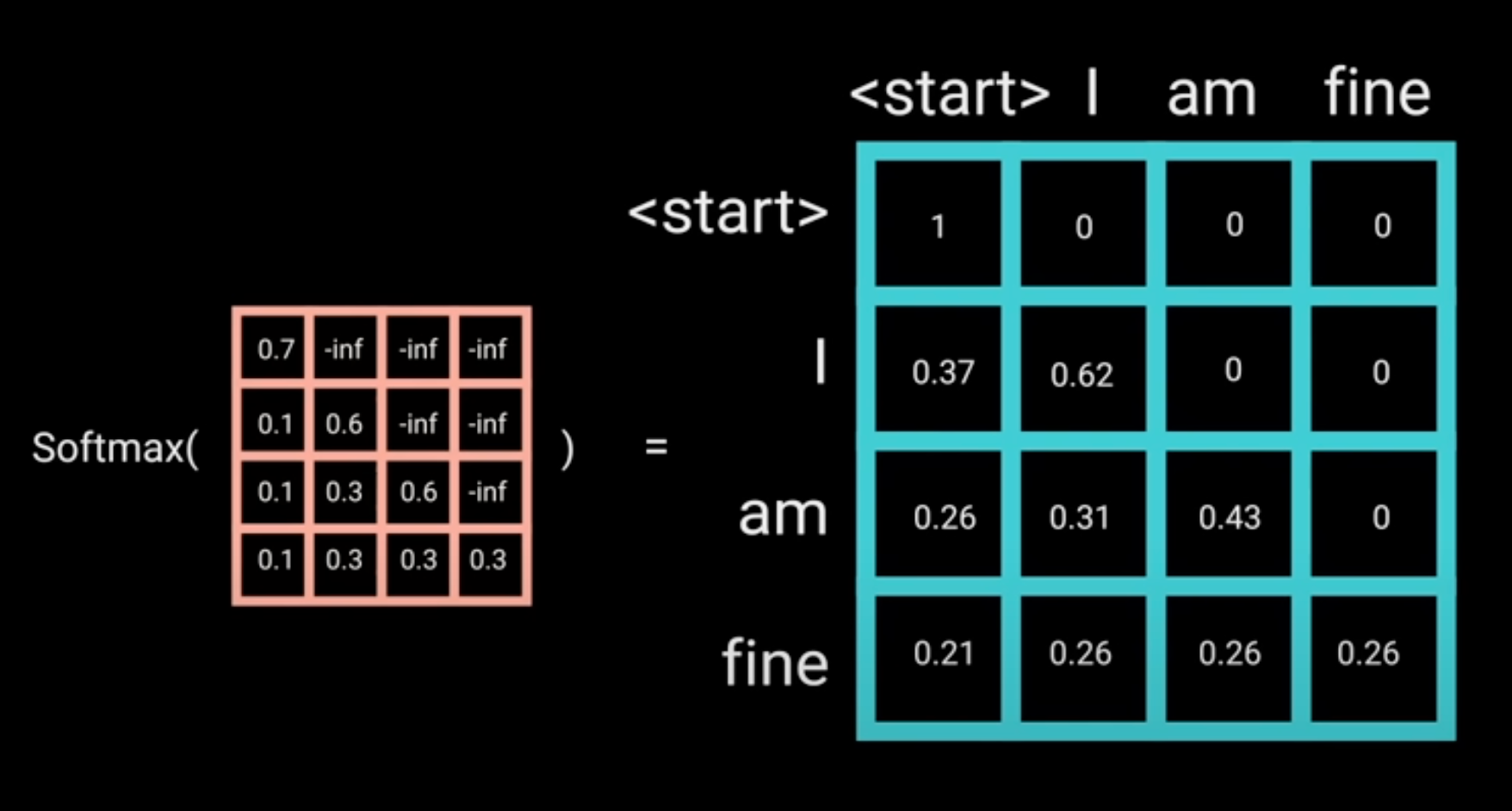
GPT-1 使用的是一个标准的语言模型,在训练时使用 Transformer 的 解码器 。在解码器中,会将一个词之后的文本进行掩码,因此解码器只能看到一个词之前的文本,不能看到之后的文本。
具体来说,在解码器中对输入文本进行 Encoding 时,我们需要将每个词后面位置添加\(-\infty\),使得在应用 Softmax 计算注意力时的值为 0。
参考:https://youtu.be/4Bdc55j80l8

BERT 使用编码器¶
BERT 是一个带掩码的语言模型,在训练时使用 Transformer 的 编码器 。BERT 要完成的任务是:给定一个完整的句子,将中间某个词掩盖,让模型预测中间的词是什么。因此,BERT 在预测时既可以看到待预测词的前面的词,也可以看到后面的词。
训练 GPT 时,模型只能看到前文来预测后文,而 BERT 可以看到上下文来预测中间部分。GPT 得到的输入信息更少,这就导致训练 GPT 比训练 BERT 难很多。
GPT-1 在微调时使用的两个目标函数¶
第一个目标函数是语言模型的目标函数。它最初的目标是:通过前文预测下一个词,希望预测得越准确越好。(注意:微调只是不改变 Transformer 模型结构,但会改变 Transformer 模型参数,因此 Transformer 层的输出的含义可能并不是“下一个词的概率”了。)
第二个目标函数是标准的分类目标函数。它的目标是:在下游分类任务中,将有标注的数据的标注预测得越准确越好。
虽然在微调的时候,我们只关心分类的精度,也就是上述的 \(L_2(\mathcal{C})\) ,但作者发现将语言模型的目标函数 \(L_1(\mathcal{U})\) 作为一个辅助目标函数是有帮助的,可以提升监督模型的泛化性并加速收敛。所以,我们的优化函数变成了:
