使用 sklearn 实现随机森林分类算法¶
基于随机森林分类算法,对客户流失进行分类预测,进行包外估计、特征重要性的展现和超参数调优。利用n_jobs多线程并行加速计算。
导入必要的包¶
Python
# 导入数据处理和绘图的包
import pandas as pd
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 随机森林相关的包
from sklearn import preprocessing
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
读取数据¶
Python
# 读取数据
data_train = pd.read_excel(
"../2022-10-30-decision-tree-classfication/BankChurners2.xlsx",
sheet_name=0,
engine="openpyxl",
)
data_test = pd.read_excel(
"../2022-10-30-decision-tree-classfication/BankChurners2.xlsx",
sheet_name=1,
engine="openpyxl",
)
划分训练集和测试集、特征和标签¶
Python
# 划分训练集和测试集、特征和标签
X_train = data_train.iloc[:, 2:]
y_train = data_train.iloc[:, 1]
X_test = data_test.iloc[:, 2:]
y_test = data_test.iloc[:, 1]
将字符型变量进行编码¶
Python
# 离散变量
discrete_features = [
"Gender",
"Dependent_count",
"Education_Level",
"Marital_Status",
"Income_Category",
"Card_Category",
"Total_Relationship_Count",
"Months_Inactive_12_mon",
"Contacts_Count_12_mon",
]
# 连续变量
continuous_features = X_train.columns.drop(discrete_features)
# 将特征转换为数值型
OrdinalEncoder = preprocessing.OrdinalEncoder()
X_train[discrete_features] = OrdinalEncoder.fit_transform(X_train[discrete_features])
X_test[discrete_features] = OrdinalEncoder.transform(X_test[discrete_features])
# 将标签转换为数值型
le = preprocessing.LabelEncoder()
y_train = le.fit_transform(y_train)
y_test = le.transform(y_test)
构建随机森林分类器,使用n_jobs=-1进行并行计算¶
n_jobs=-1代表使用所有的 CPU,实测可以将 CPU 使用率提升至 100%,计算时间相比默认的n_jobs=1下降约 50%。-
也可以指定使用 CPU 的数目,如
n_jobs=2。 -
关于使用 CPU 的数目和计算效率的关系,可以参考这篇帖子。
Python
