PyTorch 基础¶
本文是深度学习课程的学习笔记,介绍了:
- 安装 GPU 版本的 PyTorch。
- PyTorch 的基本用法,例如创建张量、张量运算、求解梯度等。
安装 GPU 版本的 PyTorch¶
安装 PyTorch 的步骤见这篇文章,可以避免之前踩过的坑,整个过程应该十分顺利。
值得再次注意的地方:
- 网络环境要稳定,不要切换代理的开关,不要切换网络。
- 以管理员身份打开
Anaconda Prompt (miniconda3),可以避免一些报错。 - 为 PyTorch 创建一个新的 Conda 环境。
PyTorch 的基本用法¶
张量¶
创建连续数组的张量¶

计算元素总个数¶
reshape¶

生成全是 0 的张量¶

生成全是 1 的张量¶

以正态分布初始化张量¶

从列表创建张量¶
Python
# list to tensor,列表转为 tensor
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]], dtype=int)

张量之间的运算¶
例如加、减、乘、除、平方。
Python
# tensor 运算
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x**y

指数运算
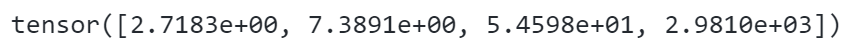
拼接张量(上下拼接、左右拼接)¶
Python
# concatenation 拼接两个 tensor
X = torch.arange(12, dtype=torch.float32).reshape((3, 4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)

转换张量元素的数据类型¶

判断两个张量对应元素是否相等¶

对张量的所有元素求和¶

也可以将所有的axis全部写出,效果一样:
不同维度的张量相加,利用广播机制¶
Python
# add with different shape,广播机制
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a, b, a + b

利用索引进行切片¶

利用索引进行赋值¶

赋值时使用原地址,以节约内存¶
常规赋值语句,会占用新内存:
使用Y += X,保存的 Y 的地址没有发生改变,可以节约内存:
将张量转换为 np.ndarray¶
若张量中只有一个值,可以用三种方法将张量转换为标量¶
对张量矩阵中的每一行进行 softmax,使得每行之和都为 1¶
Python
A = torch.arange(20).reshape(5, 4)
torch.softmax(A.float(), dim=1)
# tensor([[0.0321, 0.0871, 0.2369, 0.6439],
# [0.0321, 0.0871, 0.2369, 0.6439],
# [0.0321, 0.0871, 0.2369, 0.6439],
# [0.0321, 0.0871, 0.2369, 0.6439],
# [0.0321, 0.0871, 0.2369, 0.6439]])
张量矩阵转置¶
Python
A.T
# tensor([[ 0, 4, 8, 12, 16],
# [ 1, 5, 9, 13, 17],
# [ 2, 6, 10, 14, 18],
# [ 3, 7, 11, 15, 19]])
高维张量¶
Python
X = torch.arange(24).reshape(2, 3, 4)
# tensor([[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]],
# [[12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23]]])
在不同维度上求和¶
Python
X.sum(axis=0)
# tensor([[12, 14, 16, 18],
# [20, 22, 24, 26],
# [28, 30, 32, 34]])
X.sum(axis=1)
# tensor([[12, 15, 18, 21],
# [48, 51, 54, 57]])
X.sum(axis=2)
# tensor([[ 6, 22, 38],
# [54, 70, 86]])
分配新内存用于赋值新变量¶
Python
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
B = A.clone() # 通过分配新内存,将 A 的⼀个副本分配给 B
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.],
# [16., 17., 18., 19.]])
求和后保持原始维度,不自动降维¶
累积求和¶
例如在列的方向上累积求和:
Python
A.cumsum(axis=0)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 6., 8., 10.],
# [12., 15., 18., 21.],
# [24., 28., 32., 36.],
# [40., 45., 50., 55.]])
矩阵和向量的乘积¶
mv 代表 matrix 和 vector。
矩阵和矩阵的乘积¶
mm代表 matrix 和 matrix。
Python
B = torch.ones(4, 3)
torch.mm(A, B)
# tensor([[ 6., 6., 6.],
# [22., 22., 22.],
# [38., 38., 38.],
# [54., 54., 54.],
# [70., 70., 70.]])
矩阵的范数¶
torch.norm(p=2) 默认求二范数。
可以先对各元素求绝对值,再求和,即可得到一范数。或者用 torch.norm(p=1)
从现有数据导入为张量¶
创建文件夹,若已经存在则不创建¶
将字符串写入csv文件¶
Python
data_file = "./chpdata/house_tiny.csv"
with open(data_file, "w") as f:
f.write("NumRooms,Alley,Price\n") # 列名
f.write("NA,Pave,127500\n") # 每⾏表⽰⼀个数据样本
f.write("2,NA,106000\n")
f.write("4,NA,178100\n")
f.write("NA,NA,140000\n")
读取csv文件¶
Python
data = pd.read_csv(data_file)
print(data)
# NumRooms Alley Price
# 0 NaN Pave 127500
# 1 2.0 NaN 106000
# 2 4.0 NaN 178100
# 3 NaN NaN 140000
划分特征和标签,用均值填充缺失值¶
Python
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
print(inputs)
# NumRooms Alley
# 0 3.0 Pave
# 1 2.0 NaN
# 2 4.0 NaN
# 3 3.0 NaN
将类别型变量转换为哑变量¶
Python
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
# NumRooms Alley_Pave Alley_nan
# 0 3.0 1 0
# 1 2.0 0 1
# 2 4.0 0 1
# 3 3.0 0 1
将数据导入为张量¶

