基于 Spark RDD 的电影点评数据分析¶
学习 Spark 的基本用法,利用 Spark 的 map、sort、join、reduce 等功能,对电影点评数据进行简单的分析。

初始化 Spark Context¶
Python
import findspark
# 初始化 spark 环境,系统全局环境变量已经设置 SPARK_HOME, PYSPARK_PYTHON 则不需要给此函数传入环境变量。
findspark.init()
from pyspark.conf import SparkConf
from pyspark.sql import SparkSession
appname = "rdd movies - 1. top 10 - user_47" # 任务名称(将 user_xx 替换成你的号码)
master = "yarn" # spark 集群地址
# spark 资源配置
conf = SparkConf().setAppName(appname).setMaster(master)
spark = SparkSession.builder.config(conf=conf).getOrCreate()
# 获取作业上下文
sc = spark.sparkContext
准备数据¶
Python
# 读取 HDFS 文件
movies = sc.textFile("hdfs://node1:8020/text/ml_1m/movies.dat")
ratings = sc.textFile("hdfs://node1:8020/text/ml_1m/ratings.dat")
users = sc.textFile("hdfs://node1:8020/text/ml_1m/users.dat")
Python
# 过滤异常数据
movies = movies.filter(
lambda movie: (len(movie.strip()) > 0) and (len(movie.split("::")) == 3)
)
movies.cache()
ratings = ratings.filter(
lambda rating: (len(rating.strip()) > 0) and (len(rating.split("::")) == 4)
)
ratings.cache()
users = users.filter(
lambda user: (len(user.strip()) > 0) and (len(user.split("::")) == 5)
)
users.cache()
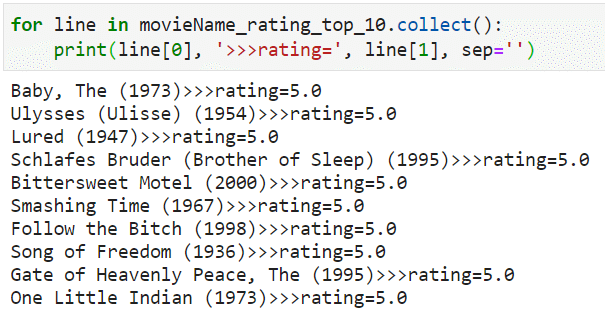
输出所有电影中评分最高的前 10 个电影名称和平均评分¶
Python
# 定义函数,输入【电影 ID 和评分】、【电影 ID 和电影名称】和【评分前 n 位】,输出【评分最高的电影名称和平均评分】
def top(ratings_data, movies_data, n):
# 从 ratings_data 中提取出【电影 ID】和【评分】,并在 value 中补充“1”作为【评分数量】
movieID_rating = ratings_data.map(
lambda x: (int(x.split("::")[1]), (int(x.split("::")[2]), 1))
)
# 对同一部电影,加总【评分】和【评分数量】,得到【评分和】和【评分数量和】
movieID_rating_reduced = movieID_rating.reduceByKey(
lambda x, y: (x[0] + y[0], x[1] + y[1])
)
# 对同一部电影,用【评分和】除以【评分数量和】,得到【平均评分】
movieID_rating_average = movieID_rating_reduced.mapValues(lambda x: x[0] / x[1])
# 根据每一部电影的【平均评分】从大到小排序
movieID_rating_descending = movieID_rating_average.sortBy(lambda x: x[1], False)
# 提取【平均评分】最高的 n 部电影的【电影 ID】和【平均评分】,并存入一个 RDD
movieID_rating_top_n = sc.parallelize(movieID_rating_descending.take(n))
# 从 movies_data 中提取出【电影 ID】和【电影名称】
movieID_movieName = movies_data.map(
lambda x: (int(x.split("::")[0]), x.split("::")[1])
)
# 将【电影名称】合并到【平均评分】最高的 n 部电影,并提取【电影名称】和【平均评分】
movieName_rating_top_n = movieID_rating_top_n.join(movieID_movieName).map(
lambda x: (x[1][1], x[1][0])
)
return movieName_rating_top_n
输出所有电影中最受男性喜爱的电影 Top 10 及其平均评分¶
Python
# 从 users 中提取出【用户 ID】和【用户性别】
userID_gender = users.map(lambda x: (int(x.split("::")[0]), x.split("::")[1]))
Python
# 将 ratings 和 userID_gender 合并后,过滤得到男性的评分数据
male_ratings = (
ratings.map(
lambda x: (
int(x.split("::")[0]),
(int(x.split("::")[1]), int(x.split("::")[2])),
)
)
.join(userID_gender)
.filter(lambda x: x[1][1] == "M")
.map(lambda x: "{}::{}::{}".format(x[0], x[1][0][0], x[1][0][1]))
)

