Python @lru_cache 内置 LRU 缓存¶
Python 内置模块 functools 的一个高阶函数 @lru_cache 是一个为函数提供缓存功能的装饰器,缓存 maxsize 组传入参数,在下次以相同参数调用时直接返回上一次的结果。用以节约高开销或 I/O 函数的调用时间。
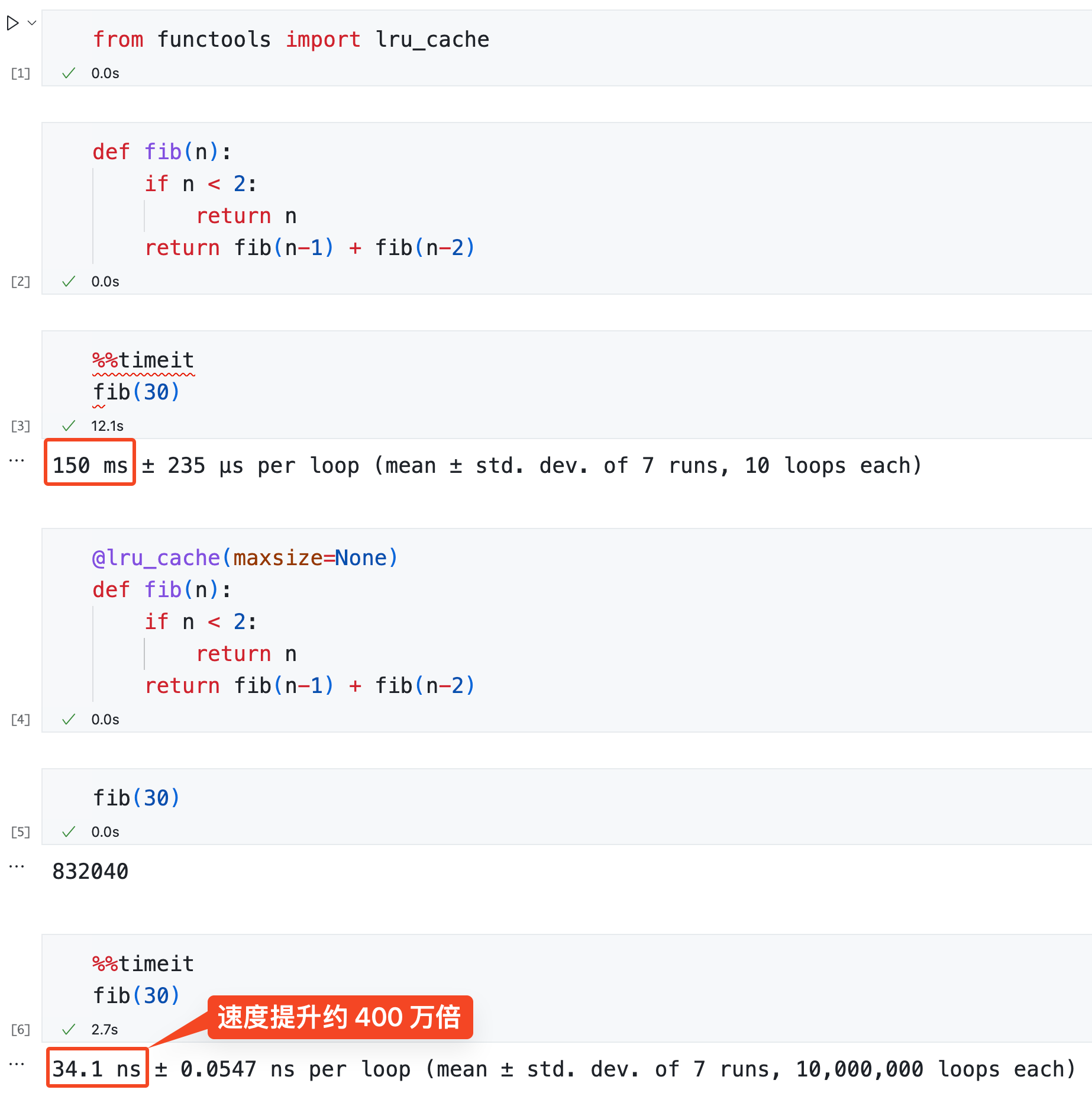
在递归计算斐波那契数列的第 30 项时,使用 @lru_cache 可使速度提升约 400 万倍。
相关教程视频:
语法解析¶
@lru_cache 的用法有两种形式:
from functools import lru_cache
lru_cache(user_function)
@lru_cache(maxsize=128, typed=False)
def user_function(x):
pass
它实现了最近最少使用(Least-recently-used)缓存装饰器,缓存函数的参数必须是可哈希的。最近最少使用的机制是如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小,LRU 算法选择将最近最少使用的数据淘汰,保留那些经常被命中的数据。
参数解释¶
以下是它的几个参数的说明:
user_function:如果指定,它必须是一个可调用对象。maxsize:存储在缓存中的元素数,默认 128 个,如果设为None,LRU 特性将被禁用且缓存可无限增长。typed:布尔值,默认为Flase。- 如果
typed被设为True,则不同类型的函数参数将被分别缓存。例如,f(3)和f(3.0)将总是会被当作具有 不同结果的不同调用 。 - 如果
typed为False,则具体实现通常会把它们当作 相同调用并且只缓存一个结果,虽然并不一定总是会这样做。
- 如果
属性方法¶
被装饰的函数会成为 functools._lru_cache_wrapper 对象,它有以下属性和方法:
f.cache_parameters():缓存参数。f.cache_info():当前缓存情况,返回一个namedtuple,包含缓存使用、未使用、长度、最大长度,如CacheInfo(hits=2, misses=1, maxsize=128, currsize=1)。f.cache_clear():清除缓存。f.__wrapped__():未被装饰的参数。
如果想使用未被装饰的参数可以用 f.__wrapped__()。
