Jupyter Notebook 恢复历史执行信息与存储执行结果¶
获取历史执行信息¶
问题¶
假如我们已经在 Jupyter 中编写了一些代码,但在计算后发现忘记将结果赋值了。一般在这种情况下,我们会再次执行该单元并生成结果完成赋值。
那么如何不重新运行而直接使用结果呢?
解决方法¶
方法一:_ 变量¶
在 Python 交互式命令行 (直接执行 python 命令进入的交互环境) 里,_ 变量有一层特殊含义:默认保存我们上一次输入的表达式返回的值:
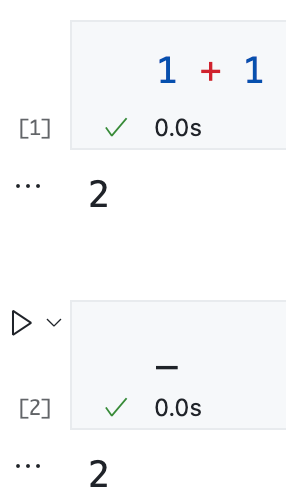
因此可以用 _ 变量查看上一次输入的表达式返回的值。
方法二:Out 变量¶
当我们在 Jupyter 中执行一个单元格时,会看到单元格之外的 In[2]:,结果输出以后单元格外也会出现 Out[2]:,如下所示。

在 IPython 中:
Out是一个标准的 Python 字典,用于存储单元格输出的结果。此时的字典中,键 (key) 就是2,即单元格执行次数的 id(id 只会按 1,2,..,n 的顺序依次增加,无论执行什么单元格),而值 (value) 则为单元格的执行结果。
In是一个 Python 列表,存储着按顺序执行的代码。
我们再次执行以下代码,发现执行代码和结果竟都可以复现。
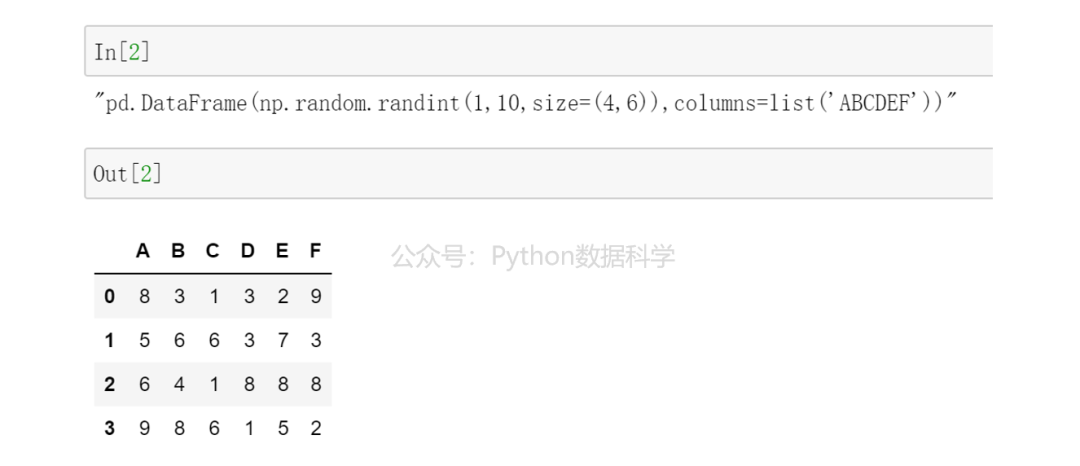
