手动计算简单的反向传播算法¶
反向传播算法是深度学习进行参数优化的基础。本文手动计算了多层感知机中损失函数对权重、净输入值的梯度,并与 PyTorch 的计算结果进行了验证。
反向传播算法的本质是矩阵微分和链式法则,这两个知识都不难理解,但刚接触反向传播算法时总容易被一些陌生的符号弄糊涂。理解反向传播算法的理论推导,最重要的是弄清楚各个向量、矩阵的维度,以及熟练它们之间的前向传播关系。最后多加练习,就能对反向传播算法的理解更加透彻。
理论推导¶
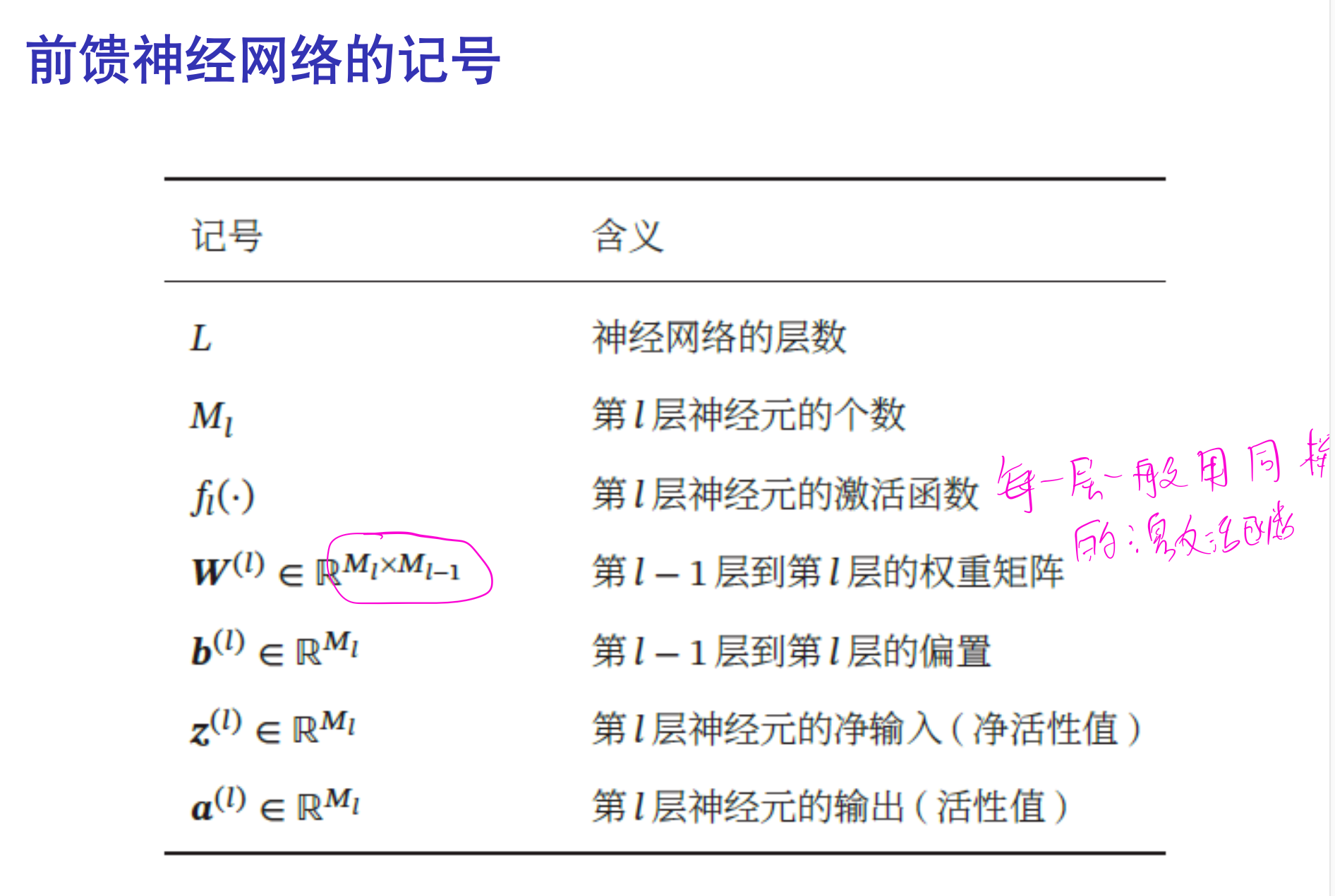



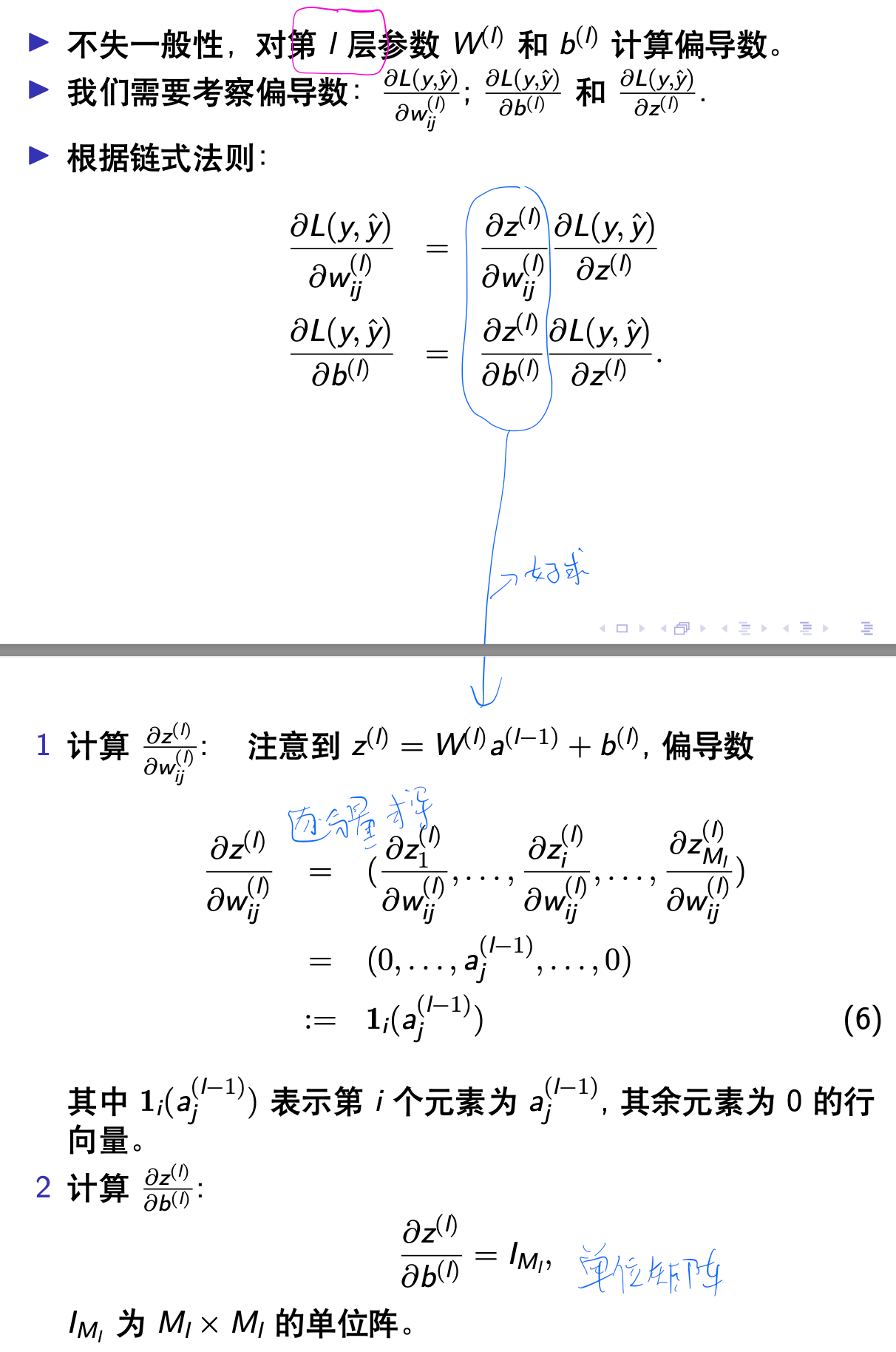


