牛顿法和拟牛顿 BFGS 法实现 Logistic 回归¶
推导二元 Logistic 回归的 Hessian 矩阵,利用牛顿法和拟牛顿 BFGS 法求回归系数的极大似然估计。所得模型在训练样本的预测准确度为 78%。
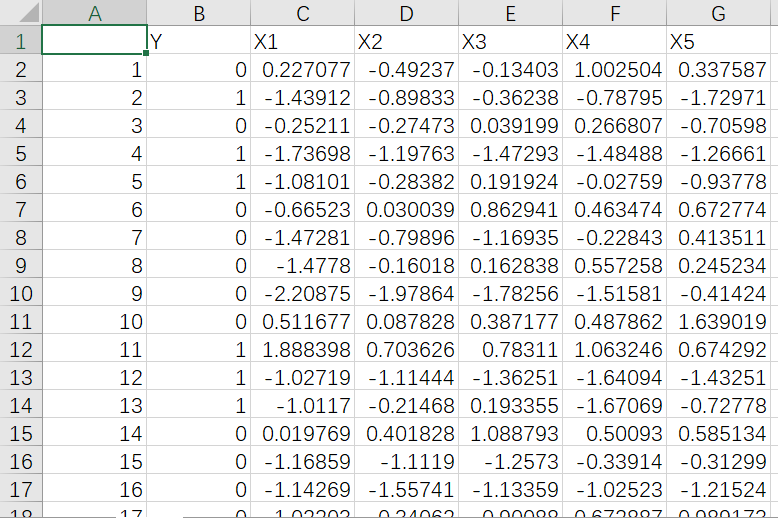
问题描述:¶

数据文件:¶
推导似然函数的 Hessian 矩阵¶
似然函数的梯度¶
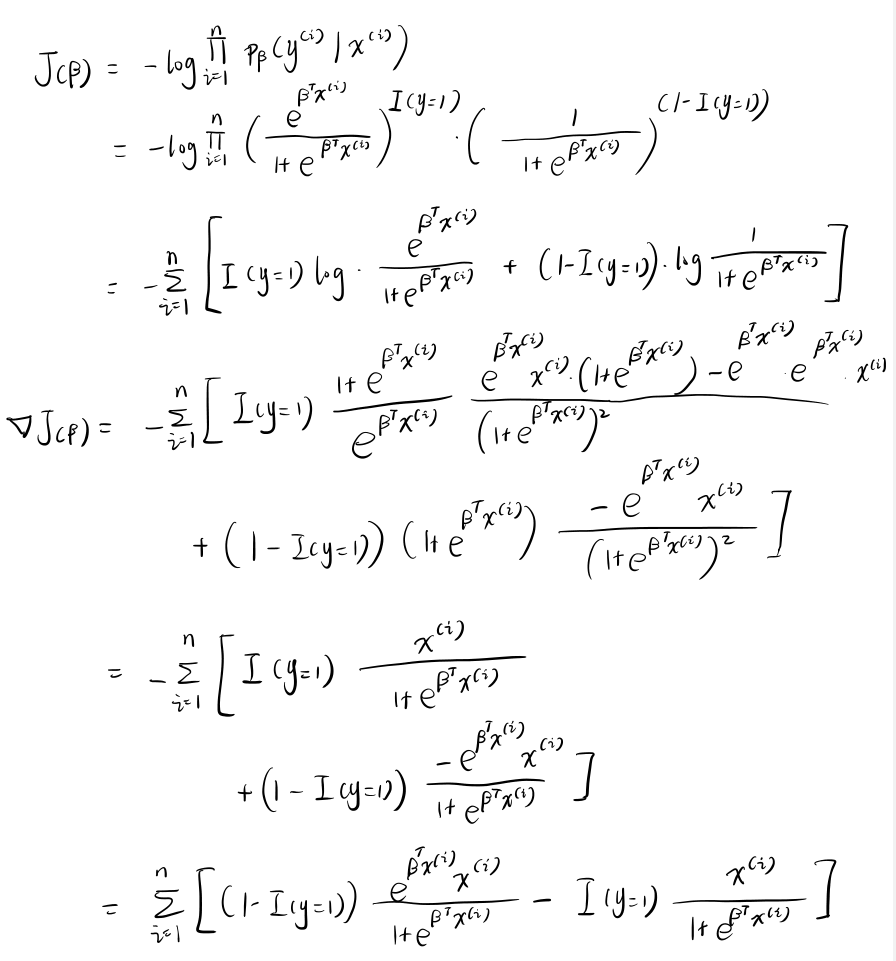
似然函数的 Hessian 矩阵¶
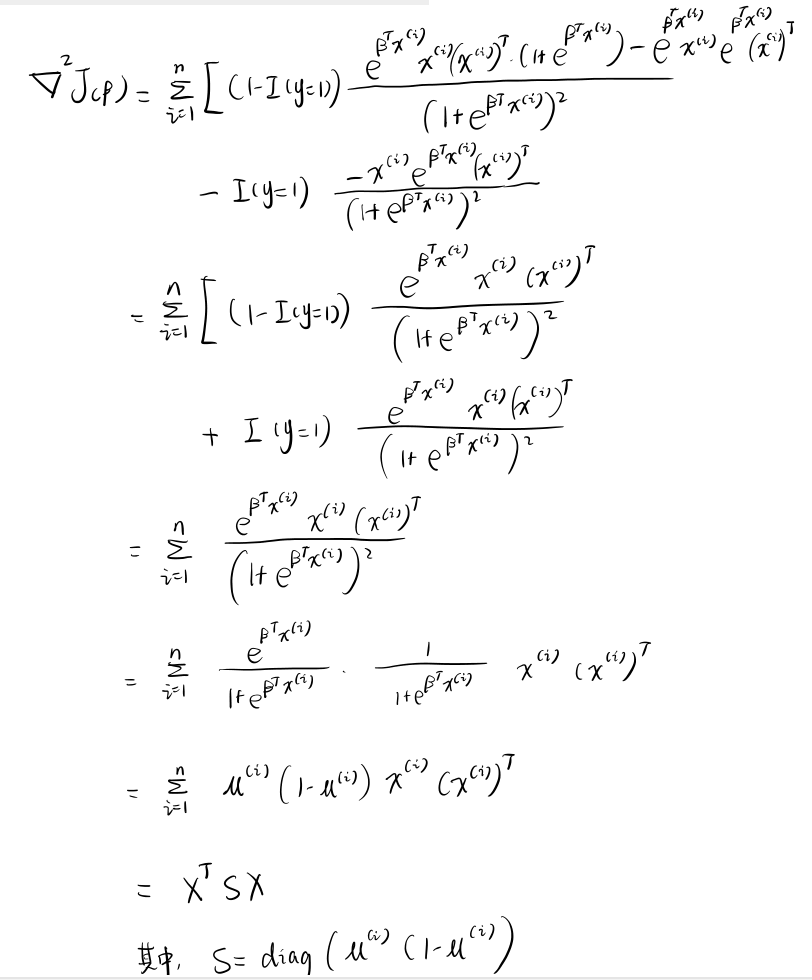
牛顿法算法步骤¶

回溯线搜索的牛顿法¶
![]()
拟牛顿 BFGS 法算法步骤¶


拟牛顿 BFGS 法中\(B\)矩阵的迭代公式¶


使用 Python 将牛顿法和拟牛顿 BFGS 法应用于求解\(\beta\)的极大似然估计¶
Python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# 支持中文
matplotlib.rcParams["font.sans-serif"] = ["SimSun"]
matplotlib.rcParams["axes.unicode_minus"] = False
导入数据¶
求对数似然函数的相反数值,即\(J(\beta)\)¶
Python
def f(X, Y, beta):
sum = 0
for i in range(Y.shape[0]):
product = np.exp(beta @ X[i])
if Y[i][0] == 1:
sum = sum + np.log(product / (1 + product))
else:
sum = sum + np.log(1 / (1 + product))
return -sum
求梯度向量¶
Python
def gradient(X, Y, beta):
# 将梯度向量初始化为零向量
gradient_vector = np.zeros(X.shape[1])
# 将 i 在 1 到 n 上遍历并加和,求梯度的值
for i in range(Y.shape[0]):