其中 \(\lambda\) 是一个超参数,一般可以设定为 \(0.5\)。
个人理解
为什么将语言模型的目标函数 \(L_1(\mathcal{U})\) 作为一个辅助目标函数是有帮助的?
\(L_1(\mathcal{U})\) 优化的目标是:给定前面的词,预测下一个词是否准确。那么,如果“预测下一个词”这个任务做得非常好,说明模型对整段文字的理解很到位,那么在最终的分类问题中也能表现得更好。
需要注意的是,以上只是简单的直觉理解。实际上,当应用不同的下游任务时,微调的过程会使得 Transformer 中的参数发生改变,因此 Transformer 层的输出的含义可能并不是“下一个词的概率”了。
通过构造不同的输入形式,以适应不同的下游任务¶
对于不同的下游任务,将数据转换成统一的形式送入预训练好的语言模型,再接一层线性层进行分类等。可以发现,在微调时,仅需要对预训练的语言模型做很小的结构改变,即加一层线性层,即可方便地应用于下游各种任务。
具体来说,为输入的序列添加特殊的字符:Start、Delim和 Extract(当然,并不是直接把这几个字符插入到文本中,而是用特殊的字符,确保不会与文章本身发生混淆),这样就构造好了输入数据。虽然预训练模型没有见过这些特殊字符,但微调时包含了这些特殊字符,因此模型是可以认识这些特殊字符的。
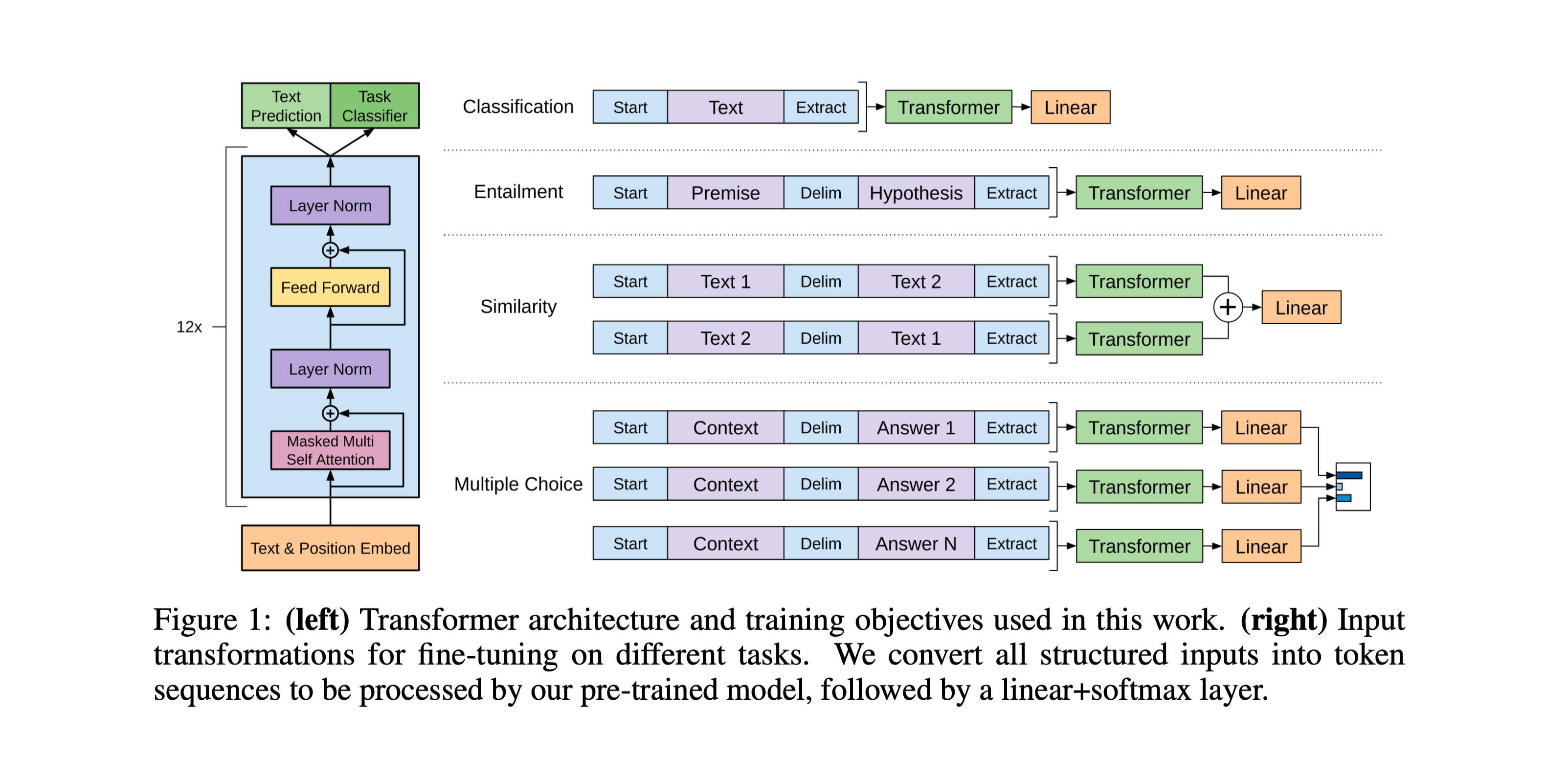
具体讲解可参考:https://www.bilibili.com/video/BV1AF411b7xQ?t=1581.1
GPT-2¶
GPT-1 和 BERT 都是先在大量无标签数据上预训练语言模型,然后在每个下游任务上进行有监督的微调,但是这样也有两个问题:
- 对于下游的每个任务,还是要重新训练模型。
- 需要收集有标签的数据。
