量化投资策略设计与分析 - 因子投资¶
本文是 2023 年 3 月 4 日的量化投资策略设计与分析的课程笔记,本节课系统地介绍了因子投资的实践方法与注意事项。
单因子排序法¶
步骤¶
- 排序:确定股票池并将股票池中的全部股票在截面上按照排序变量的取值高低排序。
- 分组:按排名高低将全部股票分为 L 组 (一般根据变量取值的十分位数分为十组,即 L=10)。做多第一组,做空最后一组,该组合被称为价差组合 (spread portfolio),价差组合的收益的差异反映了围绕该变量构建的因子的收益率,通常要求两个组合的资金是相同的,即资金中性,加权方式常见的是市值加权和等权重。
- 定期更新:即再平衡 (re-balance),频率多为每周,每月或每年。
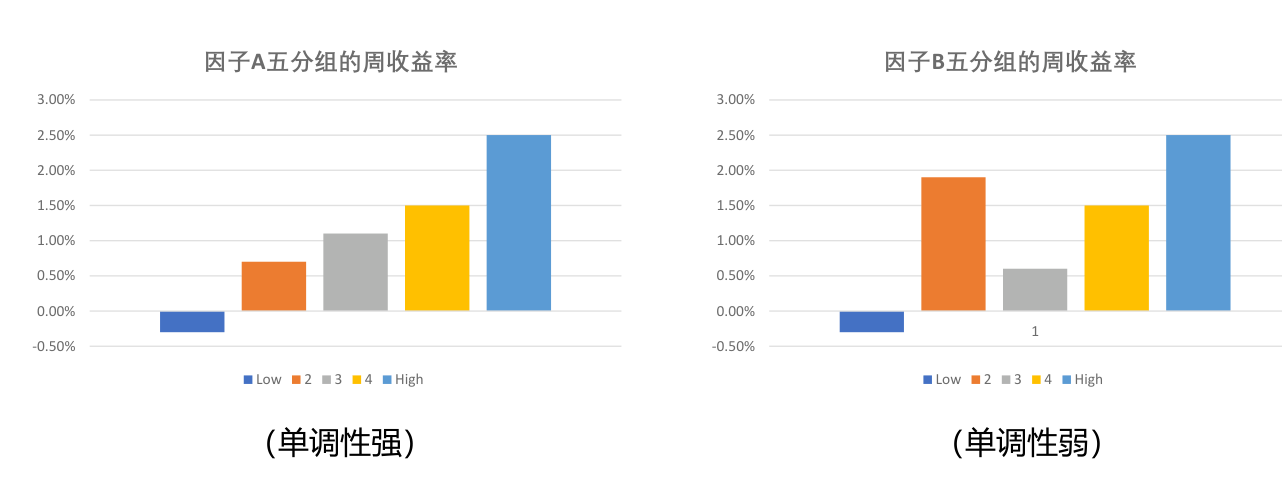
分析因子大小与收益率的单调性¶
排序法关注的问题就是依照排序变量高低得到的 L 个投资组合的收益率是否有很好的单调性,这个可以通过计算收益率和排序变量分组的秩相关系数来检验。
单调性指标-Spearman 秩相关系数¶

一般要求因子的秩相关系数的绝对值要达到 80% 以上。
双重排序法¶
常用的有独立双重排序和条件双重排序。

独立双重排序¶