缓存机制¶
缓存逻辑¶
-
LRU(最久未使用算法)缓存在最近的调用是即将到来的调用的最佳预测值时性能最好(例如,新闻服务器上最热门文章倾向于每天更改)。缓存的大小限制可确保缓存不会在长期运行进程如网站服务器上无限制地增长。
-
一般来说,LRU 缓存只在当你想要重用之前计算的结果时使用。因此,用它缓存具有副作用的函数、需要在每次调用时创建不同、易变的对象的函数或者诸如
time()或random()之类的不纯函数是没有意义的。 -
由于使用了字典存储缓存,所以该函数的固定参数和关键字参数必须是可哈希的,针对于列表等不可哈希的对象的时候是不可用的。
-
缓存会保持对参数的引用并返回值,直到它们结束生命期退出缓存或者直到缓存被清空。
-
不同模式的参数可能被视为不同从而产生多个缓存项,例如,
f(a=1, b=2)和f(b=2, a=1)因其参数顺序不同,可能会被缓存两次。
相关功能¶
允许 lru_cache 装饰器被直接应用于一个用户自定义函数,让 maxsize 保持其默认值 128 个元素。
被包装的函数配有一个 cache_parameters() 函数,该函数返回一个新的 dict 用来显示 maxsize 和 typed 的值,这只是出于显示信息的目的,对缓存功能没有任何影响。
为了帮助衡量缓存的有效性以及调整 maxsize 形参,被包装的函数会带有一个 cache_info() 函数,它返回一个 named tuple 以显示 hits, misses, maxsize 和 currsize。
该装饰器也提供了一个用于清理/使缓存失效的函数 cache_clear()。
原始的未经装饰的函数可以通过 __wrapped__ 属性访问。它可以用于检查、绕过缓存,或使用不同的缓存再次装饰原始函数。
案例¶
计算元音字母数量¶
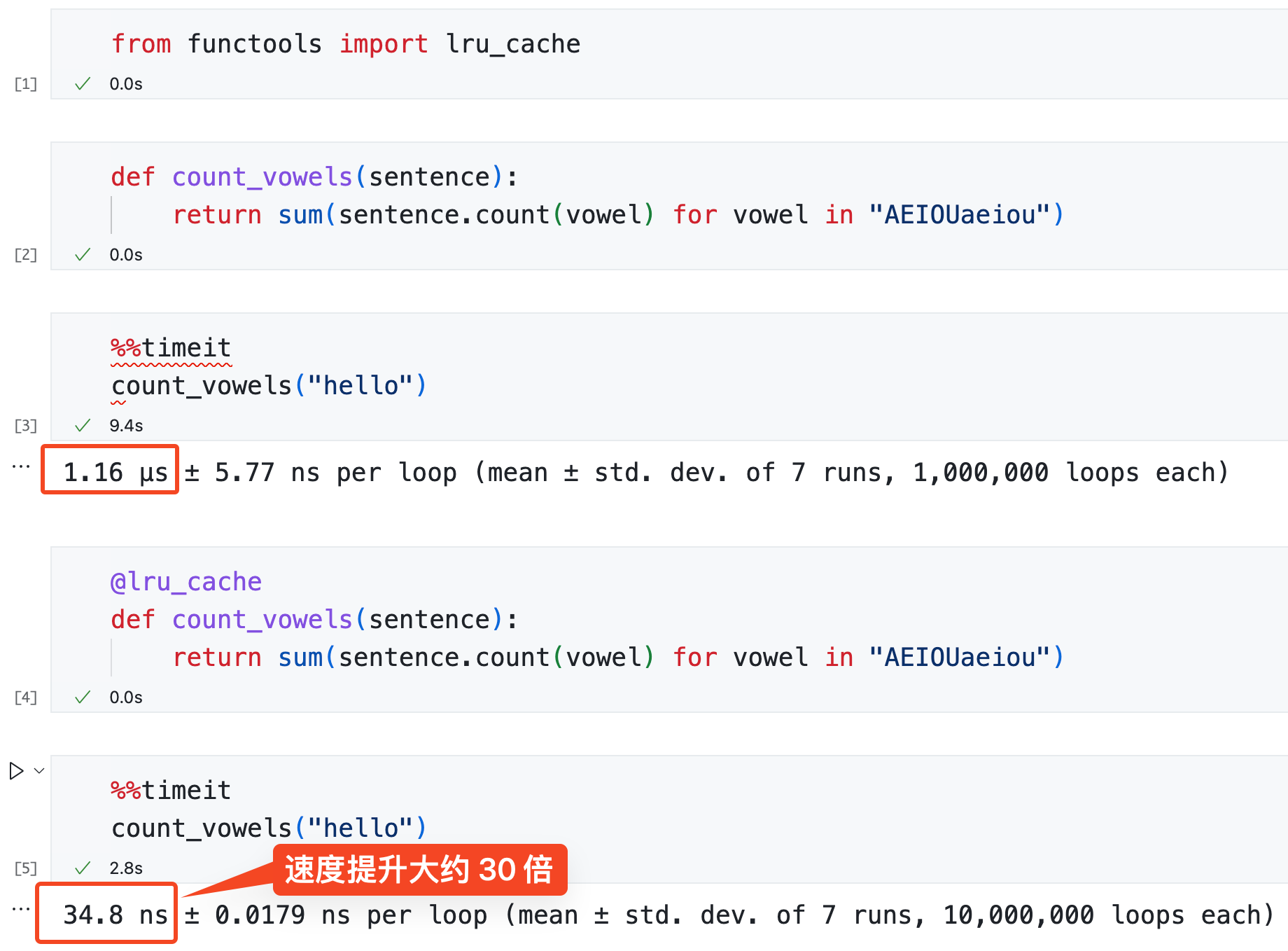
以下是一个计算英文语句中元音字母的数量的方法,由于会频率调用计算,每次进行缓存,对于之前计算过的直接从缓存读取。代码如下:
from functools import lru_cache
@lru_cache
def count_vowels(sentence):
return sum(sentence.count(vowel) for vowel in "AEIOUaeiou")
count_vowels("hello")
count_vowels("hello")