这样导致在拓展到新任务上时还是有一定的成本。因此,GPT-2 提出利用语言模型做下游任务时,不需要下游任务的任何标注信息,即 zero-shot 设定,也不用训练模型。也就是实现一劳永逸:训练一个模型,在多个任务上都能用。当然,要实现一劳永逸是有代价的,GPT-2 的参数量就达到了 15 亿个,比 GPT-1 的 1.17 亿 个多了 10 几倍。
Zero-shot¶
Zero-shot 是指:在应用下游任务时,不需要用到下游任务的任何标注信息,也不需要额外训练模型。
在下游任务的输入形式上,GPT-2 与 GPT-1 的区别¶
GPT-1 在做下游任务时会对输入进行构造,引入了Start、Delim、Extract这些特殊字符,而预训练时见到的是自然文本,因此这些特殊字符在预训练时是从来没有出现过的。但因为有微调的环节,所以模型是可以认识这些符号到。
然而 GPT-2 是 zero-shot 的,在做下游任务时,模型不能被调整了,如果还引入一些模型之前没见过的符号的话,模型就会感到很困惑。因此,在构造下游任务的输入时,我们就不能引入模型未见过的符号,而要使得输入像模型预训练时见到的自然文本一样,例如:
-
机器翻译任务:
translate to french, english text, french text。“translate to french”这三个词可以被认为是一个特殊的分隔符,即 Prompt。 -
阅读理解任务:
answer the question, document, question, answer。
为什么加入 Prompt 就能 Zero-shot 地完成下游任务¶
一个可能的原因:
作者在描述数据时提到,在预训练模型的输入数据中,可能就包括一些和下游任务 Prompt 很像的文本。例如,如果预训练模型的输入数据中有 “你好”翻译成英文是 Hello,那么,在下游任务中,将 Prompt 设为“翻译成英文”,模型就能理解下游任务是要做什么了。
GPT-3¶
Few-shot¶
