Python 实现多列滚动计算——以“更优波动率”为例¶
对单列数据进行滚动计算,可以使用常规的.rolling()。
如果需要对多列数据进行滚动计算,可以考虑下面两种方法:
- 引入外部包
numpy_ext,使用其中的rollling_apply()方法。 - 在
.rolling()中加入参数method='table'。
本文以方正金工发表的一篇研报中提出的计算“更优波动率”为例,实现了对多列数据进行滚动计算,并对上述两种方法总结如下:
numpy_ext.rollling_apply()需要引入外部包numpy_ext,该方法接受需要进行滚动计算的多个 Series,并返回计算出的一个数组。.rolling(method='table')是 Pandas 内置的函数(需要升级到较新的版本),指定method='table'后,就可以对数据框中的多列进行滚动计算,并返回一个数据框。若返回的多列结果相同,我们只需要取出其中一列即可。.rolling(method='table')使用了engine='numba',计算速度更快。
更优波动率的定义¶
“更优波动率”的改进之处在于,将原始由分钟收盘价来计算标准差,改为同时使用分钟开盘价、分钟最高价、分钟最低价和分钟收盘价来记录这一分钟的价格信息。
具体计算方法为:
第 t 分钟的“更优波动率”为,第 t-4、t-3、t-2、t-1、t 分钟的分钟开盘价、分钟最高价、分钟最低价和分钟收盘价,共 20 个价格数据求标准差,然后除以这 20 个价格数据的均值,最后将该比值取平方,作为 t 分钟的“更优波动率”。
导入包¶
Python
import pandas as pd
import numpy as np
import akshare as ak
from numpy_ext import rolling_apply
使用akshare获取数据¶
Python
# 获取分钟数据
df = ak.stock_zh_a_minute(symbol="sh000001", period="1")
# 将除'day'外的各列的字符串转换为数值
df = df.apply(pd.to_numeric, errors="ignore")
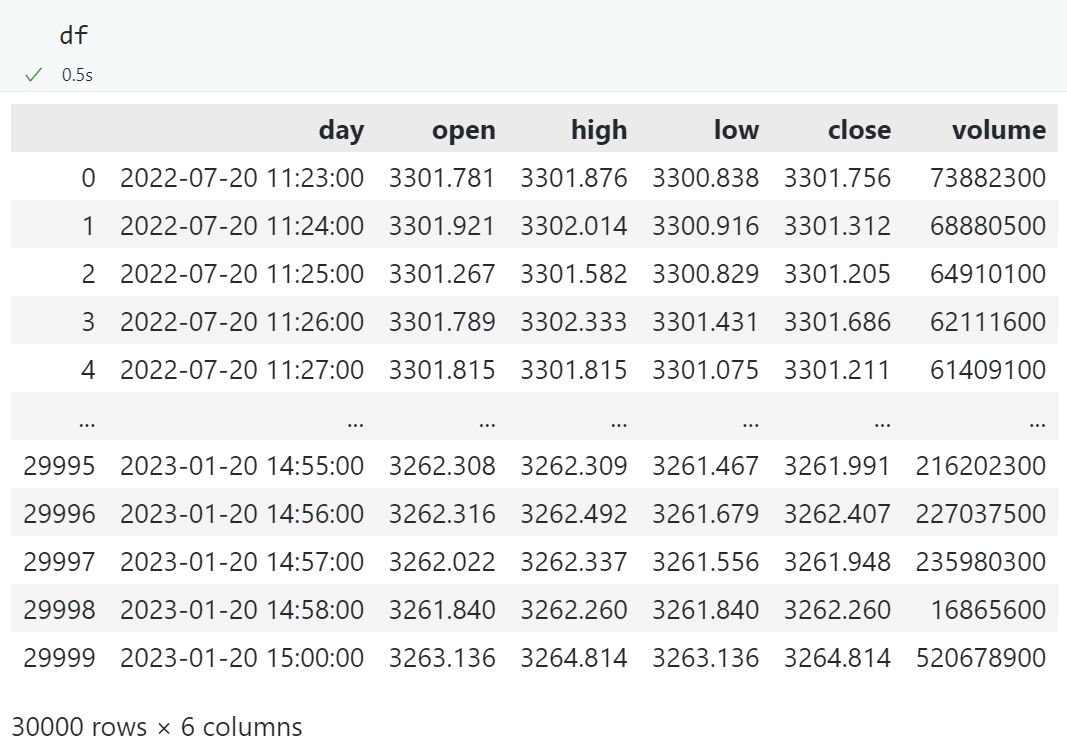
共获取 30000 条分钟频数据:
使用numpy_ext计算更优波动率¶
定义计算更优波动率的函数¶
Python
# 计算更优波动率
def better_volatility_numpy_ext(o, h, l, c):
# 将 4 列数据合并成一个数组
data = np.array([o, h, l, c])
# 计算 20 个数据的标准差
std = np.std(data)
# 计算 20 个数据的均值
mean = np.mean(data)
# 计算更优波动率
return (std / mean) ** 2
这个函数接受 4 个 Series 作为参数,我们需要在函数内部将这 4 个 Series 拼接成一个数组,再按照更优波动率的计算逻辑,求出 20 个数据的标准差和均值,最后将两者相除再平方即可得到更优波动率。
应用numpy_ext.rollling_apply()¶