斐波那契数列¶
以下是使用缓存通过动态规划计算斐波那契数列的例子。
@lru_cache(maxsize=None)
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n-2)
>>> [fib(n) for n in range(16)]
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610]
>>> fib.cache_info()
CacheInfo(hits=28, misses=16, maxsize=None, currsize=16)
属性方法¶
被装饰的函数会有几个方法,以上例我们进行查看:
from functools import lru_cache
@lru_cache
def count_vowels(sentence):
return sum(sentence.count(vowel) for vowel in "AEIOUaeiou")
count_vowels
# <functools._lru_cache_wrapper at 0x7fdb30de8300>
# 缓存参数
# 注意:Python 3.9 新版功能:新增函数 cache_parameters()
count_vowels.cache_parameters()
# {'maxsize': 128, 'typed': False}
# 缓存信息初始量
count_vowels.cache_info()
# CacheInfo(hits=0, misses=0, maxsize=128, currsize=0)
# 执行 3 次
count_vowels("hello")
# 2
# 使用未被封装的原函数(不使用缓存,也不缓存)
count_vowels.__wrapped__("hello")
# 2
# 缓存被使用两次,一次没用(第一次执行时),大小为 1
count_vowels.cache_info()
# CacheInfo(hits=2, misses=1, maxsize=128, currsize=1)
# 清除缓存
count_vowels.cache_clear()
# 无返回 None
# 再看看缓存情况
count_vowels.cache_info()
# CacheInfo(hits=0, misses=0, maxsize=128, currsize=0)