product = np.exp(beta @ X[i])
if Y[i][0] == 1:
gradient_vector = gradient_vector - X[i] / (1 + product)
else:
gradient_vector = gradient_vector + product * X[i] / (1 + product)
return gradient_vector
求 Hessian 矩阵。此题中的 Hessian 矩阵只与\(X\)和\(\beta\)有关,与\(Y\)无关¶
Python
def hessian(X, beta):
# 将 S 矩阵初始化。注意要初始化为 0.0,如果初始化为 0,则不能储存小数
S = np.diag(np.full(Y.shape[0], 0.0))
for i in range(Y.shape[0]):
product = np.exp(beta @ X[i])
u = product / (1 + product)
S[i, i] = u * (1 - u)
return X.T @ S @ X
应用牛顿法,结合回溯线搜索求\(\beta\)的极大似然估计¶
值得注意的是,最初我没有用回溯线搜索控制步长,导致\(\beta\)的模长很大,代入到梯度公式中,由于要计算指数,而\(\beta\)出现在指数中,从而指数的结果过于巨大甚至溢出。这说明不控制步长的话结果可能不收敛,反而在朝目标值的反方向迭代。
由此可见,回溯线搜索等控制步长的方法具有很大的实际意义。
Python
# 设置 beta 的初始点
beta = np.ones(X.shape[1])
# 计算当前梯度的模
norm = np.linalg.norm(gradient(X, Y, beta))
norm_list = [norm]
# 当梯度的模长大于精度要求时,需要一直迭代
while norm > 1e-5:
# 求 Hessian 矩阵
hessian_matrix = hessian(X, beta)
# 求 Hessian 矩阵的逆
hessian_matrix_inverse = np.linalg.inv(hessian_matrix)