梯度¶
定义导数,将自变量的变化量逐渐缩小,查看导数的变化:
Python
def f(x):
return 3 * x**2 - 4 * x
def numerical_lim(f, x, h):
return (f(x + h) - f(x)) / h
h = 0.1
for i in range(5):
print(f"h={h:.5f}, numerical limit={numerical_lim(f, 1, h):.5f}")
h *= 0.1
# h=0.10000, numerical limit=2.30000
# h=0.01000, numerical limit=2.03000
# h=0.00100, numerical limit=2.00300
# h=0.00010, numerical limit=2.00030
# h=0.00001, numerical limit=2.00003
自动求导¶
Python
x = torch.arange(4.0)
# tensor([0., 1., 2., 3.], requires_grad=True)
x.requires_grad_(True)
y = 2 * torch.dot(x, x)
y.backward()
x.grad
# tensor([ 0., 4., 8., 12.])
清空梯度¶
若不清空x的梯度,当继续求导时,梯度会累积:
可以用x.grad.zero_()将梯度清空:
指定函数的一部分参与求导,另一部分不参与求导¶
Python
x = torch.tensor(1.0, requires_grad=True)
y1 = x**2
with torch.no_grad():
y2 = x**3
y3 = y1 + y2
print(x.requires_grad)
print(y1, y1.requires_grad) # True
print(y2, y2.requires_grad) # False
print(y3, y3.requires_grad) # True
# True
# tensor(1., grad_fn=<PowBackward0>) True
# tensor(1.) False
# tensor(2., grad_fn=<AddBackward0>) True
此时用将y3对x求导,只有y1的部分参与了求导:
概率分布¶
均匀分布¶
多项分布¶
Python
n = 100
multinomial.Multinomial(n, fair_probs).sample() / n
# tensor([0.1700, 0.1700, 0.1600, 0.1200, 0.2300, 0.1500])
生成多个样本:
Python
# 500 trials, 10 sample each trial
counts = multinomial.Multinomial(10, fair_probs).sample((500,))
# tensor([[1., 1., 2., 3., 1., 2.],
# [2., 2., 0., 2., 4., 0.],
# [0., 2., 2., 1., 3., 2.],
# ...,
# [3., 0., 1., 2., 3., 1.],
# [2., 2., 1., 3., 2., 0.],
# [5., 1., 1., 1., 2., 0.]])
cum_counts = counts.cumsum(dim=0)
# tensor([[ 1., 1., 2., 3., 1., 2.],
# [ 3., 3., 2., 5., 5., 2.],
# [ 3., 5., 4., 6., 8., 4.],
# ...,
# [833., 812., 800., 857., 829., 849.],
# [835., 814., 801., 860., 831., 849.],
# [840., 815., 802., 861., 833., 849.]])
查看所有内置的分布¶
Python
print(dir(torch.distributions))
# ['AbsTransform', 'AffineTransform', 'Bernoulli', 'Beta', 'Binomial', 'CatTransform', 'Categorical', 'Cauchy', 'Chi2', 'ComposeTransform', 'ContinuousBernoulli', 'Dirichlet', 'Distribution', 'ExpTransform', 'Exponential', 'ExponentialFamily', 'FisherSnedecor', 'Gamma', 'Geometric', 'Gumbel', 'HalfCauchy', 'HalfNormal', 'Independent', 'Laplace', 'LogNormal', 'LogisticNormal', 