# 构建随机森林模型
clf = RandomForestClassifier(oob_score=True, random_state=42, n_jobs=-1)
clf.fit(X_train, y_train)
# 在测试集上预测
在测试集上分类的效果¶
Python
# 在测试集上给出模型分类的效果
def evaluate(true, pred):
print("accuracy:{:.2%}".format(metrics.accuracy_score(true, pred)))
print("precision:{:.2%}".format(metrics.precision_score(true, pred)))
print("recall:{:.2%}".format(metrics.recall_score(true, pred)))
print("f1-score:{:.2%}".format(metrics.f1_score(true, pred)))
print("在测试集上给出模型分类的效果:")
Text Only
## precision recall f1-score support
##
## 0 0.93 0.83 0.88 490
## 1 0.97 0.99 0.98 2637
##
## accuracy 0.96 3127
## macro avg 0.95 0.91 0.93 3127
## weighted avg 0.96 0.96 0.96 3127
随机森林模型的包外估计¶
包外估计(out-of-bag estimate)是用未在训练集中出现的测试数据来作出决策的方法。
随机森林模型天然地从所有\(N\)个样本中随机地有放回地抽取\(N\)个样本作为训练集。对于每一个样本,它在\(N\)次有放回抽样中,始终没有被抽到的概率是:
\[
(1-\frac{1}{N})^N
\]
当样本量\(N\)足够大时,这一概率趋近于
$$ \begin{aligned} & \quad \lim_{N\to +\infty}(1-\frac{1}{N})^N\\ &=\frac{1}{e}\\ &\approx36.8\% \end{aligned} $$ 其中,关于上述推导中极限的求解可以参考这篇帖子。
既然有些样本没有被选为训练集,我们就可以用这些训练集来预测这些样本,得到预测的结果,这个过程就是包外估计。且可以进一步计算预测效果的评价指标。
值得注意的是,包外估计得到的误差是真实误差的无偏估计。因此,对于随机森林模型而言,没有必要对它进行交叉验证或用一个独立的测试集来获得误差的一个无偏估计。它可以在内部进行评估,即在生成过程中就对误差建立了一个无偏估计。这是一个很好的优点。
包外估计的更多介绍可以参考这篇帖子。
对比测试集和包外估计的模型分类效果,可以发现两者的准确率分别为 96.32% 和 95.9%,几乎一致。
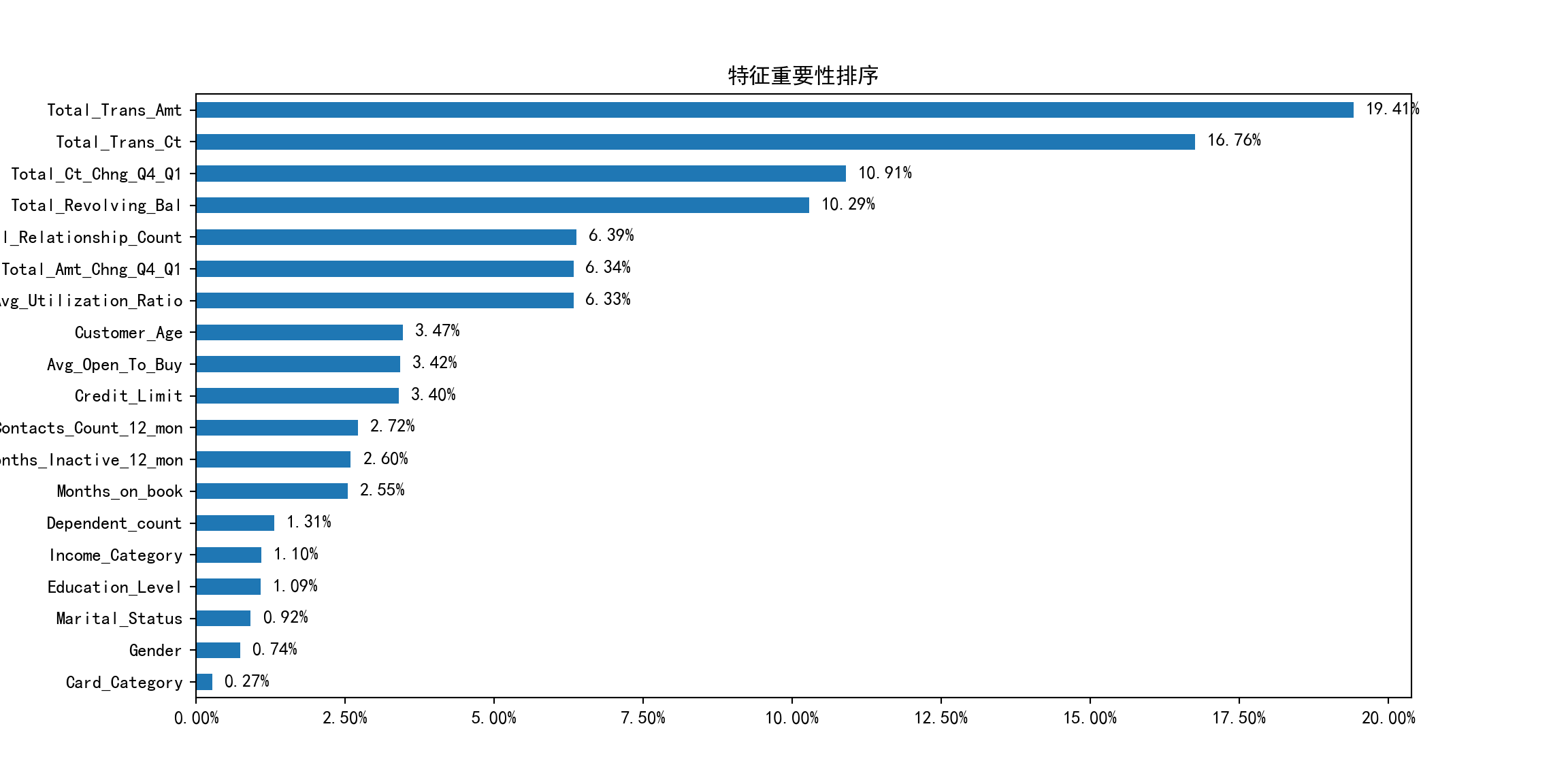
模型变量的重要性排序¶
Python
# 将特征重要性排序后绘图
ax = feat_importances.sort_values().plot(kind="barh", figsize=(12, 6))
# 设置横坐标格式
ax.xaxis.set_major_formatter(plt.FuncFormatter(lambda x, pos: "{:.2%}".format(x)))
# 设置标题
ax.set_title("特征重要性排序")