排序结果¶
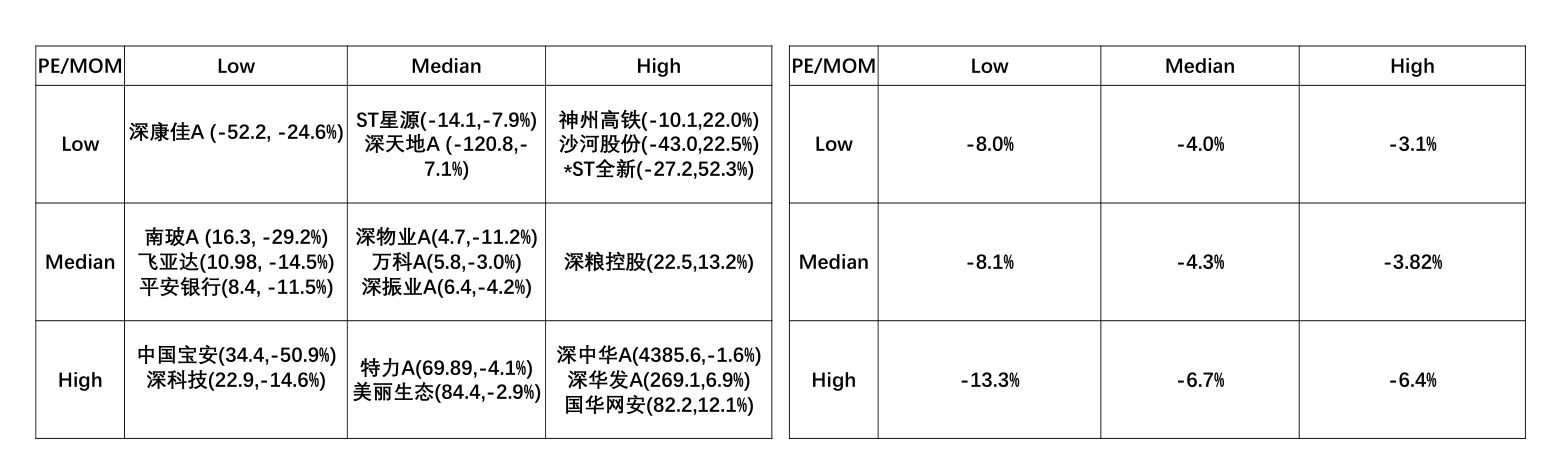
缺点:某些组合包含的股票数目可能过少。
例:当 X1 和 X2 的截面相关性很高时,一只股票在 X1 变量取值较高时,它在 X2 变量取值也会较高,就会造成对角线的组股票个数较多,其他组个数较少,使得最终因子收益受异常值影响的可能性更高。比如营业额增长率和净利润增长率这两个因子,有可能很难找到前者较小且后者较大的股票,那么这个细分组内的股票数量就很少。
条件双重排序¶
排序结果¶
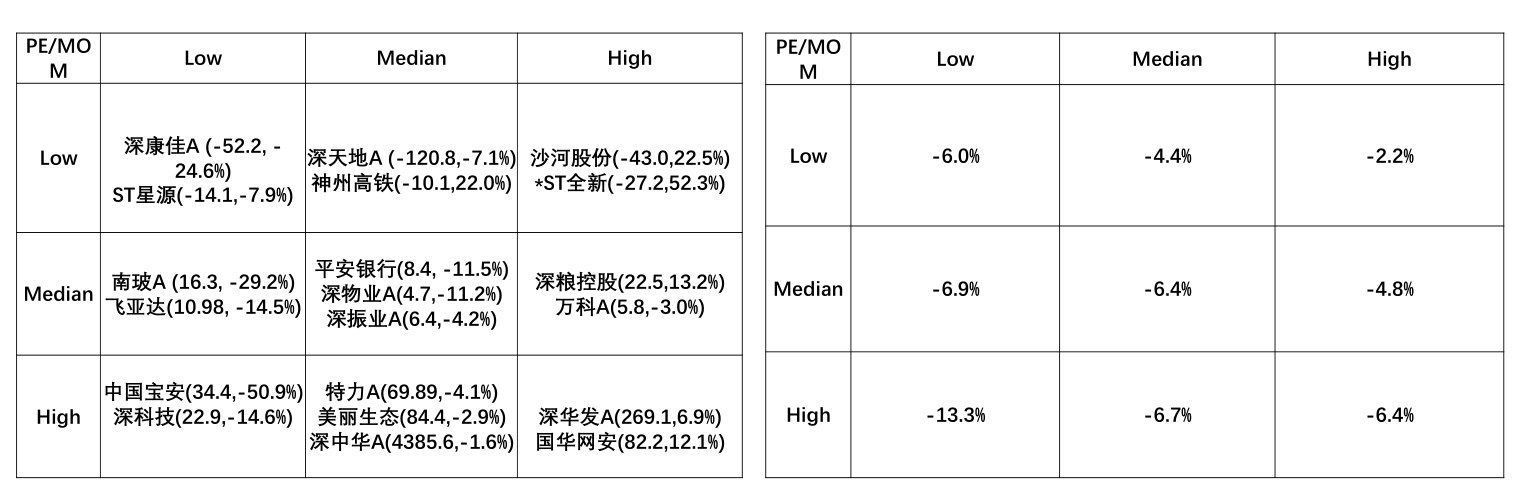
可以保持每个细分组内的股票数量较均匀。
Tip
第一个分组的因子对结果影响更大!
排序法分析因子绩效¶
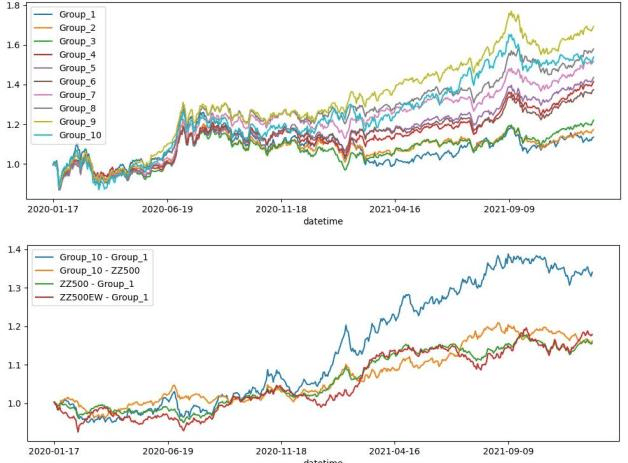
多空组合净值曲线¶
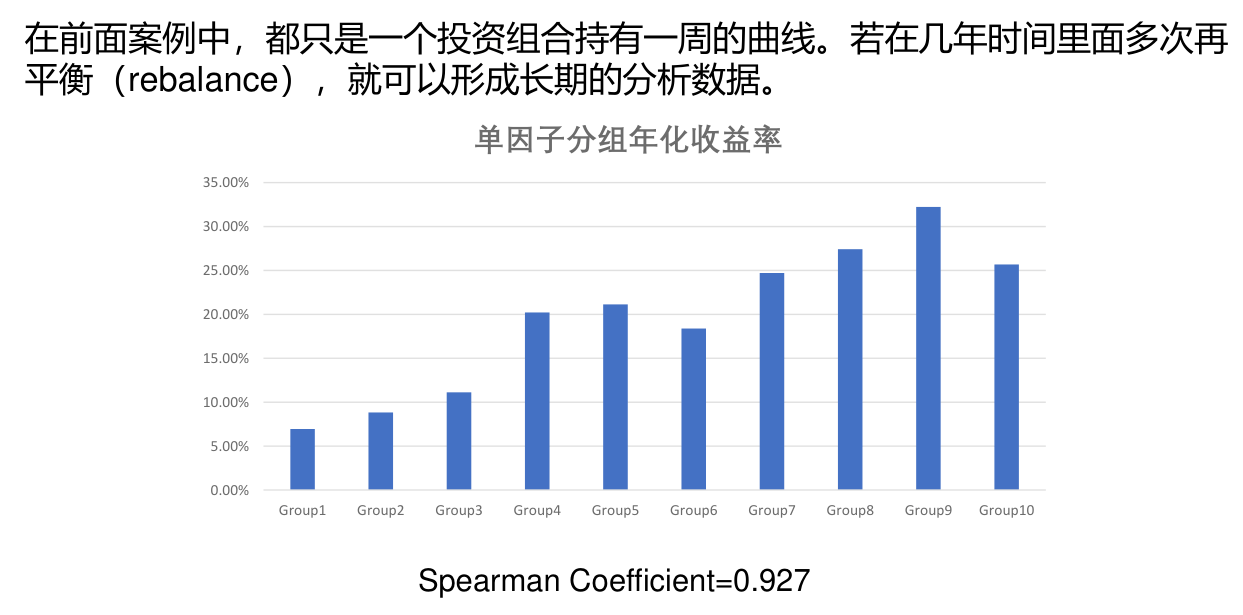
单因子分组年化收益率¶
分组组合的业绩统计¶

分组组合的净值曲线¶
手续费与冲击成本¶
手续费¶
- 交易所收手续费是千分之一。
- 券商对散户的佣金是万二左右。
- 券商在交易所的交易成本大概是万 0.8 到万 0.9。
冲击成本¶