# 求 beta 的迭代方向和长度
v = -hessian_matrix_inverse @ gradient(X, Y, beta)
# 设置步长倍数的初始值
t = 1
# 回溯线性搜索,检查目前的步长是否满足要求,若步长太大,则需要缩小步长为原来的 0.5
while f(X, Y, beta + t * v) > f(X, Y, beta) + 0.4 * t * gradient(X, Y, beta) @ v:
t = 0.5 * t
# 迭代更新 beta
beta = beta + t * v
# 求当前梯度的模长
norm = np.linalg.norm(gradient(X, Y, beta))
# 记录当前梯度的模长
norm_list.append(norm)
print("beta 的最大似然估计是:", beta)
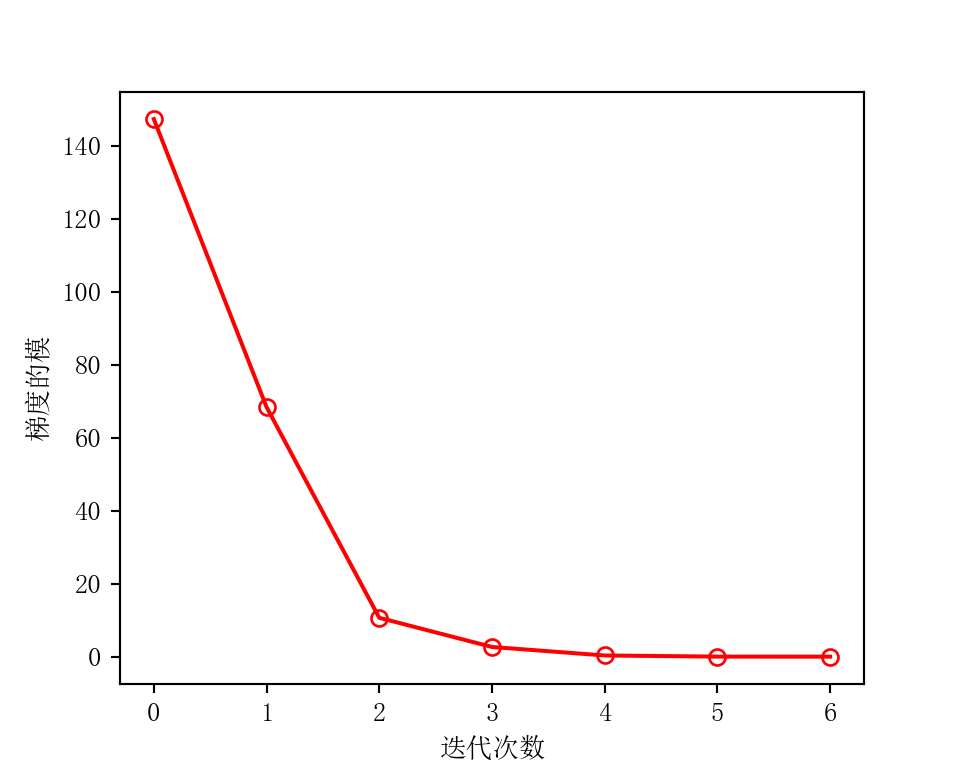
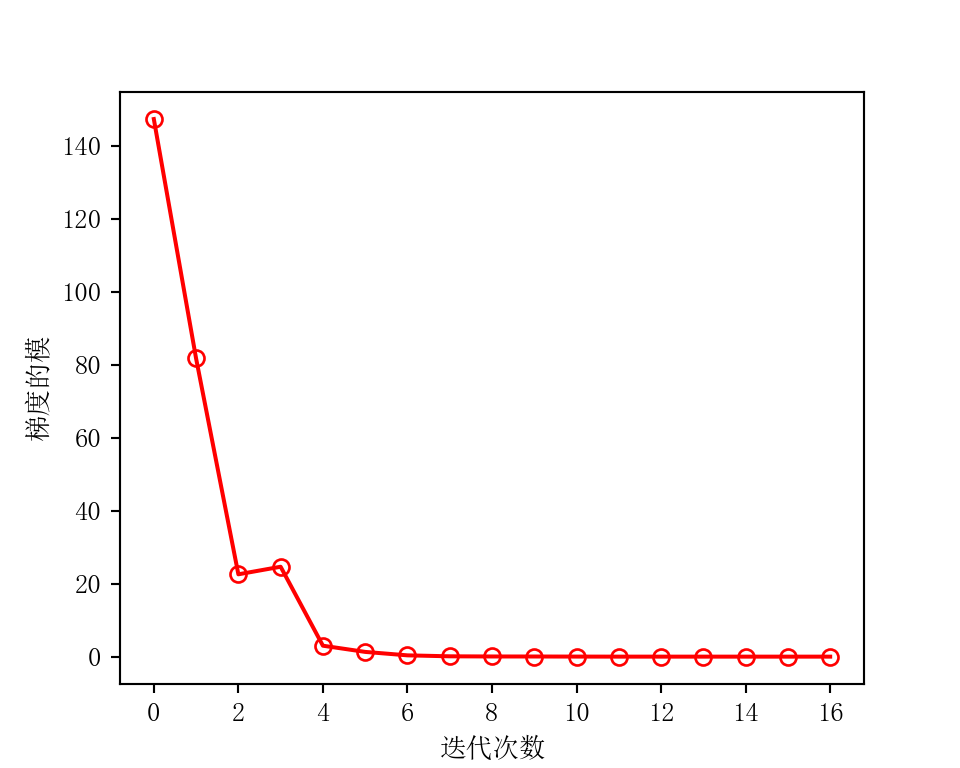
绘制迭代次数与梯度的模¶
Python
fig = plt.figure(figsize=(5, 4), dpi=200)
plt.plot(norm_list, "r-o", markerfacecolor="none") # 空心圆用 markerfacecolor='none',
plt.xlabel("迭代次数")
plt.ylabel("梯度的模")
应用拟牛顿法,结合回溯线搜索求\(\beta\)的极大似然估计¶
Python
# 设置 beta 的初始点
beta = np.ones(X.shape[1])
# 设置 B 的初始值,为一个对称正定矩阵
B = np.diag(np.full(X.shape[1], 10))
# 当梯度的模长大于精度要求时,需要一直迭代
# 求 g_k
g_k = gradient(X, Y, beta)
# 计算当前梯度的模
norm = np.linalg.norm(g_k)
norm_list = [norm]
while norm > 1e-5:
# 求迭代的方向和步长
p = -np.linalg.inv(B) @ g_k
