Pandas 根据日期进行分组¶
问题背景:有一个分钟级别索引的数据框,需要根据日期进行分组聚合计算。
- 简单的
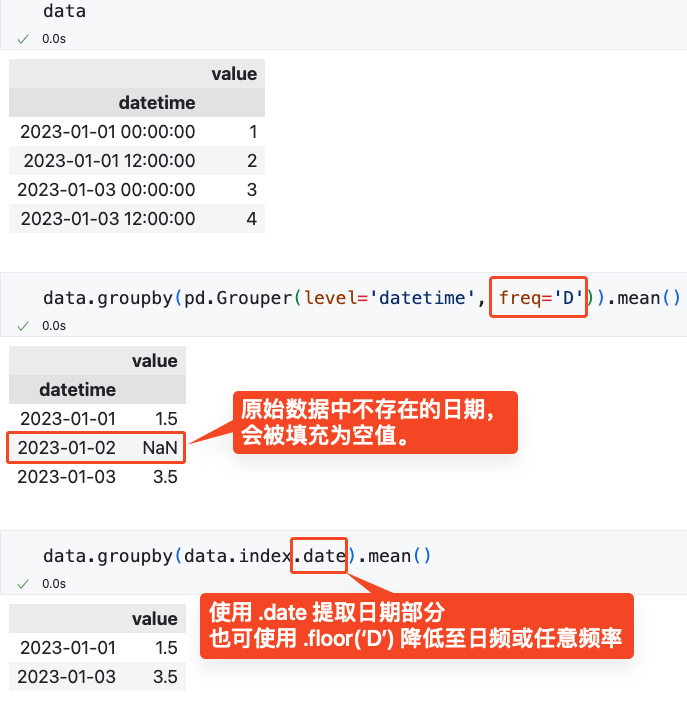
.groupby('datetime')无法实现按日期分组。 .groupby(pd.Grouper(level='datetime', freq='D'))会为原始数据中不存在的日期填充空值(例如,在股票数据中,周末、节假日等非交易日会被填充为空值)。- 如果分组后调用的是
.mean(),则会出现这个问题。 - 如果分组后调用的是
.transform('mean'),则不存在这个问题。
- 如果分组后调用的是
本文记录了可以正确根据日期进行分组的方法。
示例数据¶
Python
import pandas as pd
import numpy as np
# 创建一个示例数据集
data = pd.DataFrame(
index=np.concatenate(
(
pd.date_range(
start="2023-01-01 00:00:00", end="2023-01-01 23:59:59", freq="12H"
),
pd.date_range(
start="2023-01-03 00:00:00", end="2023-01-03 23:59:59", freq="12H"
),
),
axis=None,
),
data={
"value": [1, 2, 3, 4],
},
)
data.index.name = "datetime"
print(data)
Text Only
value
datetime
2023-01-01 00:00:00 1
2023-01-01 12:00:00 2
2023-01-03 00:00:00 3
2023-01-03 12:00:00 4
简单的 .groupby('datetime') 无法实现按日期分组¶
.groupby('datetime') 只是根据原始分钟级别进行分组,并没有实现按日期分组的效果。
Text Only
value
datetime
2023-01-01 00:00:00 1.0
2023-01-01 12:00:00 2.0
2023-01-03 00:00:00 3.0
2023-01-03 12:00:00 4.0
.groupby(pd.Grouper(level='datetime', freq='D')) 会为原始数据中不存在的日期填充空值¶
2023-01-02 本来是没有数据的,但分组之后被填充为了空值。
.transform() 不会出现填充空值的问题
如果分组后调用的是 .transform('mean'),则不存在这个问题。
使用 .date 或 .floor('D') 提取日期¶
.date¶
.floor('D')¶
参考:StackOverflow: In pandas, group by date from DatetimeIndex。
D 代表日频。更多数据频率的字符串可以参考 offset-aliases。
.date 和 .floor('D') 的区别
注意到,上述两种方法得到的结果略微有不同:
.date得到的结果中,索引是没有名称的。.floor('D')得到的结果中,索引的名称仍然是datetime。
.date 和 .floor('D') 的运行速度¶
StackOverflow: In pandas, group by date from DatetimeIndex 回答的评论说 .floor('D') 更快,但我自己实验后发现有时 .date 更快,有时两者耗时十分接近。