对于大型金融机构来说,手续费、佣金并不是最大的交易成本。交易滑点会导致无法按照预期价格成交,这种冲击成本才是更需要考虑的。
经验
一般持有一只股票的金额要控制在这只股票总流通股本的 1%。高于 5% 需要举牌,且在股灾来临时不易脱身。
主流因子¶
市场因子¶
构建方法¶
下图中的 \(\beta\) 即为市场因子。

成因¶
高风险、高收益。
分组收益率¶
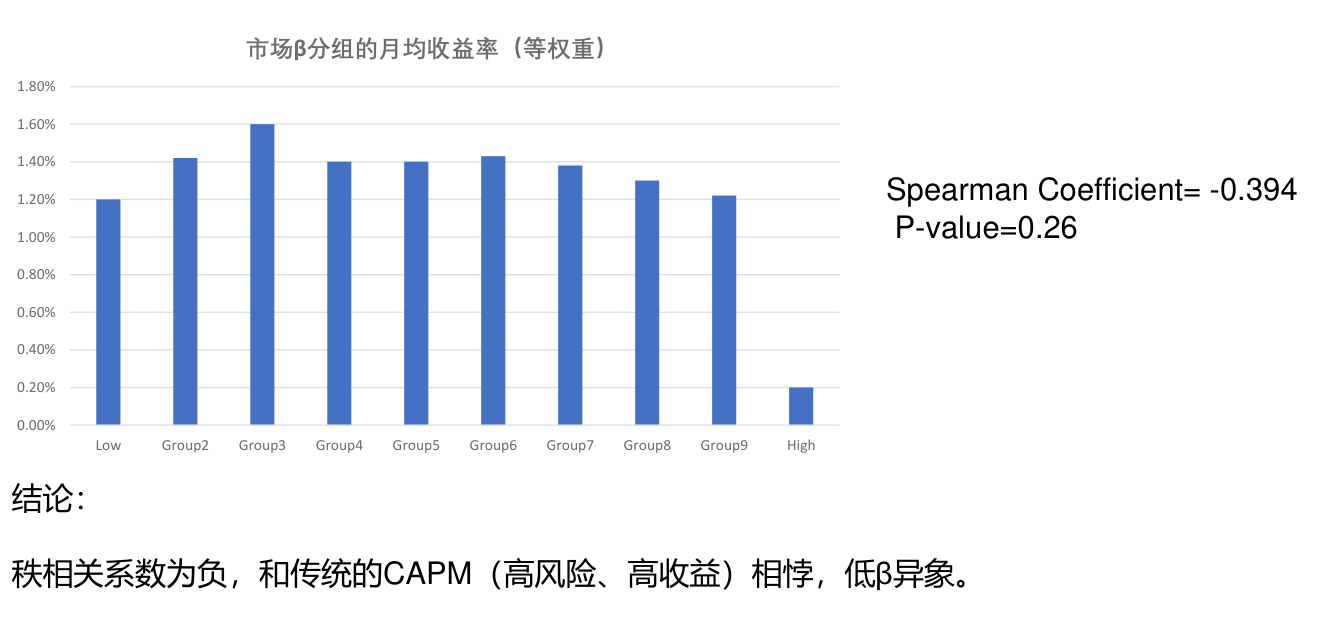
高 \(\beta\) 组的收益并不是最高的,反而出现了低 \(\beta\) 异象。
市场因子是很重要的风险因子,经常用其它因子对市场因子做正交化。
规模因子¶
构建方法¶
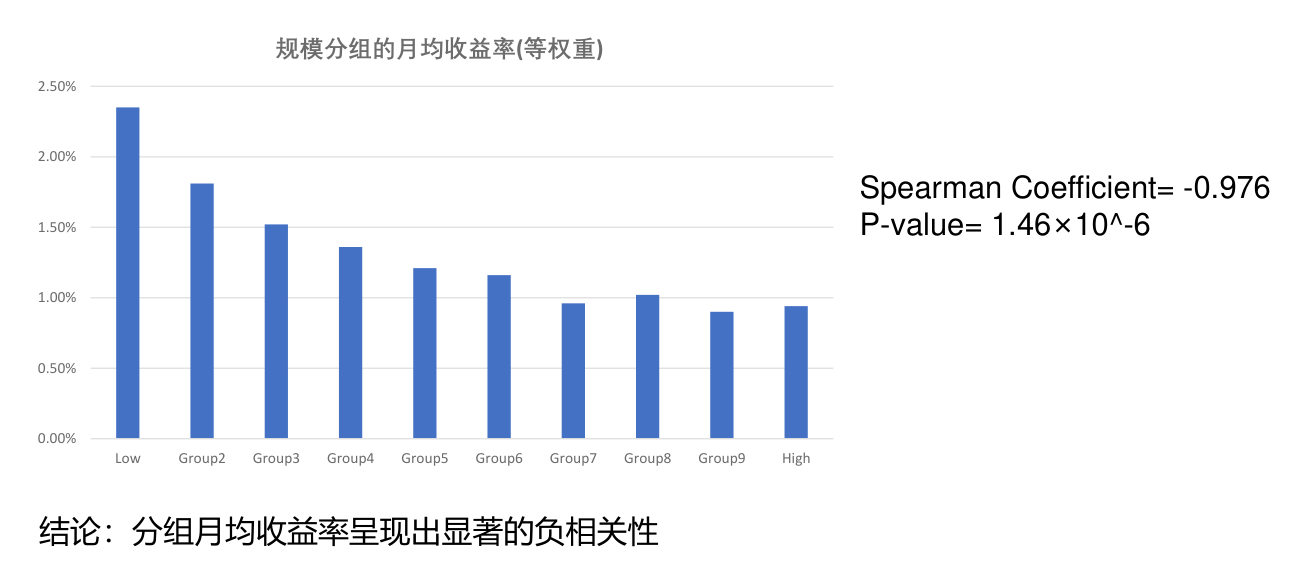
实证中,采用总市值为排序变量构建规模因子,按照市值从小到大分成 10 组,通过做多小市值组、做空大市值组即可得到规模因子的收益率。
成因¶
- 投资者对小盘股的规避效应:由于难以获得准确的信息,投资者普遍不愿意持有小 市值股票,使得这些股票的价格低于规模较大的股票,因而有着较高的预期收益。
- 也有其他研究提出了风险补偿说、投资者行为偏好和模型设定偏误等多种解释。
分组收益率¶
