大数据技术之 HBase 和 Hive¶
HBase 和 Hive 是海量数据下的数据库技术。
HBase¶
初识 HBase¶
个人理解:
HBase 是 Hadoop database 的简称,也就是基于 Hadoop 数据库,是一种非关系型、列式存储的数据库。适合存储稀疏数据。当修改数据时,不删除原数据,只是新添加一个时间戳记录新的值(最多保留最近的 5 个版本),因此对只读的优化做得很好。
课件上的定义:
HBase 是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌 BigTable 的开源实现,主要用来存储非结构化和半结构化的松散数据。HBase 的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过 10 亿行数据和数百万列元素组成的数据表。
习题课上的更多理解:
HBase 其实也可部署在单机上,但 HBase 的优势是方便处理海量的数据,而单机一般无法存储海量的数据,所以一般将 HBase 与 Zookeeper(分布式协调服务系统)和 Kafka(分布式消息系统)结合,部署在 HDFS(分布式文件储存系统)上,这样就可以用许多廉价的服务器处理海量的数据。
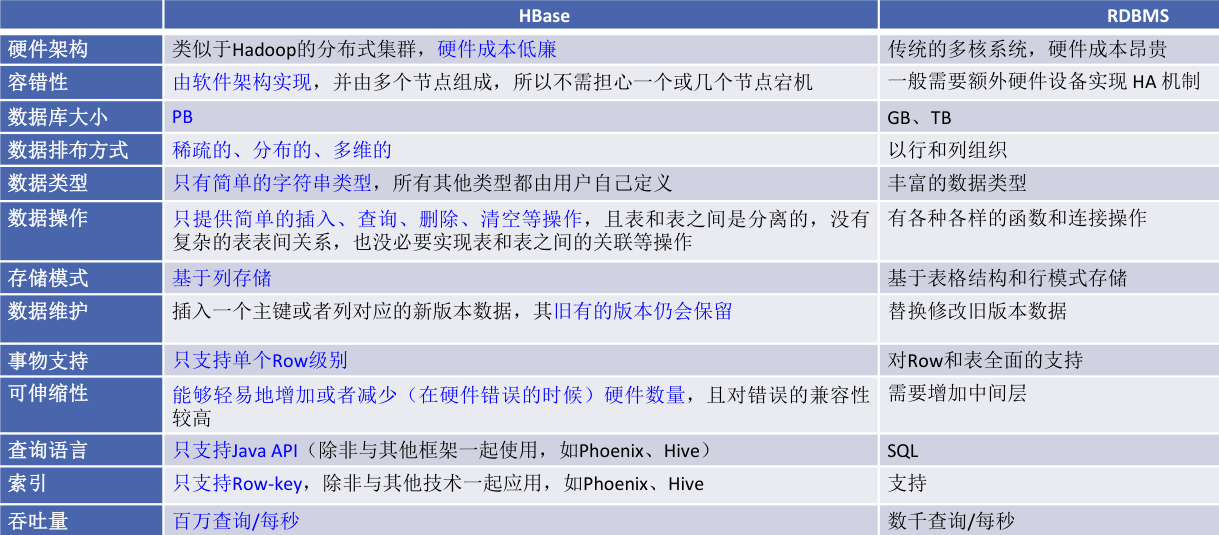
HBase 与传统的关系数据库(Rational Database Management System)的区别¶
- 数据类型:关系数据库采用关系模型,具有丰富的数据类型和存储方式,HBase 则采用了更加简单的数据模型,它把数据存储为未经解释的字符串。
- 数据操作:关系数据库中包含了丰富的操作,其中会涉及复杂的多表连接。HBase 操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等,因为 HBase 在设计上就避免了复杂的表和表之间的关系。
- 存储模式:关系数据库是基于行模式存储的。HBase 是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的。
- 数据索引:关系数据库通常可以针对不同列构建复杂的多个索引,以提高数据访问性能。HBase 只有一个索引——行键,通过巧妙的设计,HBase 中的所有访问方法,或者通过行键访问,或者通过行键扫描,从而使得整个系统不会慢下来。
- 数据维护:在关系数据库中,更新操作会用最新的当前值去替换记录中原来的旧值,旧值被覆盖后就不会存在。而在 HBase 中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留。
- 可伸缩性:关系数据库很难实现横向扩展,纵向扩展的空间也比较有限。相反,HBase 和 BigTable 这些分布式数据库就是为了实现灵活的水平扩展而开发的,能够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩。
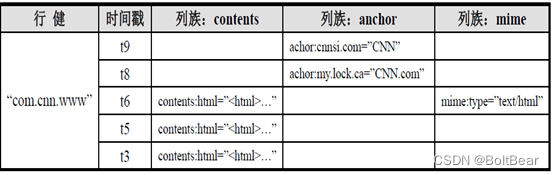
HBase 的数据模型¶
按照:
- 行键
- 列族
- 列限定符(可以理解为列族下的列名)
- 时间戳
来存储一个数据值。
一个 Cell 里的数据值没有类型,只是byte array,即字节数组。需要用的时候,应该将这些字节数组解释成适当的类型,如中文、数字等等。
列式存储结构¶
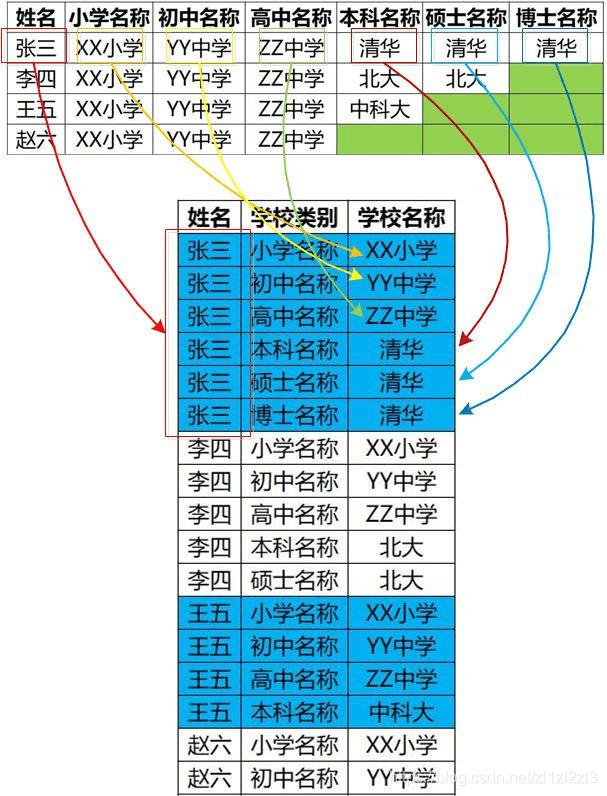
按照列式存储的方法,表格中的空值就不需要被存储,可以大大节约空间。因此 HBase 十分适合存储稀疏数据(稀疏数据有很多空值)。
HBase 常用操作¶
在命令行输入
进入和退出 HBase。
数据定义相关(DDL)¶
- create: 创建一个表。
- create '表名', '列族名 1', '列族名 2'
- list: 列出 HBase 的所有表。
- disable: 禁用表。
- disable '表名'
- is_disabled: 验证表是否被禁用。
- enable: 启用一个表。
- is_enabled: 验证表是否已启用。
- describe: 提供了一个表的描述。
- describe '表名'
- alter: 改变一个表。
- exists: 验证表是否存在。
- exist '表名'
- drop: 从 HBase 中删除表。
- Disable it first
- drop '表名'
- drop_all: 丢弃在命令中给出匹配“regex”的表。