GPT-3 是利用少量样本去学习,也就是 Few-shot。因为人类也不能做到“不看任何样例就能学习”的,而是通过少量样例才能有效地举一反三。
下图对比了三种不同的 Shot(左边)和微调(右边)的区别。微调是需要更新预训练模型的参数的,但 Shot 不用。
-
Zero-shot 是在预测时提供 Task description 和 Prompt, 没有任何 Example ;
-
One-shot 是提供 Task description、 一个 Example 和 Prompt;
- Few-shot 是提供 Task description、 多个 Example 和 Prompt。

由于 GPT-3 庞大的体量,在下游任务进行微调的成本会很大。因此 GPT-3 作用到下游子任务时,不对预训练模型进行任何的梯度更新。
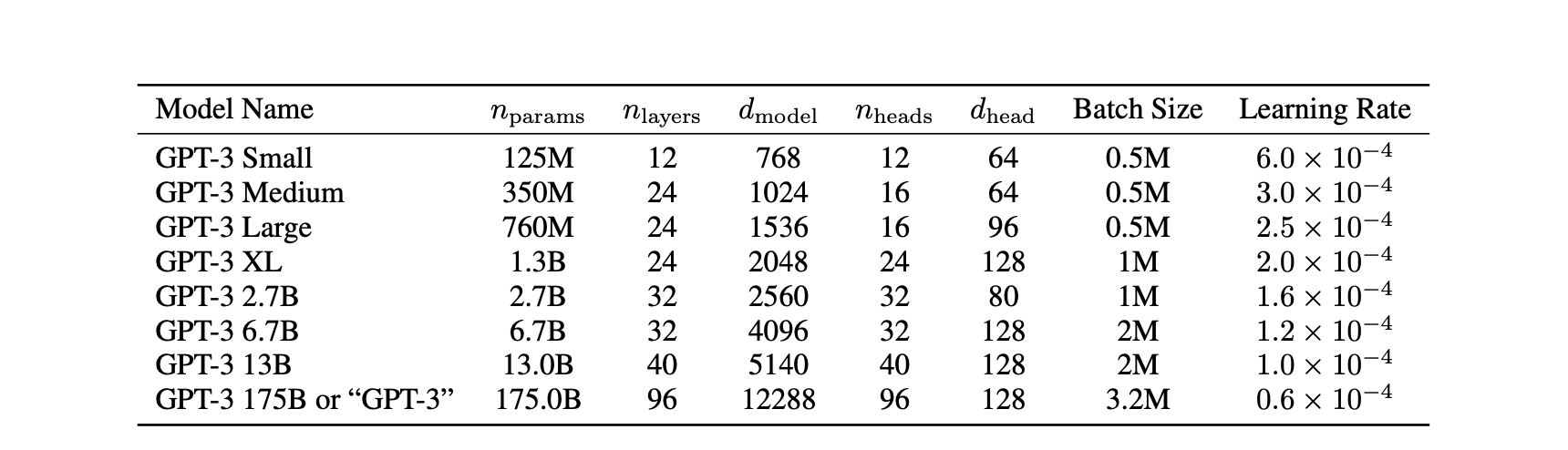
GPT-3 训练了 8 个不同大小的模型,其中最大的模型的参数量达到了 1,750 亿。
InstructGPT¶
语言模型的目标函数没有对齐(aligned),因此会生成有害的言论¶
-
语言模型的目标函数:给定一段文本,预测这段文本的下一个词 。
-
人类希望的目标函数:根据人的指示,生成 有帮助的和安全的 内容。
InstructGPT 的数据标注与训练步骤¶
一共分三步,分别是:有监督的微调(Supervised Fint-tune, SFT)、奖励模型(Reward Model, RM)和强化学习。
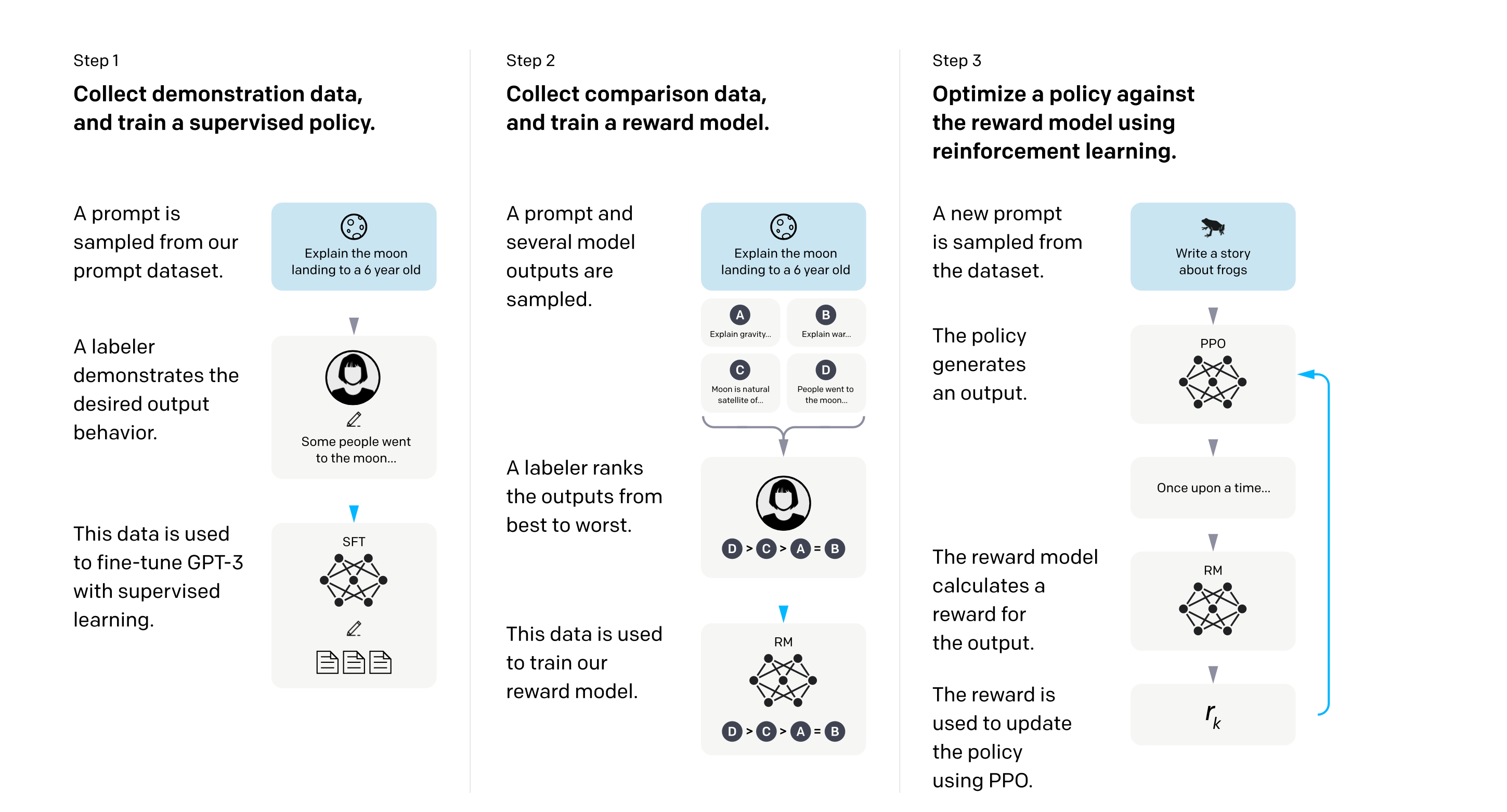
有监督的微调(Supervised Fint-tune, SFT)¶
抽取一个 Prompt, 人工生成回答。这一步和 GPT-3 中的微调是一样的。具体的做法是:将 Prompt 作为输入,将人工生成的回答作为输出,并微调 GPT-3 的模型参数。
奖励模型(Reward Model, RM)¶
