当梯度下降陷入局部最优解¶
应用梯度下降法时,损失函数的值不再发生变化并不一定是找到了全局最优解,可能是陷入了局部最优解。为当前参数加上一个微小扰动,可以帮助跳出局部最优解。

问题背景¶
在应用梯度下降法求解最优参数时,除了设置最大迭代次数,还可以通过损失值的变化情况来判断是否可以终止迭代。
Python
def gradient_descent(self, x, y, alpha=0.5, c=0.5, beta_initial=None):
"""
Args:
x: 所有样本的特征
y: 所有样本的标签
alpha: 回溯线性搜索的参数
c: 回溯线性搜索的参数
beta_initial: 待优化的参数的初始值,默认为全零向量
Returns:
beta: 迭代后的最优参数
"""
# 初始化损失函数值
self.loss = []
# 初始化待优化的参数
if beta_initial is None:
beta = np.zeros(x.shape[1])
else:
beta = beta_initial
# 迭代求解
for k in range(self.K):
# 计算梯度
gradient_beta = self.gradient(x, y, beta, self.lambda_)
# 计算回溯线性搜索的步长
t = 1
while self.f(x, y, beta - t * gradient_beta, self.lambda_) > self.f(
x, y, beta, self.lambda_
) - alpha * t * gradient_beta.T.dot(gradient_beta):
t = c * t
# 更新参数
beta = beta - t * gradient_beta
# 记录损失函数的值
self.loss.append(self.f(x, y, beta, self.lambda_))
# 终止条件:至少迭代了 100 轮,且损失函数的值在最近 2 轮的迭代中变化小于 1e-6
if k > 100 and abs(self.loss[-2] - self.loss[-1]) < 1e-6:
break
# 将参数值小于 1e-3 的置为 0
beta[np.abs(beta) < 1e-3] = 0
return beta
注意,上面的代码中,我设置了最大迭代次数为K=10000,同时也设置了终止条件:
Python
# 终止条件:至少迭代了 100 轮,且损失函数的值在最近 2 轮的迭代中变化小于 1e-6
if k > 100 and abs(self.loss[-2] - self.loss[-1]) < 1e-6:
break
梯度下降法的收敛值与其他两种方法不一致¶
绘制损失函数值随迭代次数的变化情况,发现梯度下降法的收敛速度很快,仅 102 轮迭代便收敛。
随机梯度下降法、坐标下降法的损失函数几乎都收敛到同一位置,约\(0.365\),但梯度下降法的损失函数却约为\(0.4\)。
猜测梯度下降法可能陷入了局部最优解。
加入随机扰动,帮助跳出局部最优¶
不记得在哪里学到的这个方法(可能是吴恩达的机器学习视频,或是某次学术讲座)。在观察到损失函数值不发生变化时,可以对当前参数加上一个随机扰动项,帮助跳出局部最优。
我们需要修改之前终止迭代的代码:
Python
# 改变当前值的条件:至少迭代了 100 轮,且损失函数的值在最近 2 轮的迭代中变化小于 1e-6
if k > 100 and abs(self.loss[-2] - self.loss[-1]) < 1e-6:
# 为每个分量加上噪音 N(0, 1e-2)
beta = beta + np.random.normal(0, 1e-2, beta.shape)
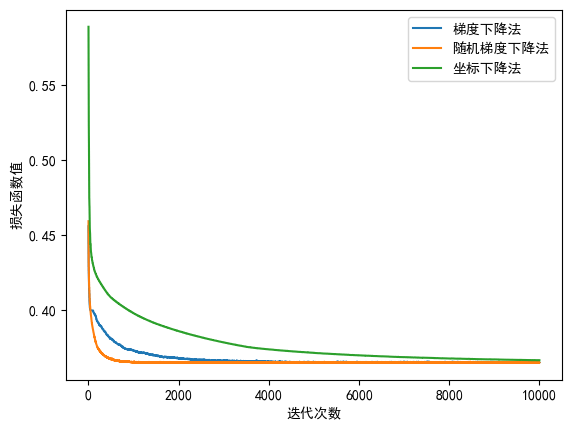
此时三种梯度下降的方法几乎都收敛到同一值,说明随机扰动帮助我们跳出了局部最优!