# 设置步长倍数的初始值
t = 1
# 回溯线性搜索,检查目前的步长是否满足要求,若步长太大,则需要缩小步长为原来的 0.5
while f(X, Y, beta + t * p) > f(X, Y, beta) + 0.4 * t * g_k @ p:
t = 0.5 * t
# 迭代更新 B
# 求 g_{k+1}
g_k_plus_1 = gradient(X, Y, beta + t * p)
# 求 y_k
y_k = g_k_plus_1 - g_k
# 求 sigma_k
sigma_k = t * p
# 迭代更新 B
B = (
B
+ (np.outer(y_k, y_k)) / (y_k @ sigma_k)
- (np.outer(B.dot(sigma_k), (sigma_k.T)).dot(B.T)) / (sigma_k.T @ B @ sigma_k)
)
# 迭代更新 beta
beta = beta + t * p
# 求当前梯度
g_k = gradient(X, Y, beta)
# 求当前梯度的模长
norm = np.linalg.norm(g_k)
# 记录当前梯度的模长
norm_list.append(norm)
print("beta 的最大似然估计是:", beta)
绘制迭代次数与梯度的模¶
Python
fig = plt.figure(figsize=(5, 4), dpi=200)
plt.plot(norm_list, "r-o", markerfacecolor="none") # 空心圆用 markerfacecolor='none',
plt.xlabel("迭代次数", usetex=False) # 中文不用 tex 渲染,否则会报错
plt.ylabel("梯度的模", usetex=False)
利用训练出的\(\beta\)值,对\(Y\)进行预测¶
Python
df["p_predict"] = np.nan
df["Y_predict"] = np.nan
df["correct"] = np.nan
df["p_predict"] = df.apply(