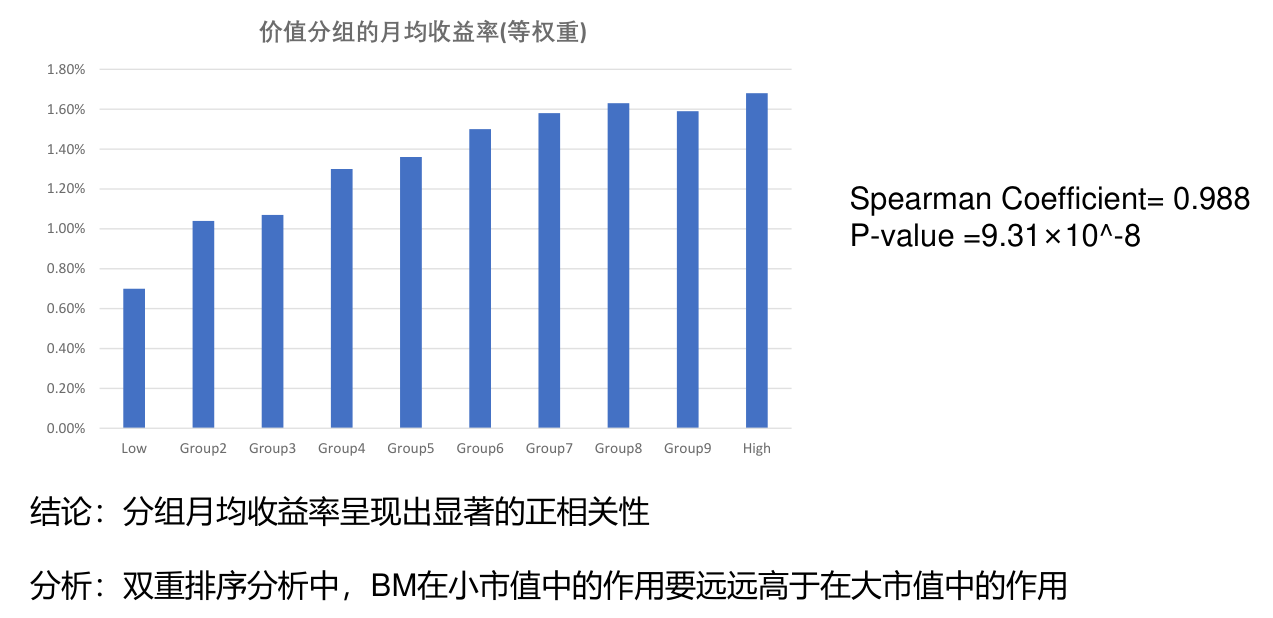
价值因子¶
构建方法¶
实证中,采用 BM 为排序变量构建规模因子,按照 BM 从小到大分成 10 组,进一步,通过做多高 BM、做空低 BM 组即可得到价值因子的收益率。
BM: Book-to-market,即账面市值比。
成因¶
- 系统性风险补偿(财务困境风险假说:即高 BM 可能反映着更高的财务困境风险)
- 投资者行为偏差:如投资者对过去盈利不佳的企业过度悲观导致了价值效应。
分组收益率¶
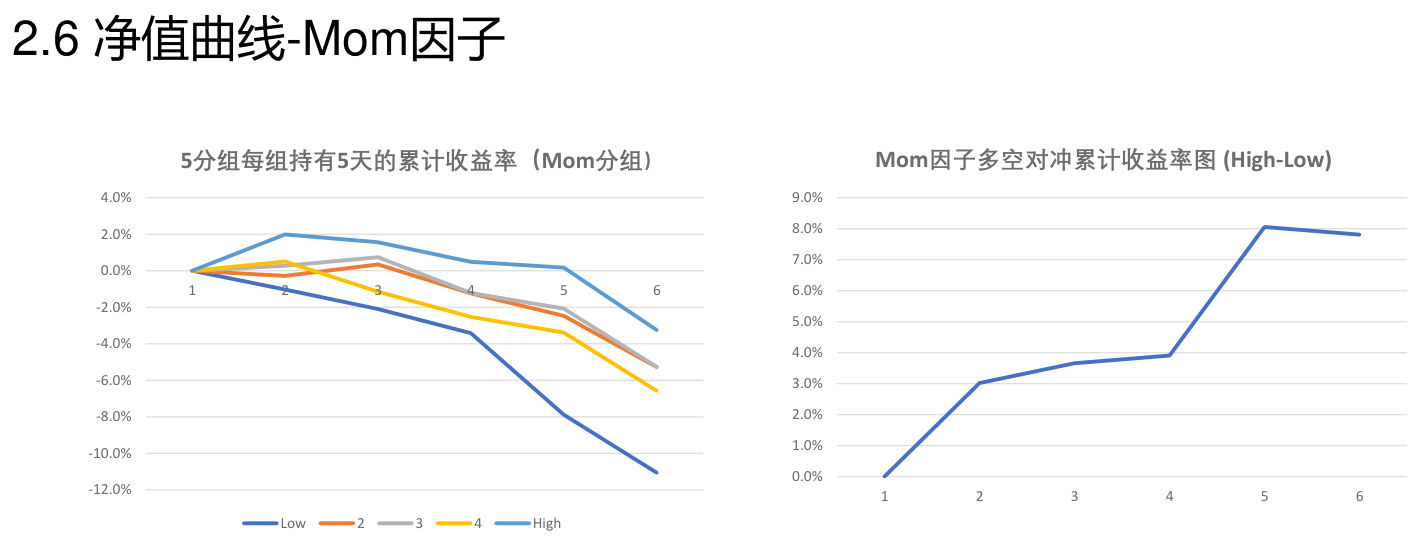
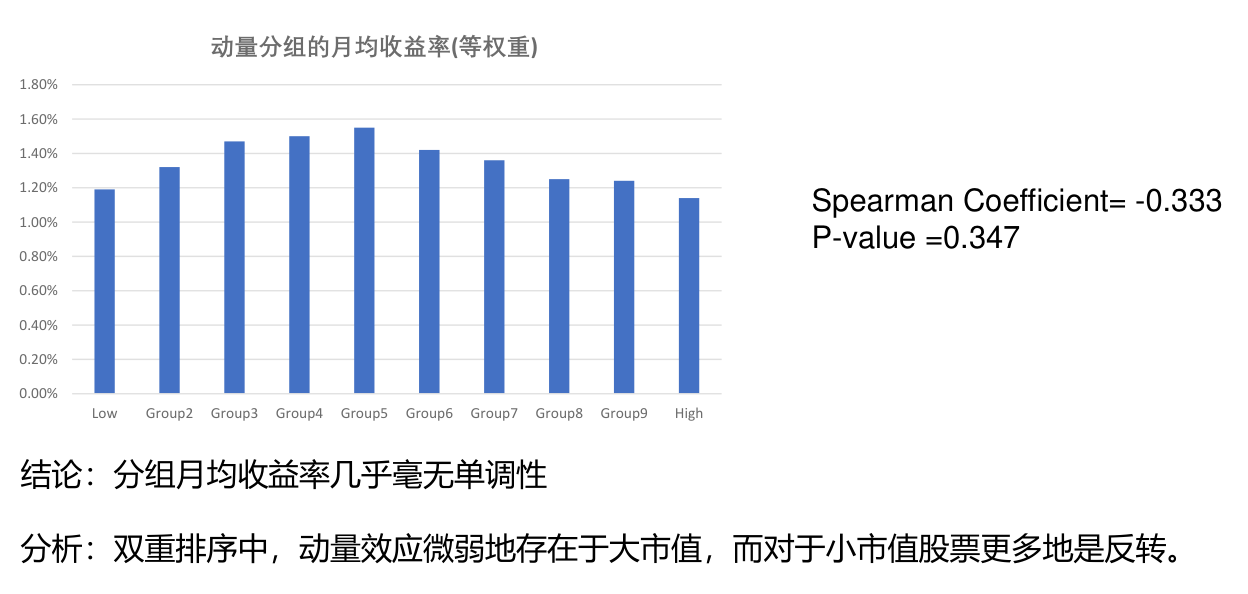
动量因子¶
构建方法¶
做多过去一段时间表现最好的股票(称为赢家组合)、同时做空这段时间表现最差的股票(称为输家组合);Jegadeesh and Titman(1993) 在每月月末,依据过去 X 个月的股票总收益率排序,将股票分为 10 组,按照等权重方式做多收益率最高的一组股票,同时做空收益率最低的一组股票,并持有 Y 个月。
成因¶
- 系统性风险敞口(相应需要获得风险溢价补偿)
- 投资者行为偏差
分组收益率¶
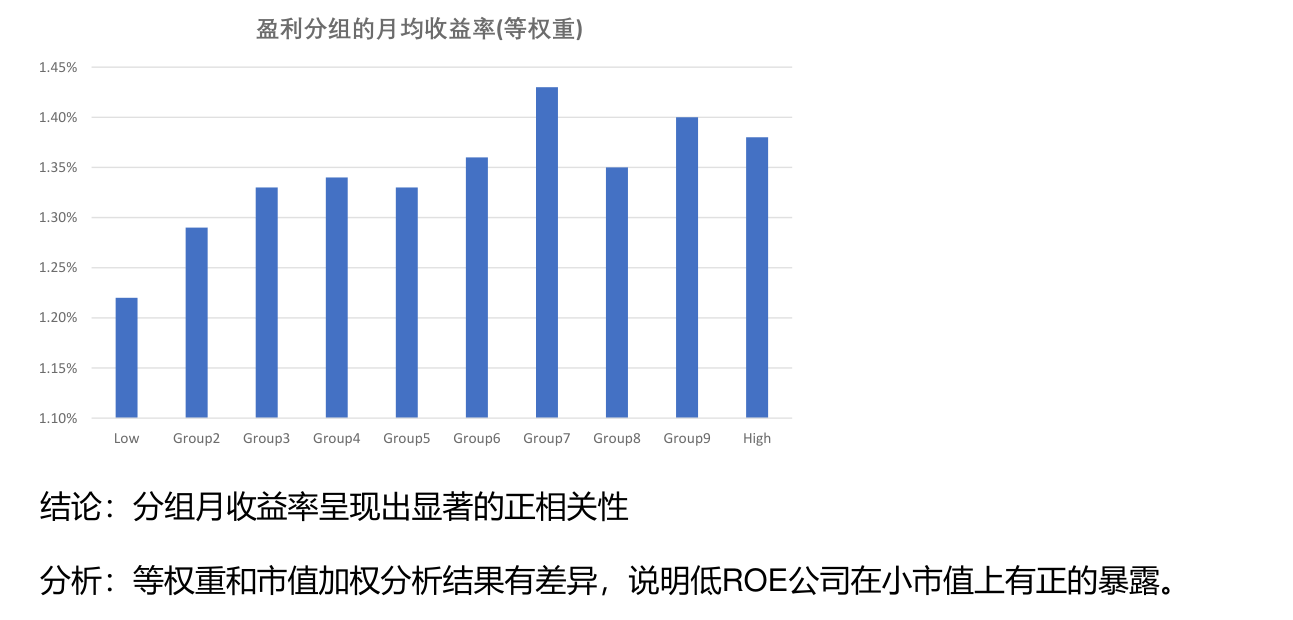