MSE 损失,无激活函数¶
不包含偏置项
为方便计算,以下均假设偏置项为 \(0\)。
手动计算¶
假设真实的 \(y\) 值为 \(4\)。
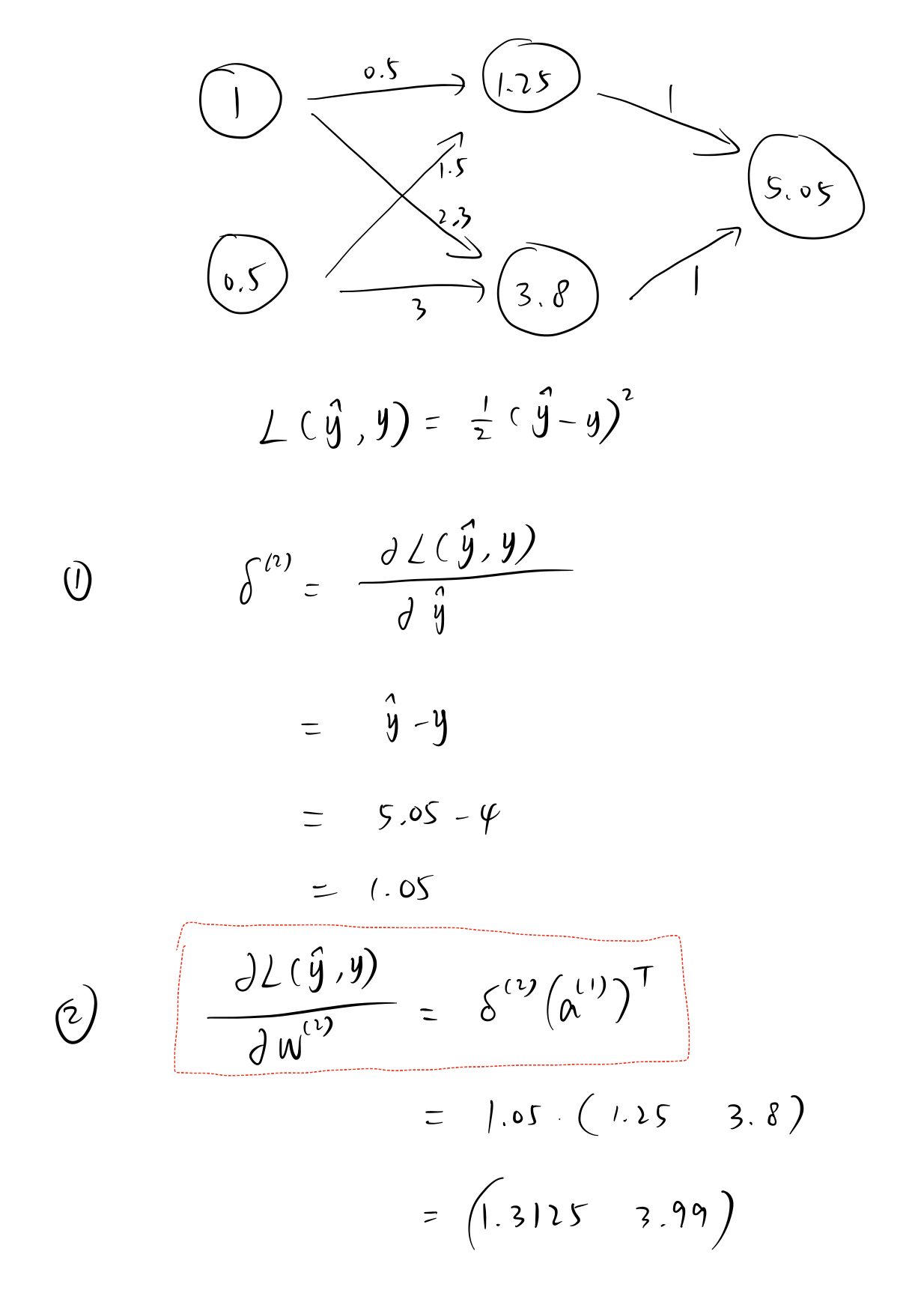