输出所有电影中最受中年人(45<=age<=55)喜爱的电影 Top 5 及其平均评分¶
Python
# 从 users 中提取出【用户 ID】和【年龄】
userID_age = users.map(lambda x: (int(x.split("::")[0]), int(x.split("::")[2])))
Python
# 将 ratings 和 userID_age 合并后,过滤得到中年人的评分数据
middleAge_ratings = (
ratings.map(
lambda x: (
int(x.split("::")[0]),
(int(x.split("::")[1]), int(x.split("::")[2])),
)
)
.join(userID_age)
.filter(lambda x: x[1][1] == 45 or x[1][1] == 50)
.map(lambda x: "{}::{}::{}".format(x[0], x[1][0][0], x[1][0][1]))
)

输出最受学生(含中小学生及大学生)欢迎的(即观看人数最多)动画 (Animation) 电影 Top 5 的名称¶
Python
# 定义函数,输入【电影 ID 和评分】、【电影 ID 和电影名称】和【观看人数前 n 位】,输出【观看人数最多的电影名称和观看次数】
def popular(ratings_data, movies_data, Genre, n):
# 从 movies_data 中提取出【电影 ID】和【电影类型】
movieID_movieGenre = movies_data.map(
lambda x: (int(x.split("::")[0]), x.split("::")[2])
)
# 从 ratings_data 中提取出【电影 ID】,并在 value 中补充“1”作为【评分数量】,并与 movieID_movieGenre 合并,筛选得到【动画电影】的数据
movieID_rating_number = (
ratings_data.map(lambda x: (int(x.split("::")[1]), 1))
.join(movieID_movieGenre)
.filter(lambda line: Genre in line[1][1].split("|"))
.map(lambda line: (line[0], line[1][0]))
)
# 对同一部电影,加总【评分数量】得到【评分数量和】
movieID_rating_number_sum = movieID_rating_number.reduceByKey(lambda x, y: x + y)
# 根据每一部电影的【评分数量和】从大到小排序
movieID_rating_number_sum_descending = movieID_rating_number_sum.sortBy(
lambda x: x[1], False
)
# 提取【评分数量和】最高的 n 部电影的【电影 ID】和【评分数量和】,并存入一个 RDD
movieID_rating_number_sum_top_n = sc.parallelize(
movieID_rating_number_sum_descending.take(n)
)
# 从 movies_data 中提取出【电影 ID】和【电影名称】
movieID_movieName = movies_data.map(
lambda x: (int(x.split("::")[0]), x.split("::")[1])
)
# 将【电影名称】合并到【评分数量和】最多的 n 部电影,并提取【电影名称】和【评分数量和】
movieName_rating_number_sum_top_n = movieID_rating_number_sum_top_n.join(
movieID_movieName
).map(lambda x: (x[1][1], x[1][0]))
return movieName_rating_number_sum_top_n.sortBy(lambda x: x[1], False)
Python
# 从 users 中提取出【用户 ID】和【职业】
userID_occupation = users.map(lambda x: (int(x.split("::")[0]), int(x.split("::")[3])))
Python
# 将 ratings 和 userID_occupation 合并后,过滤得到【学生】的评分数据
student_ratings = (
ratings.map(
lambda x: (
int(x.split("::")[0]),
(int(x.split("::")[1]), int(x.split("::")[2])),
)
)
.join(userID_occupation)
.filter(lambda x: x[1][1] == 4 or x[1][1] == 10)
.map(lambda x: "{}::{}::{}".format(x[0], x[1][0][0], x[1][0][1]))
)