盈利因子¶
构建方法¶
利用绝对盈利水平来度量盈利能力。然而,为了保证指标在不同公司间可比,在计算时通常需要用诸如总资产、销售收入等对盈利水平进行标准化。在诸多变量中,最常用的是净资产收益率(ROE),此外,还有总资产收益率(ROA)和有形资本收益率(ROTC)。
成因¶
- Fama and French(2006, 2015) 从股利贴现模型出发推导了预期盈利和股票预期收益率之间的关系。
- Hou et al. (2015) 则以实体投资经济学理论为基础建立了预期利润。
- 不少其他研究也探索了盈利水平之外的维度,包括盈利质量、盈利波动和盈利增长等。
分组收益率¶
换手率因子¶
构建方法¶
一般采用异常换手率作为排序变量构建换手率因子,每月末将股票按照过去 21 交易日平均换手率和过去 252 交易日平均换手率的比值从低到高分成 10 组,通过做多最低组、做空最高组即可得到换手率因子的收益率。
成因¶
早期研究大多将成交量和换手率当做流动性的一种度量,也有研究认为其与市场的总体波动率相关。此外,从行为金融学角度,也有研究指出换手率反映了投资者非理性情绪如过度自信、盲目乐观等。同时,还有学者分析了异常成交量对股票收益的影响。
分组收益率¶