也就是说,我们做的任何操作以及对应的结果,Jupyter 都在做着笔记和记录,而且每个记录都是独立存在,id 依次增加保证不会被覆盖。所以当我们不小心犯错或者找不到之前结果的时候,就都可有迹可循了。
存储执行结果¶
问题¶
在用 Jupyter 的时候,经常由于某种原因,需要重新启动内核。但一般在重新启动之前,会将数据对象保存下来,以免再次运行后重新再跑一遍。
如果代码比较多,数据量比较大,那就是一个非常耗时的过程。而且单独存储每个重要的数据对象也是比较麻烦的。
解决方法:魔法命令 store¶
magic 魔法命令中的store可以完美解决这个问题。它可以让我们在即使重新启动内核后,也可以获得重启之前计算得到的对象和结果。这就避免了我们反复将对象转储到磁盘的麻烦。
下面演示如何使用store命令。
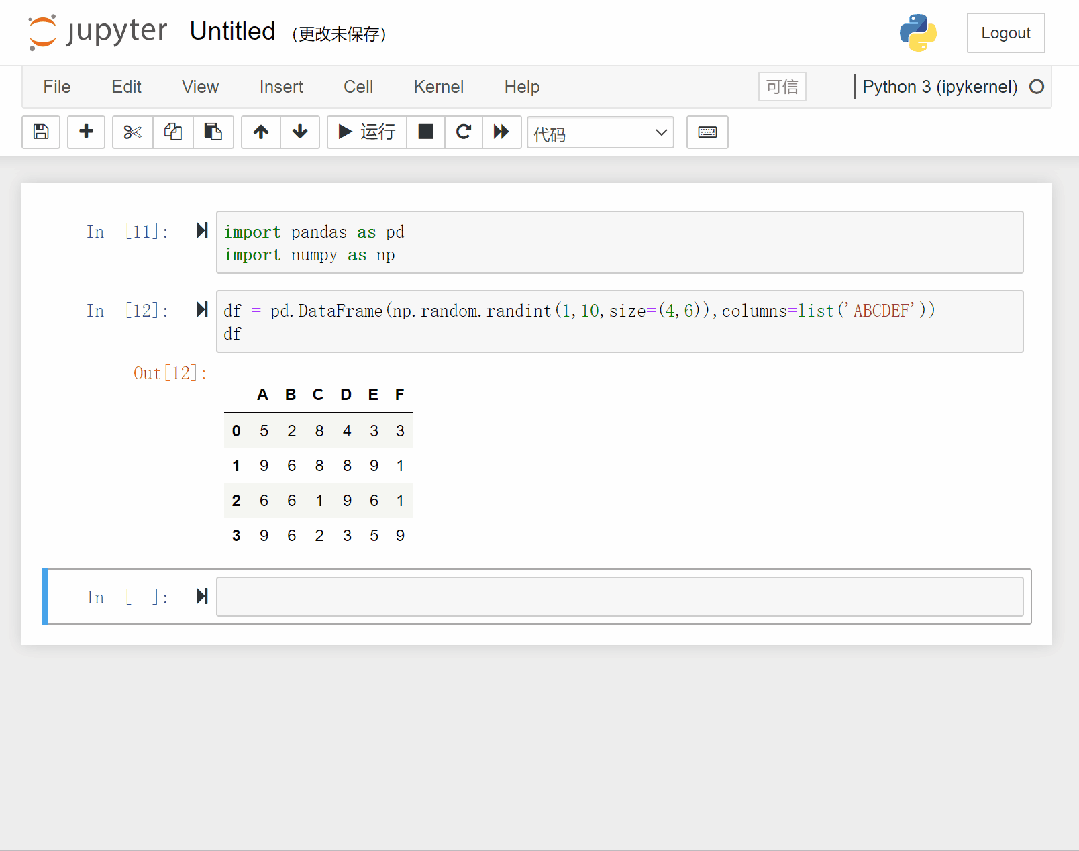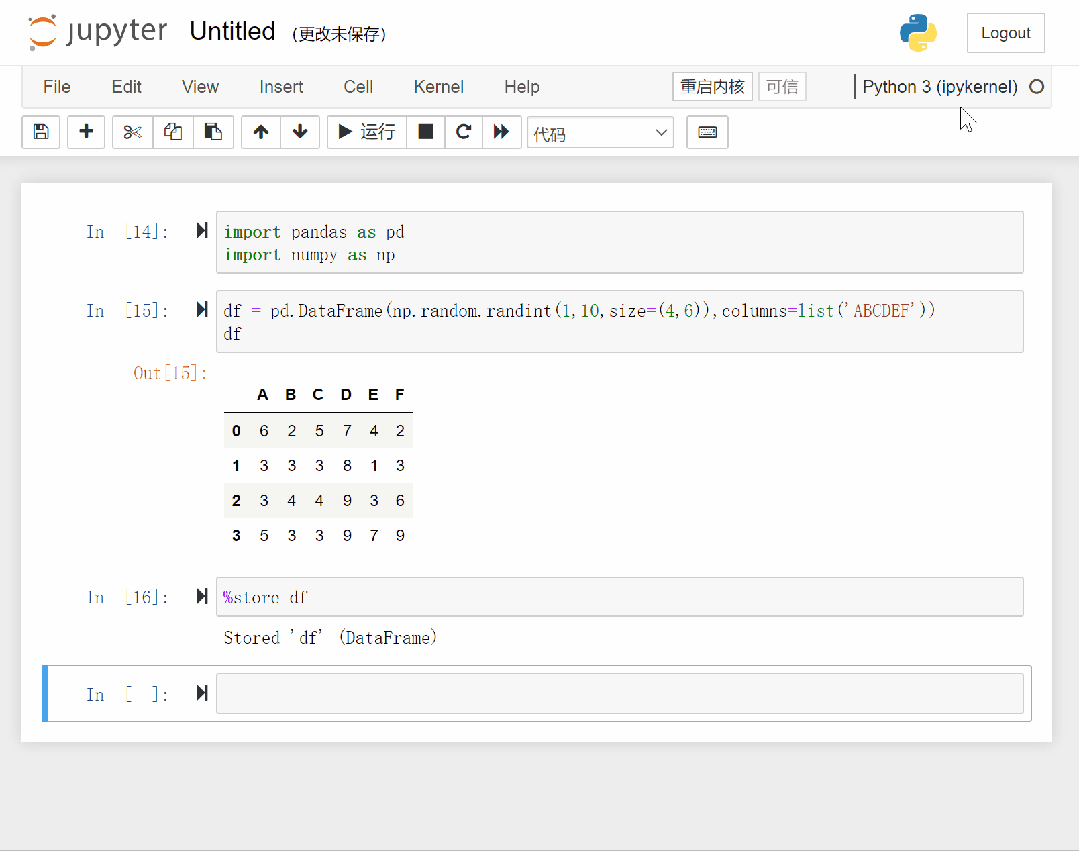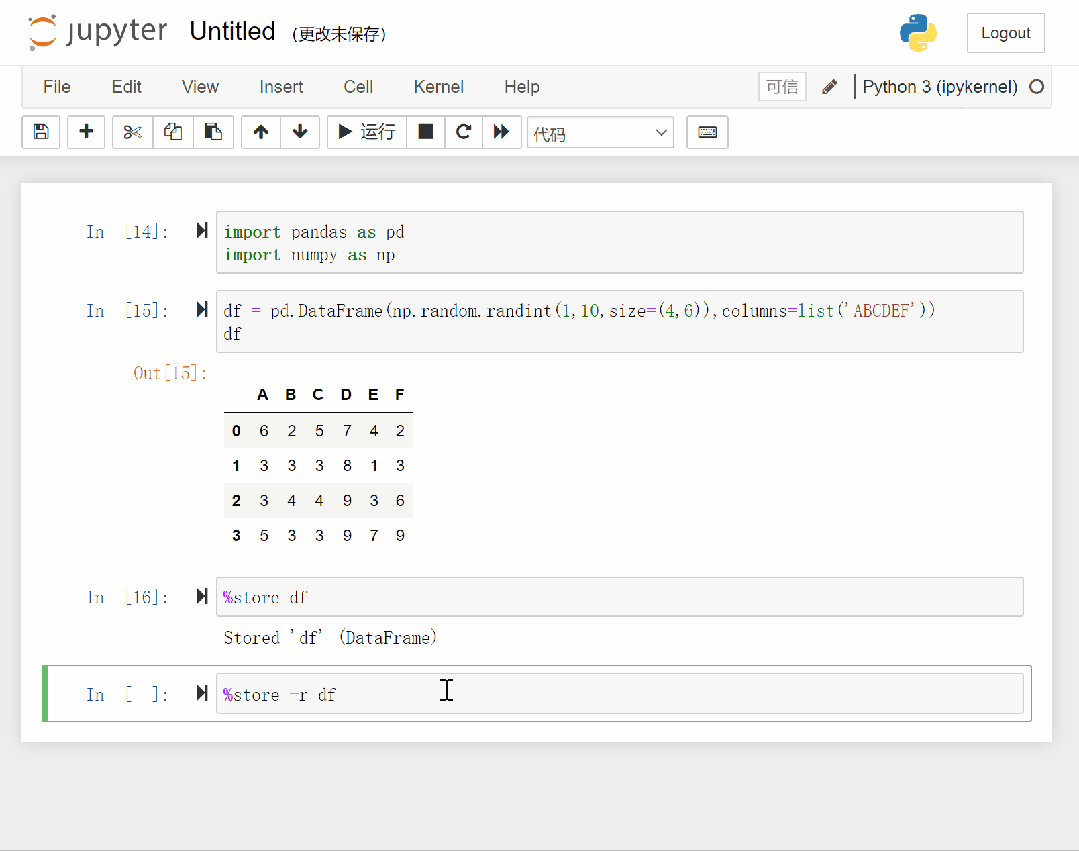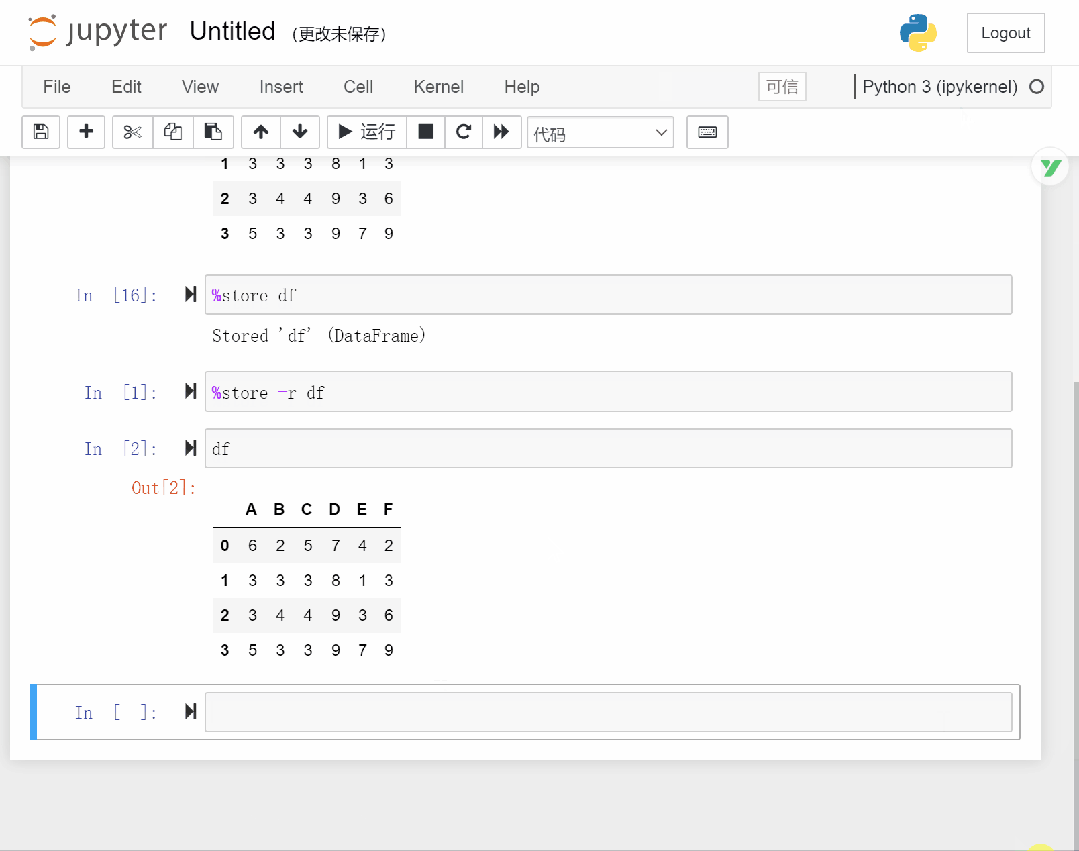
可以看到,我们首先创建一个 dataframe 对象并赋给 df,然后将 df 用store保存,当重启内核后,再通过store命令重新获取。
store命令的具体操作如下。