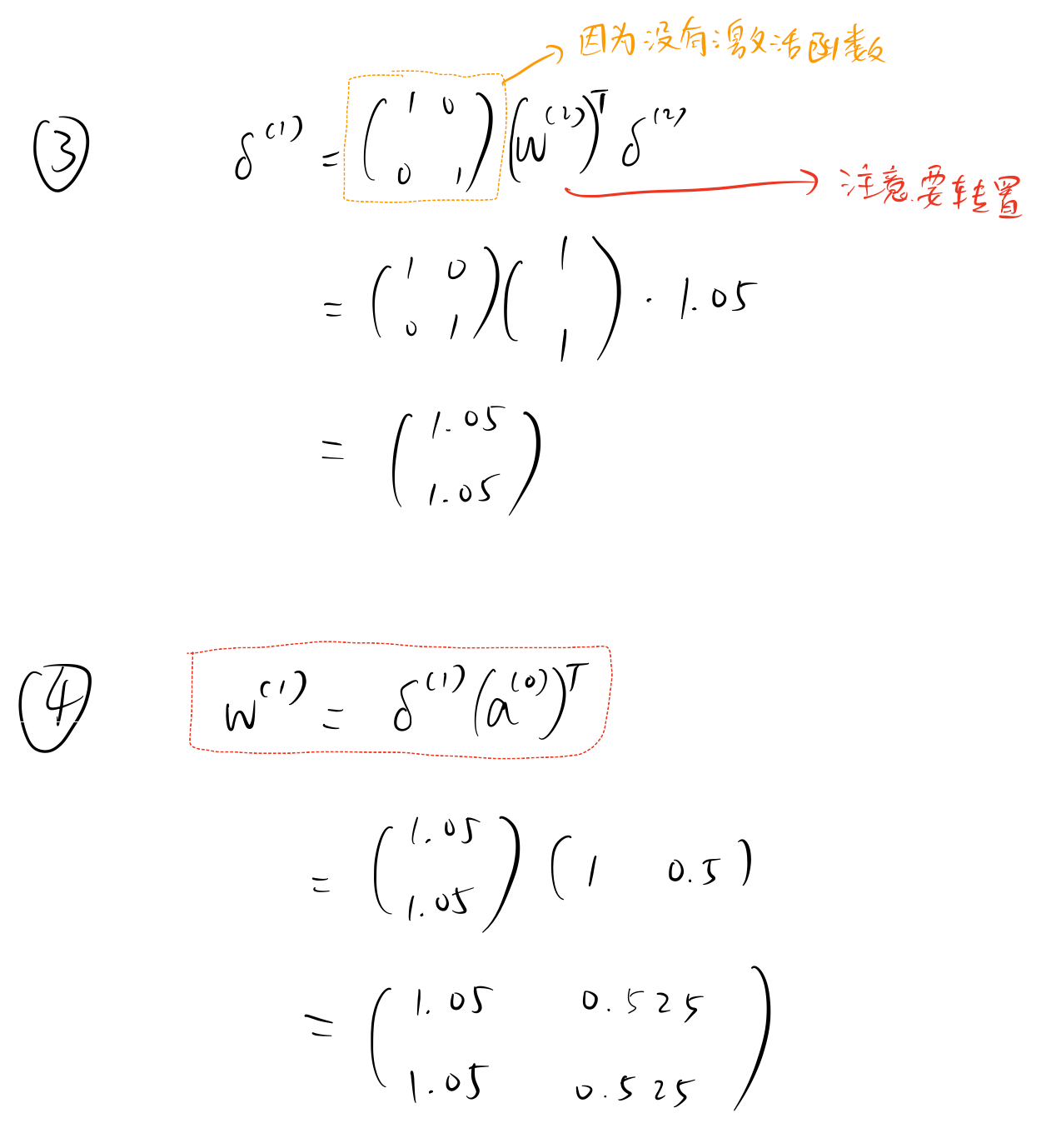
PyTorch 计算¶

MSE 损失,隐藏层使用 Logistic 激活函数¶