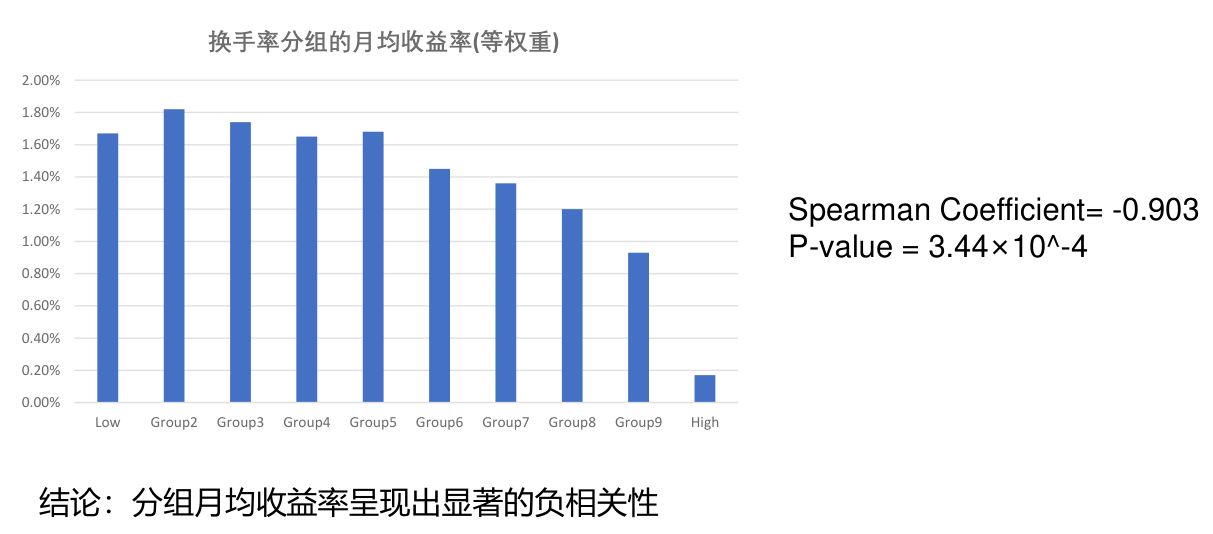
换手率高的股票收益率较低,这可能与散户追热点有关系。
多因子研究¶
因子正交化¶
多个高度相关的因子,其收益来源可能相同,我们需要提取每个因子的独立剩余信息。
方法一:回归取残差¶
目标因子与其它风格因子回归取残差,由于残差项与被解释变量不相关,从而达到剔除相关性的效果。
残差的均值是 0,相当于得到了相对来说量纲更一致的因子(原始因子的均值可以是任意数,量纲可能千差万别)。
方法二:构造纯因子投资组合¶
参考《因子投资 方法与实践》第 310 至 312 页的内容。
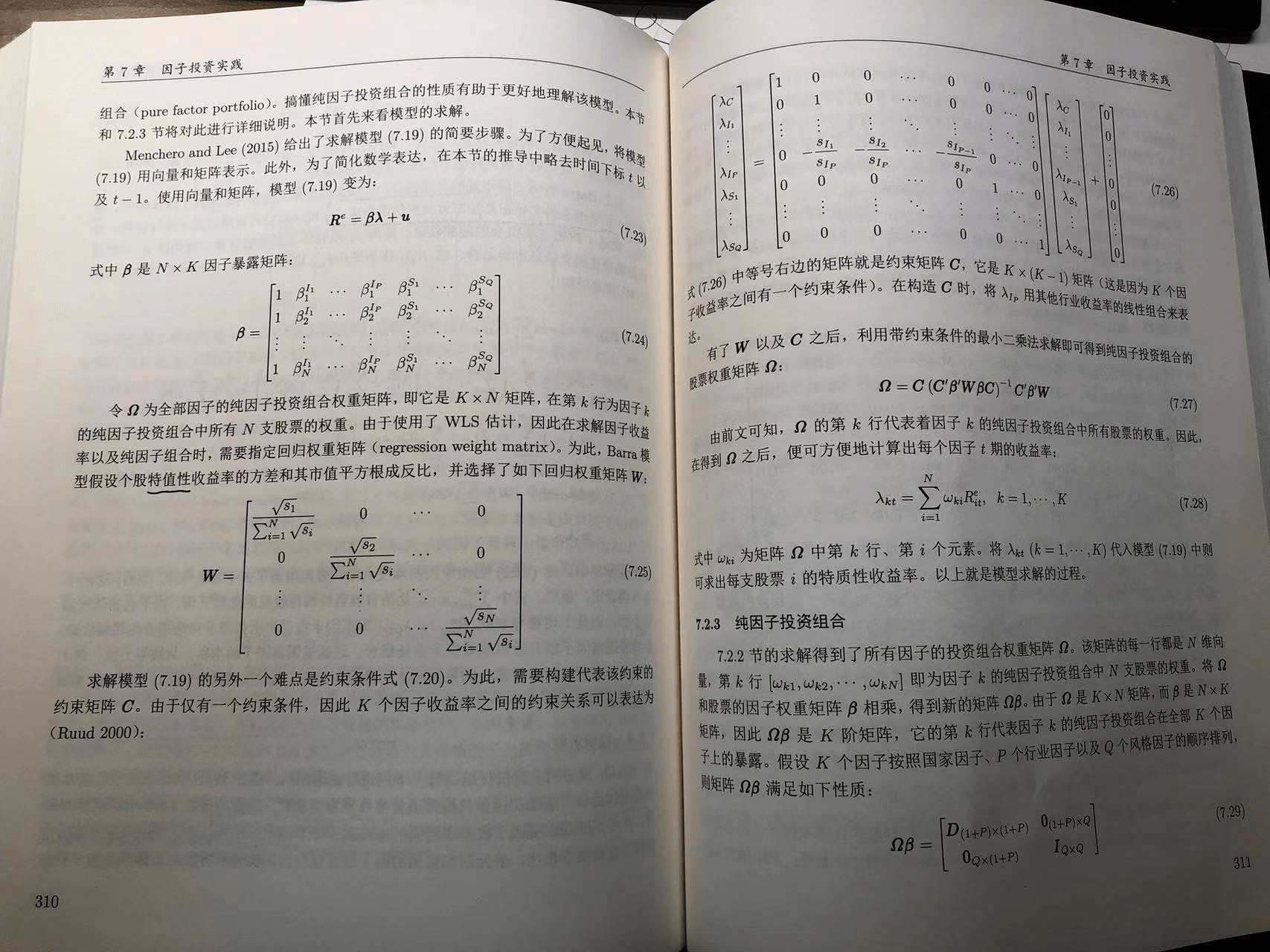

数据处理注意事项¶
财务数据¶
考虑到数据的时效性,我们应该用各家公司发布财报的日期向后填充数据,保证每一个时间截面上使用的都是各家公司能得到的最新数据。
如果用的数据在回测时期还没有发布,就不能用这个数据,否则会严重影响回测结果。
注意
切记不要用未来数据!
借壳上市¶
含义¶
为了绕开 IPO,有些未上市的公司通过把资产注入市值较低的公司,获得公司的控股权,利用其上市公司的地位完成重组上市。
样本潜在问题¶