Python
better_volatility_using_numpy_ext = rolling_apply(
better_volatility_numpy_ext, 5, df["open"], df["high"], df["low"], df["close"]
)
这里的window = 5,即滚动 5 分钟进行计算。
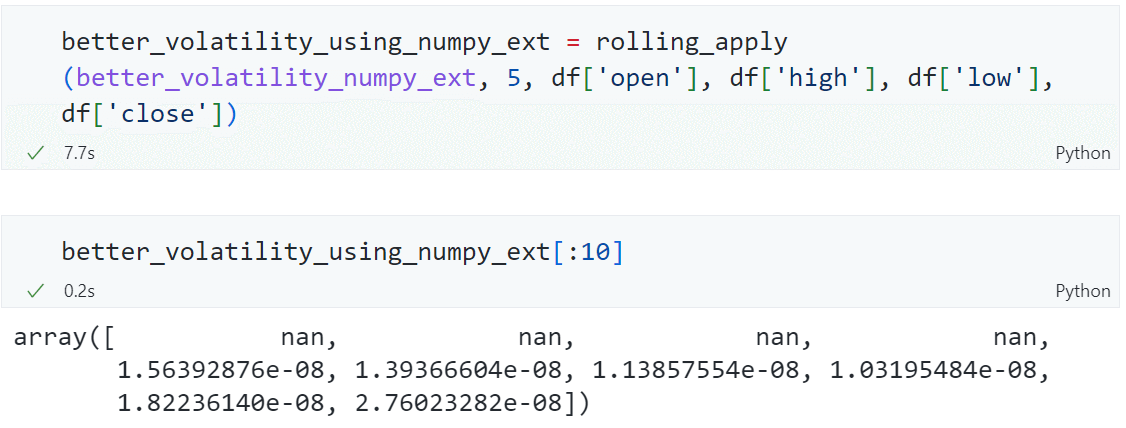
耗时 7 秒,计算得到前 5 分钟的更优波动率为 1.56392876e-08。
使用pandas内置的.rolling(method='table')计算更优波动率¶
定义计算更优波动率的函数¶
Python
# 计算更优波动率
def better_volatility_pandas(data):
# 计算 20 个数据的标准差
std = np.std(data)
# 计算 20 个数据的均值
mean = np.mean(data)
# 计算更优波动率
return (std / mean) ** 2
与numpy_ext.rollling_apply()中使用的函数不同的是,这里接受的是一个数据框作为输入数据。
应用.rolling(method='table')¶
Python
better_volatility_using_pandas = (
df[["open", "high", "low", "close"]]
.rolling(5, method="table")
.apply(better_volatility_pandas, raw=True, engine="numba")
)
这里的window = 5,即滚动 5 分钟进行计算。


耗时 3 秒,计算得到前 5 分钟的更优波动率也为 1.563929e-08。
这一条命令的输出是几列相同的数据(计算和输出的时候和data的形状是匹配的),而我们需要的只有一列,所以需要单独取出一列数据。

手动验算结果¶
Python
# 手动验算,与上面的结果一致
std = df.iloc[:5][["open", "high", "low", "close"]].values.std()
mean = df.iloc[:5][["open", "high", "low", "close"]].values.mean()
better_volatility_using_numpy = (std / mean) ** 2
print(better_volatility_using_numpy)

可以发现,两种计算方法的结果都是准确的。
总结¶
numpy_ext.rollling_apply()需要引入外部包numpy_ext,该方法接受需要进行滚动计算的多个 Series,并返回计算出的一个数组。.rolling(method='table')是 Pandas 内置的函数(需要升级到较新的版本),指定method='table'后,就可以对数据框中的多列进行滚动计算,并返回一个数据框。若返回的多列结果相同,我们只需要取出其中一列即可。.rolling(method='table')使用了engine='numba',计算速度更快。