lambda line: 1 / (1 + np.exp(-line.iloc[2:7] @ beta)), axis=1
)
# 设定判断阈值
hurdle = 0.5
df["Y_predict"] = df.apply(lambda line: 1 if line["p_predict"] > hurdle else 0, axis=1)
df["correct"] = df.apply(
lambda line: 1 if line["Y_predict"] == line["Y"] else 0, axis=1
)
计算预测准确率¶
Text Only
## Unnamed: 0 Y X1 X2 ... X5 p_predict Y_predict correct
## 0 1 0 0.227077 -0.492374 ... 0.337587 0.074140 0 1
## 1 2 1 -1.439121 -0.898333 ... -1.729708 0.840268 1 1
## 2 3 0 -0.252111 -0.274725 ... -0.705981 0.654752 1 0
## 3 4 1 -1.736983 -1.197634 ... -1.266615 0.471904 0 0
## 4 5 1 -1.081011 -0.283816 ... -0.937780 0.639866 1 1
## .. ... .. ... ... ... ... ... ... ...
## 195 196 1 -0.555757 -0.483450 ... -1.764113 0.993497 1 1
## 196 197 0 -0.581243 -0.590711 ... 0.485322 0.057910 0 1
## 197 198 0 -1.752883 -0.934694 ... 0.876816 0.004954 0 1
## 198 199 1 0.397383 0.231328 ... 0.902995 0.121900 0 0
## 199 200 1 1.127998 1.487247 ... 0.228712 0.963261 1 1
##
## [200 rows x 10 columns]