借壳上市样本由于其本质已经发生根本性变化,如果不加以处理,会对研究结果造成干扰。例如,借壳上市公司会存在股价异常波动和财务数据失真两大问题。
如何处理¶
- 借壳上市的公司:视为纳入新上市股票,使用借壳上市日期对上市日期进行更新。在构建股票池时,该股票会被当作次新股而剔除。
- 被借壳公司:尽可能的将其从股票池中剔除。由于被借壳公司通常市值较小,市场表现低迷,因此我们重新构造股票池。
猜想
全面注册制后,借壳上市应该不再会是很常见的问题。
股票池构建¶
- 指数成分股股票池沪深 300 指数构造方式:计算样本空间内股票最近一年的 A 股日均成交金额与 A 股日均总市值;对样本空间股票在最近一年的 A 股日均成交金额由高到低排名,剔除排名后 50%;对剩余股票按照最近一年 A 股日均总市值由高到低排名,选取前 300 名作为沪深 300 指数样本。
- 中证 500 指数构造方式:在样本空间中剔除沪深 300 指数样本股以及最近一年日均总市值排名前 300 名的股票;将剩余股票按照最近一年日均成交金额由高到低排名,剔除排名后 20% 的股票;将剩余股票按照最近一年日均总市值由高到低进行排名,选取排名在前 500 名的股票作为中证 500 指数样本。