抽取一个 Prompt,让模型生成多个回答,再让 人工对这些回答的质量进行排序 。具体做法是:用一个更简化的 GPT 模型(论文中只用了 60 亿个参数的版本)生成 \(K\) 个回答,并人工对 \(K\)(论文中 \(K=9\) )个回答的质量进行排序。奖励模型需要为每一个回答输出一个奖励分数,并且努力使得:若回答 A 的质量比回答 B 的质量高,那么回答 A 获得的奖励分数也应该比回答 B 的奖励分数高。
奖励模型需要分辨出“哪个回答的质量更高”,它将 \(K\) 个回答之间做两两对比,并使用了如下的两两排序损失函数(Pairwise Ranking Loss):
- 红色部分 \({\color{red}{r_\theta\left(x, y_w\right)}}\)下标为 w,w 意味着 win,它代表:人工更加偏好的那个回答,所能得到的奖励分数。
- 蓝色部分 \({\color{blue}{r_\theta\left(x, y_l\right)}}\)下标为 l,l 意味着 lose,它代表:人工更加讨厌的那个回答,所能得到的奖励分数。
- 我们当然希望红色比蓝色高,这样才能区分出不同质量的回答。将两者的差值放到 \(\sigma\) 这个 Sigmoid 函数中后,得到的值在 \(0\) 到 \(1\) 之间,我们希望得到的值越接近 \(1\)。
- 再取 \(\log\),得到的值在 \(-\infty\) 到 \(0\) 之间,我们希望得到的值越接近于 \(0\)。
- 除以 \(\left(\begin{array}{c}K \\2\end{array}\right)\) 是为了防止损失值因 \(K\) 的变化而变化太多。
- 最后再取相反数,得到的值在 \(0\) 到 \(+\infty\) 之间,我们希望得到的值越接近于 \(0\),因此要最小化损失函数的值。
为什么取 \(K=9\) ,而不是前人使用的 \(K=4\) ?