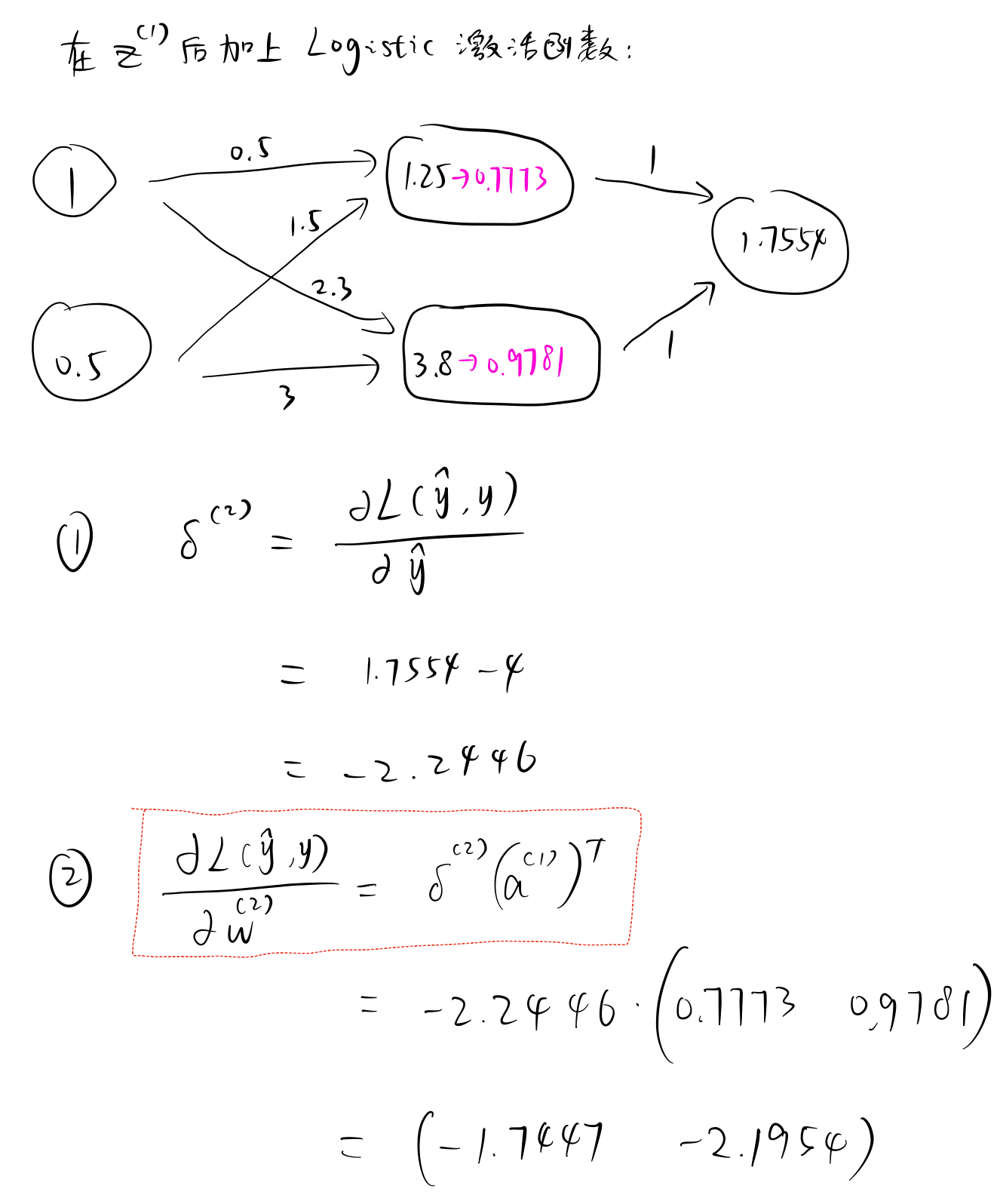
手动计算¶
假设真实的 \(y\) 值为 \(4\)。

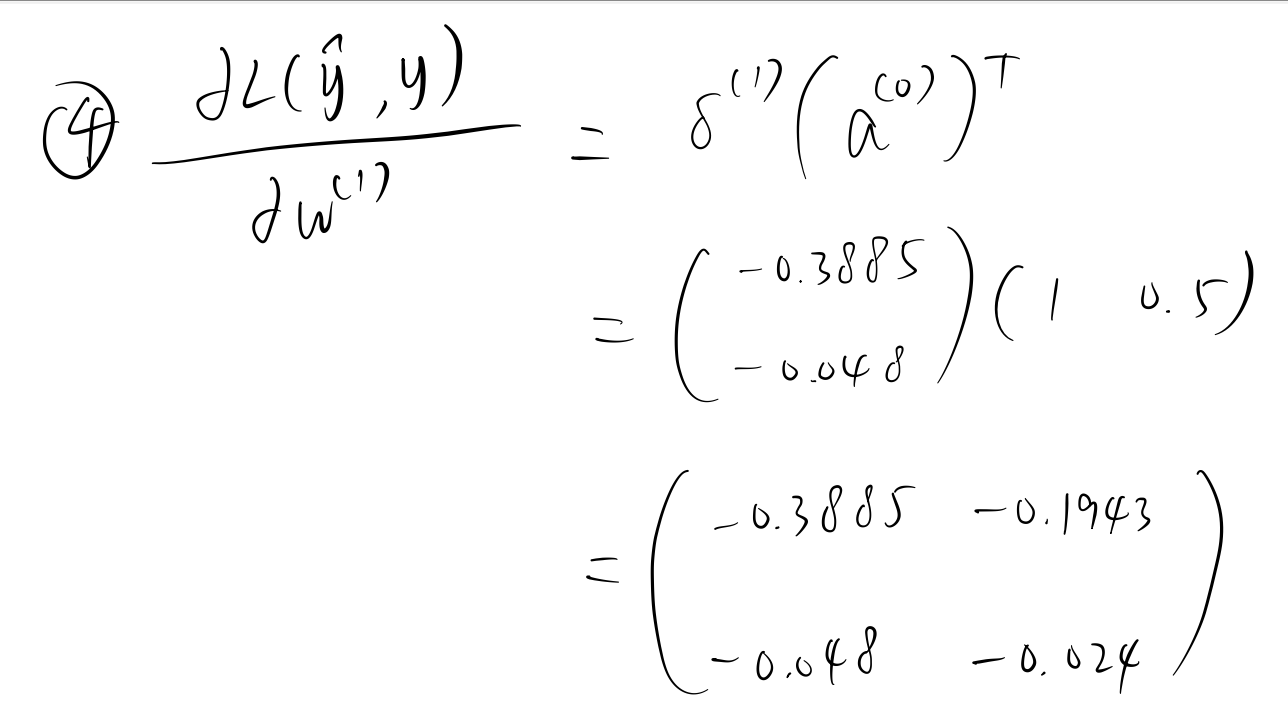