'LowRankMultivariateNormal', 'LowerCholeskyTransform', 'MixtureSameFamily', 'Multinomial', 'MultivariateNormal', 'NegativeBinomial', 'Normal', 'OneHotCategorical', 'Pareto', 'Poisson', 'PowerTransform', 'RelaxedBernoulli', 'RelaxedOneHotCategorical', 'SigmoidTransform', 'SoftmaxTransform', 'StackTransform', 'StickBreakingTransform', 'StudentT', 'TanhTransform', 'Transform', 'TransformedDistribution', 'Uniform', 'VonMises', 'Weibull', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'bernoulli', 'beta', 'biject_to', 'binomial', 'categorical', 'cauchy', 'chi2', 'constraint_registry', 'constraints', 'continuous_bernoulli', 'dirichlet', 'distribution', 'exp_family', 'exponential', 'fishersnedecor', 'gamma', 'geometric', 'gumbel', 'half_cauchy', 'half_normal', 'identity_transform', 'independent', 'kl', 'kl_divergence', 'laplace', 'log_normal', 'logistic_normal', 'lowrank_multivariate_normal', 'mixture_same_family', 'multinomial', 'multivariate_normal', 'negative_binomial', 'normal', 'one_hot_categorical', 'pareto', 'poisson', 'register_kl', 'relaxed_bernoulli', 'relaxed_categorical', 'studentT', 'transform_to', 'transformed_distribution', 'transforms', 'uniform', 'utils', 'von_mises', 'weibull']
查看帮助¶
Python
help(torch.poisson)
# Help on built-in function poisson:
# poisson(...)
# poisson(input *, generator=None) -> Tensor
# Returns a tensor of the same size as :attr:`input` with each element
# sampled from a Poisson distribution with rate parameter given by the corresponding
# element in :attr:`input` i.e.,
# .. math::
# \text{out}_i \sim \text{Poisson}(\text{input}_i)
# Args:
# input (Tensor): the input tensor containing the rates of the Poisson distribution
# Keyword args:
# generator (:class:`torch.Generator`, optional): a pseudorandom number generator for sampling
# Example::
# >>> rates = torch.rand(4, 4) * 5 # rate parameter between 0 and 5
# >>> torch.poisson(rates)
# tensor([[9., 1., 3., 5.],
# [8., 6., 6., 0.],
# [0., 4., 5., 3.],
# [2., 1., 4., 2.]])
[0,1] 均匀分布¶
标准正态分布¶
使用 NumPy 中的随机数生成器¶
从列表中随机取数¶
Python
# sample from a list
# 从 0,1,2,3 中不放回地抽取 2 个数
np.random.choice(4, 2, replace=False)
a = [5, 8, 10]
np.random.choice(a, 1)