第一,\(K\) 取大一些可以帮助我们在更短的时间内获得更大量的标注数据。
人工对问题做标注时,看懂 Prompt 是需要花大量时间的,但看懂答案并为各个答案进行排序并不需要花费太多时间。例如:若看懂 1 个 Prompt 需要 60 秒钟,看懂 1 个回答需要 10 秒钟。
如果我们取 \(K=4\),那么需要花 \(60+10*4=100\) 秒来得到 4 个排序标注。但如果我们取 \(K=9\),那么只需要花 \(60+10*9=150\) 秒就能得到 9 个排序标注。后者能够得前者两倍多的标注量,但后者花的时间只比前者多了 \(50\%\)。
第二,\(K\) 取大一些更能减少计算损失时的计算量。
若 \(K=9\),在计算损失时,虽然有 \(\left(\begin{array}{c}9 \\2\end{array}\right) = 36\) 项,但实际上只有 \(9\) 项是需要计算的,其他地方都可以重复地用这 \(9\) 项数值。\(K\) 越大,这部分计算节约的时间也就越多。
强化学习¶
接下来我们需要做的是:训练一个强化学习模型,使得模型的输出与人的偏好最接近。也就是说,给定 Prompt \(x\),模型输出一个回答 \(y\),我们希望模型的输出 \(y\) 所能够得到的奖励分数越高越好。
强化学习的目标函数:
第一项是 \(r_\theta(x, y)\),它就是将模型的输入 \(x\) 和输出 \(y\) 放入上一节的奖励模型 RM 后得到的奖励分数。我们希望模型的输出符合人的偏好,也就是希望第一项 越大越好 。
第二项是 \(-\beta \log \left(\pi_\phi^{\mathrm{RL}}(y \mid x) / \pi^{\mathrm{SFT}}(y \mid x)\right)\)。\(\log\) 的部分实际上是:当前进化的模型的输出,与最初的模型(也就是刚刚开始强化学习的模型)的输出,两者之间的 KL 散度。如果两个模型的输出一致,则比值为 \(1\),取 \(\log\) 后为 \(0\)。如果两个模型的输出不一致,则 KL 散度一定大于 \(0\)。
KL 散度是一个期望上的分布差距,目标函数里对 \(D_\pi^{\mathrm{RL}}\) 取期望,而 \(\pi_\phi^{\mathrm{RL}}(y \mid x)\) 放在 \(\log\) 内的分子,因此这就是 KL 散度的定义。
我们只知道刚刚开始强化学习的模型的输出的奖励分数是正确的,但随后模型继续进化,我们并不确定它的奖励分数是否能反映回答的质量。因此,我们希望两个输出的概率分布不要偏离太远,否则第一项的奖励分数可能并不能真正反映出当前进化的模型与人的偏好的接近程度。也就是说,我们希望第二项的 KL 散度越小越好,取相反数后 越大越好 。
以上两项就构成了 PPO(Proximal Policy Optimization)算法。
第三项是 \(\gamma E_{x \sim D_{\text {pretrain }}}\left[\log \left(\pi_\phi^{\mathrm{RL}}(x)\right)\right]\)。它是语言模型的目标函数,即希望多偏向于原始 GPT-3 的输出,也是希望它 越大越好 。
加上这一项后,就构成了 PPO-ptx 模型。