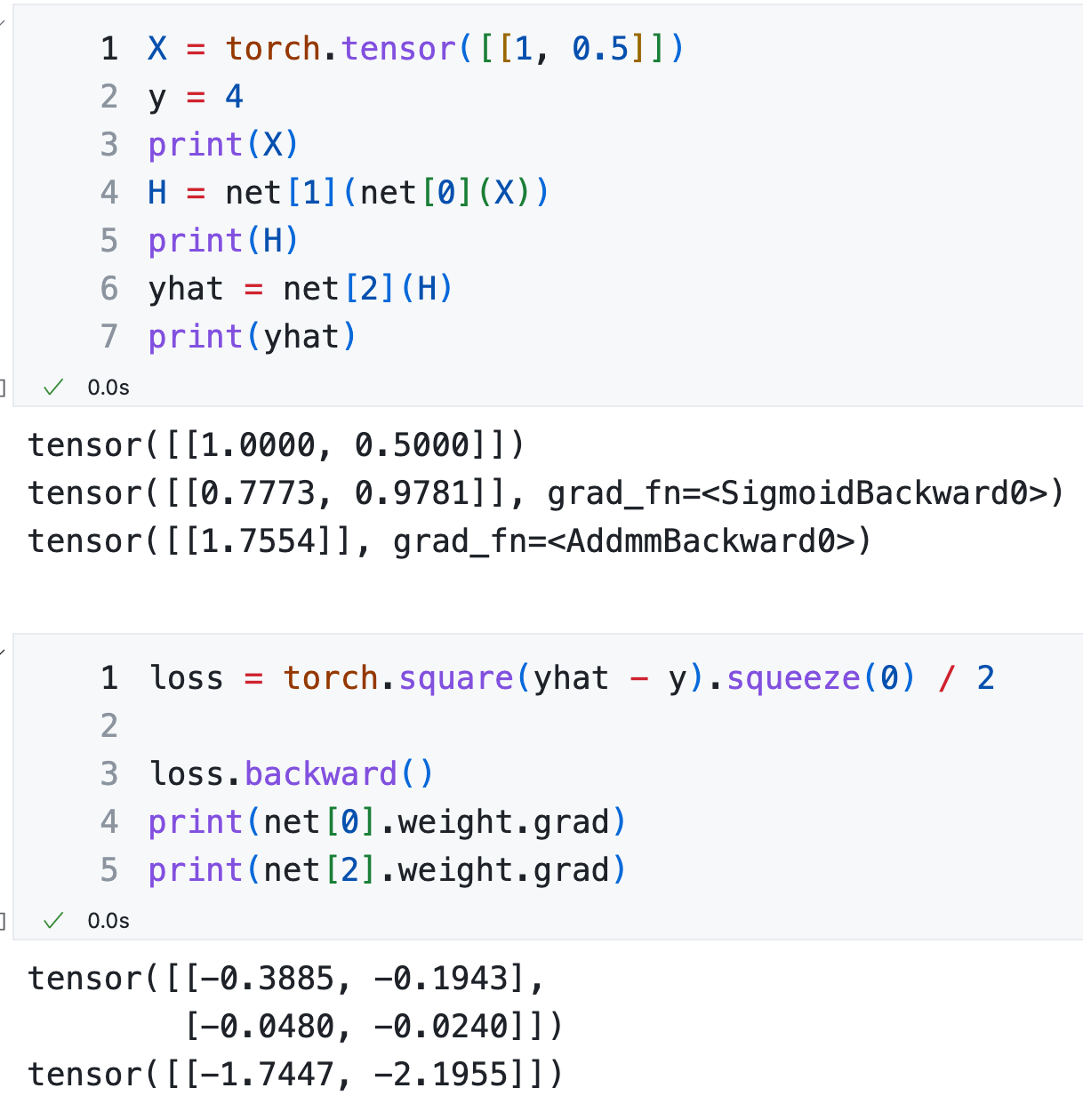
PyTorch 计算¶
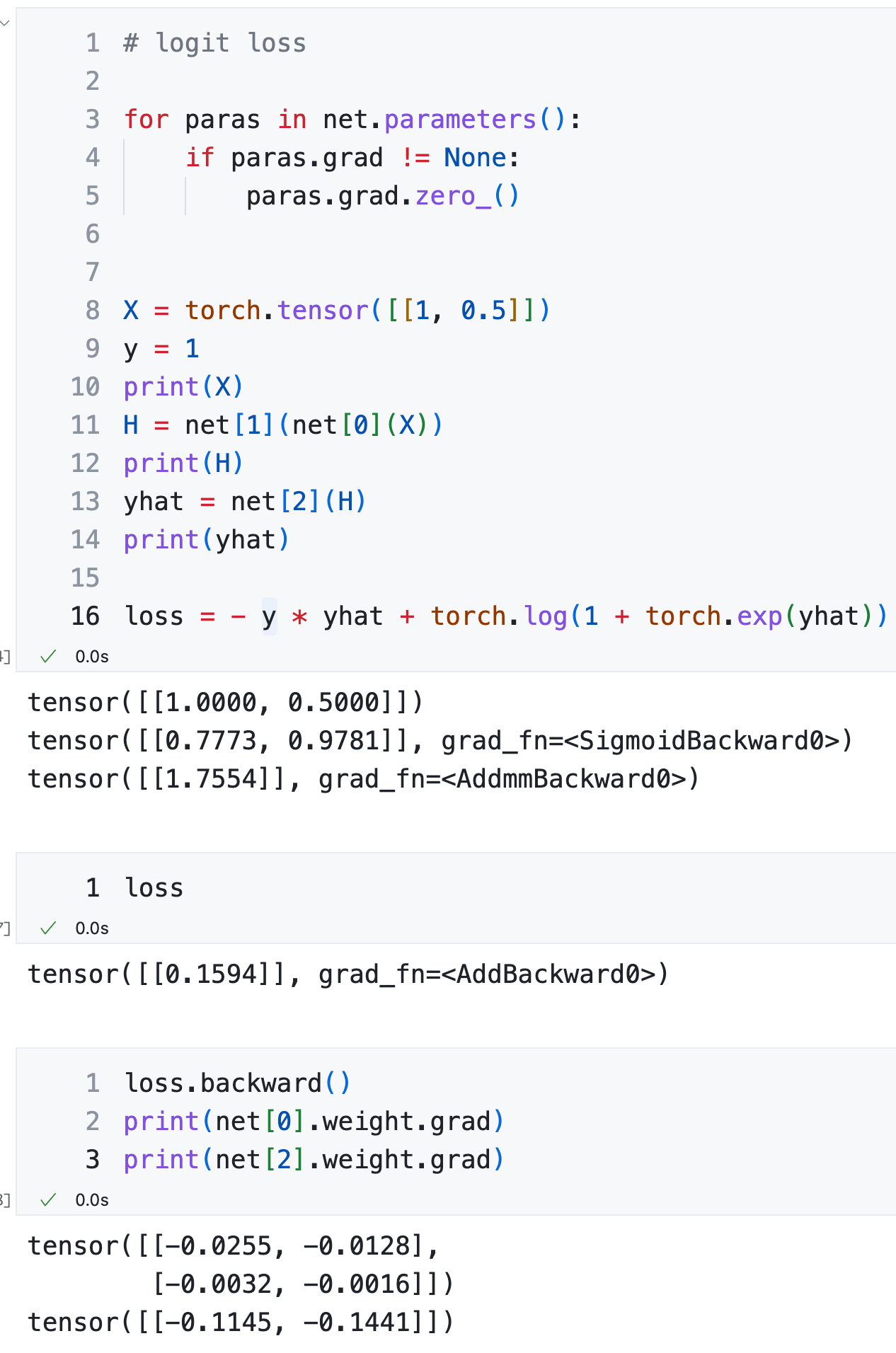