- 流动性 1500 股票池流动性 1500 构造的具体方式:每个交易日首先剔除 ST、次新股、停牌股,然后计算每只股票的交易金额历史 20 日平均,最后选取排名前 1500 只股票作为股票池,命名为流动性 1500。
异常值处理¶
- 均值标准差修正法
- Beat G. Briner 方法
- MAD 法
- 固定比率修正法
- 箱型图法
- 偏度调整的箱型图法
- Winsorize 缩尾处理
缺失值处理¶
剔除法¶
将存在遗漏数据的元素进行删除,得到一个完备的信息表,这是最为简单的一种处理方法。
适用前提:有大量缺失值的因子,或者存在大量缺失值的股票对象;这类因子或股票对象相对所有的数据量而言是很小
填充法¶
通过选择一些合适的值取填充空值,而找到合适的值。
分类:市场均值填充;行业均值填充;市值均值填充;算法填充。
因子标准化¶
考虑截面差异¶
- 适用前提:因子之间存在大小差异。
- 适用方法:在进行标准化时为了保存因子大小差异的信息,不适合采用排名法或排名正态标准化法,需要使用 z-score 方法。
考虑排名顺序¶
- 适用前提:构建零投资组合探索因子与收益率之间的关系时,只需要根据因子的排序情况对股票进行分组,而不用精确探索因子对收益率的影响程度。
- 适用方法:排名法:将原始因子值转换成排序值。该方法只关注因子的排序信息,不关注截面距离信息。