数据操纵相关(DML)¶
- put: 把指定列在指定的行中单元格的值在一个特定的表。
- get: 取行或单元格的内容。
- delete: 删除表中的单元格值。
- deleteall: 删除给定行的所有单元格。
- scan: 扫描并返回表数据。
- scan '表名'
- 扫描时筛选前缀:scan "p_table",{LIMIT=>5,FILTER=>"PrefixFilter('www.t')"}
- 扫描时筛选包含字符串:scan "p_table",{LIMIT=>5,FILTER=>"ValueFilter(=,'substring:
- 扫描时筛选列名:scan 'p_table', {COLUMNS=>['df:body']}
- count: 计数并返回表中的行的数目。
- truncate: 禁用,删除和重新创建一个指定的表。
Python 通过happybase包访问 HBase¶
配置
conn = happybase.Connection(
host="node1", port=9090, protocol="compact", transport="framed"
)
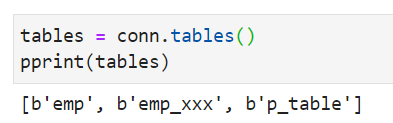
查询有哪些表格
scan扫描全表
table = conn.table(b"emp_xxx")
# 扫描全表,至多 2 组数据
for key, value in table.scan(limit=2):
print(f"key: {key}")
pprint(value, indent=2)

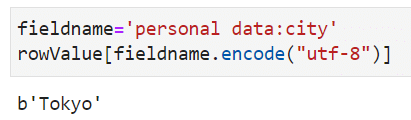
查询某行数据。因为 HBase 内的数据没有类型,所有数据都是字节数组,所以要用b'1'将'1'转为字节形式,这样 HBase 才能执行。

或者用.encode("utf-8"):
Hive¶
初识 Hive¶
个人理解:Hive 允许我们写 SQL 命令来实现大数据的查询,这样就不用编写复杂的 MapReduce 代码了。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类 SQL 查询功能。其本质是将 SQL 转换为 MapReduce/Spark 的任务进行运算,底层由 HDFS 来提供数据的存储。
Hive 可以理解为一个将 SQL 转换为 MapReduce/Spark 的任务的工具,甚至更进一步可以说 Hive 就是一个 MapReduce/Spark SQL 的客户端。
为什么要使用 Hive ?¶
- 学习 MapReduce 的成本比较高,项目周期要求太短,MapReduce 如果要实现复杂的查询逻辑开发的难度是比较大的。
- 如果使用 Hive,Hive 采用操作接口类似 SQL 语法,提高快速开发的能力。避免去书写 MapReduce,减少学习成本,而且提供了功能的扩展
hive 的特点: - 可扩展 : Hive 可以自由的扩展集群的规模,一般情况下不需要重启服务。 - 延展性 : Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。 - 容错 : 良好的容错性,节点出现问题 SQL 仍可完成执行。
内部表及外部表¶
数据 (data) 都存储在 HDFS 上,内部表由 Hive 自身管理,外部表数据由 HDFS 管理。这门课只需要掌握内部表。
- 内部表 (managed table):
- 未被 external 修饰的表,也叫管理表。
- 元数据 (metadata) 存储在 MySQL 上,由 MySQL 管理。
- 数据 (data) 存储在 HDFS 上,内部表由 Hive 自身管理
- 删除表会删除表的元数据 (metadata) 和表数据(data)。
- 内部表数据存储的位置是 hive.metastore.warehouse.dir(默认:/user/hive/warehouse)
- 外部表 (external table):
- 被 external 修饰的表。
- 元数据 (metadata) 都存储在 MySQL 上,由 MySQL 管理。
- 数据 (data) 存储在 HDFS 上,外部表数据由 HDFS 管理;
- 删除表会删除表的元数据 (metadata),但不会删除表数据(data)。
- 外部表数据的存储位置由自己制定(如果没有 LOCATION,Hive 将在 HDFS 上的/user/hive/warehouse 文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里);