Logit 损失,隐藏层使用 Logistic 激活函数¶
手动计算¶
假设真实的 \(y\) 值为 \(1\)。
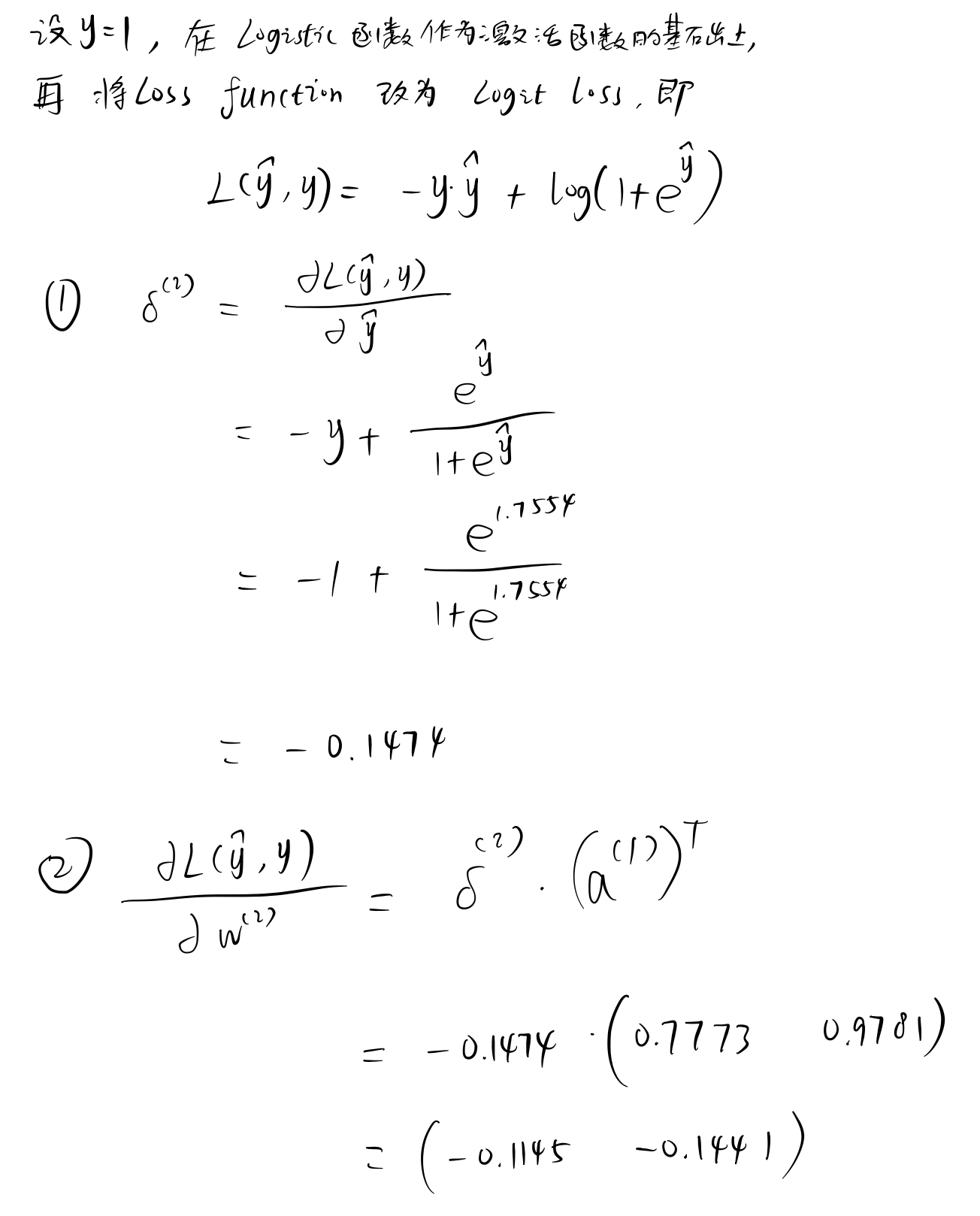

PyTorch 计算¶