创建表¶
## 内部表
CREATE TABLE emp(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ",";
desc emp;
## 外部表
CREATE EXTERNAL TABLE emp_external(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ","
LOCATION '/hive/external/emp_external';
#### -- 按照部门编号进行分区, 分区中定义的变量名不能和表中的列相同
CREATE EXTERNAL TABLE emp_partition(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
PARTITIONED BY (deptno INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ","
LOCATION '/hive/partition/emp_partition';
## 装载数据
一般很少用insert 语句,因为就算就算插入一条数据,也会调用MapReduce,一般选择Load Data的方式。
## 内部表
load data local inpath "emp.txt" into table emp;
load data local inpath "emp1.txt" into table emp;
## 外部表 :多次加载增加文件
load data local inpath "emp.txt" into table emp_external;
load data local inpath "emp1.txt" into table emp_external;
## 分区表 :多次加载 覆盖OVERWRITE
LOAD DATA LOCAL INPATH "emp.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=10);
LOAD DATA LOCAL INPATH "emp.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=20);
LOAD DATA LOCAL INPATH "emp1.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=20);
LOAD DATA LOCAL INPATH "emp.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=30);
Python 访问 Hive¶
通过impala包¶
from impala.dbapi import connect
impala_param = {"host": "node1", "port": 21050, "database": "machine_learning"}
conn = connect(**impala_param)
cur = conn.cursor()
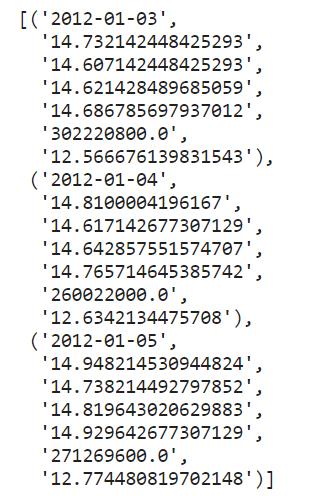
cur.execute("SELECT * FROM aapl_stock_parquet ORDER BY p_date")
data_list = cur.fetchall()
data_list[:3]
通过pyhive包¶
from pyhive import hive
conn = hive.Connection(
host="node1", port="10000", username="user_01", database="userdb_99"
)
cursor = conn.cursor()
cursor.execute("select * from emp limit 2")
for result in cursor.fetchall():
print(result)

conn = hive.Connection(
host="node1", port="10000", username="user_47", database="userdb_47"
)
cursor = conn.cursor()
cursor.execute("select * from emp")
for result in cursor.fetchall():
print(result)