# 如果不需要显示特征重要性的大小数值,可以使用下面 2 行代码
# for container in ax.containers:
# ax.bar_label(container)
# 如果需要显示特征重要性的大小数值,可以使用下面的代码
x_offset = 0
y_offset = 0
for p in ax.patches:
b = p.get_bbox()
val = "{:.2%}".format(b.x1)
ax.annotate(val, (b.x1 + 0.002, b.y1 - 0.4))
参数敏感性分析¶
绘制不同超参数下的模型评价指标¶
Python
def plot_metrics(parameter, accuracy_all, precision_all, recall_all, f1_all):
plt.figure(figsize=(12, 6))
plt.plot(accuracy_all, label="accuracy")
plt.plot(precision_all, label="precision")
plt.plot(recall_all, label="recall")
plt.plot(f1_all, label="f1-score")
plt.legend()
plt.xlabel(parameter)
plt.title(f"不同{parameter}的模型评估指标")
plt.show()
遍历各超参数¶
Python
def tuning(parameter, parameter_name, parameter_range):
# 重抽样的次数
accuracy_all = pd.Series(index=parameter_range, dtype="float")
precision_all = pd.Series(index=parameter_range, dtype="float")
recall_all = pd.Series(index=parameter_range, dtype="float")
f1_all = pd.Series(index=parameter_range, dtype="float")
for parameter_value in parameter_range:
clf = RandomForestClassifier(
**{parameter: parameter_value}, random_state=42, n_jobs=-1
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy_all[parameter_value] = metrics.accuracy_score(y_test, y_pred)
precision_all[parameter_value] = metrics.precision_score(y_test, y_pred)
recall_all[parameter_value] = metrics.recall_score(y_test, y_pred)
f1_all[parameter_value] = metrics.f1_score(y_test, y_pred)
plot_metrics(parameter_name, accuracy_all, precision_all, recall_all, f1_all)
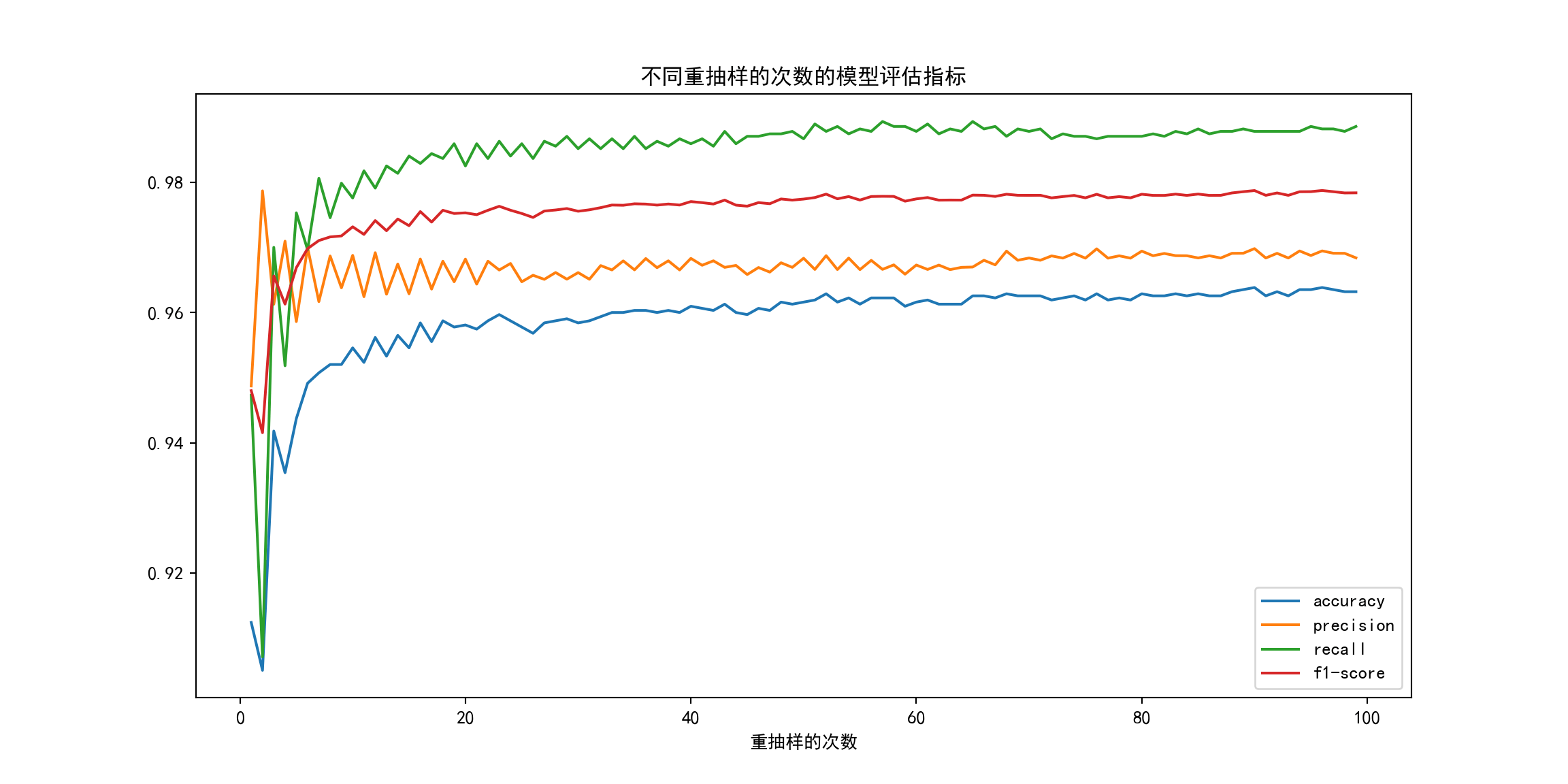
重抽样的次数 B¶
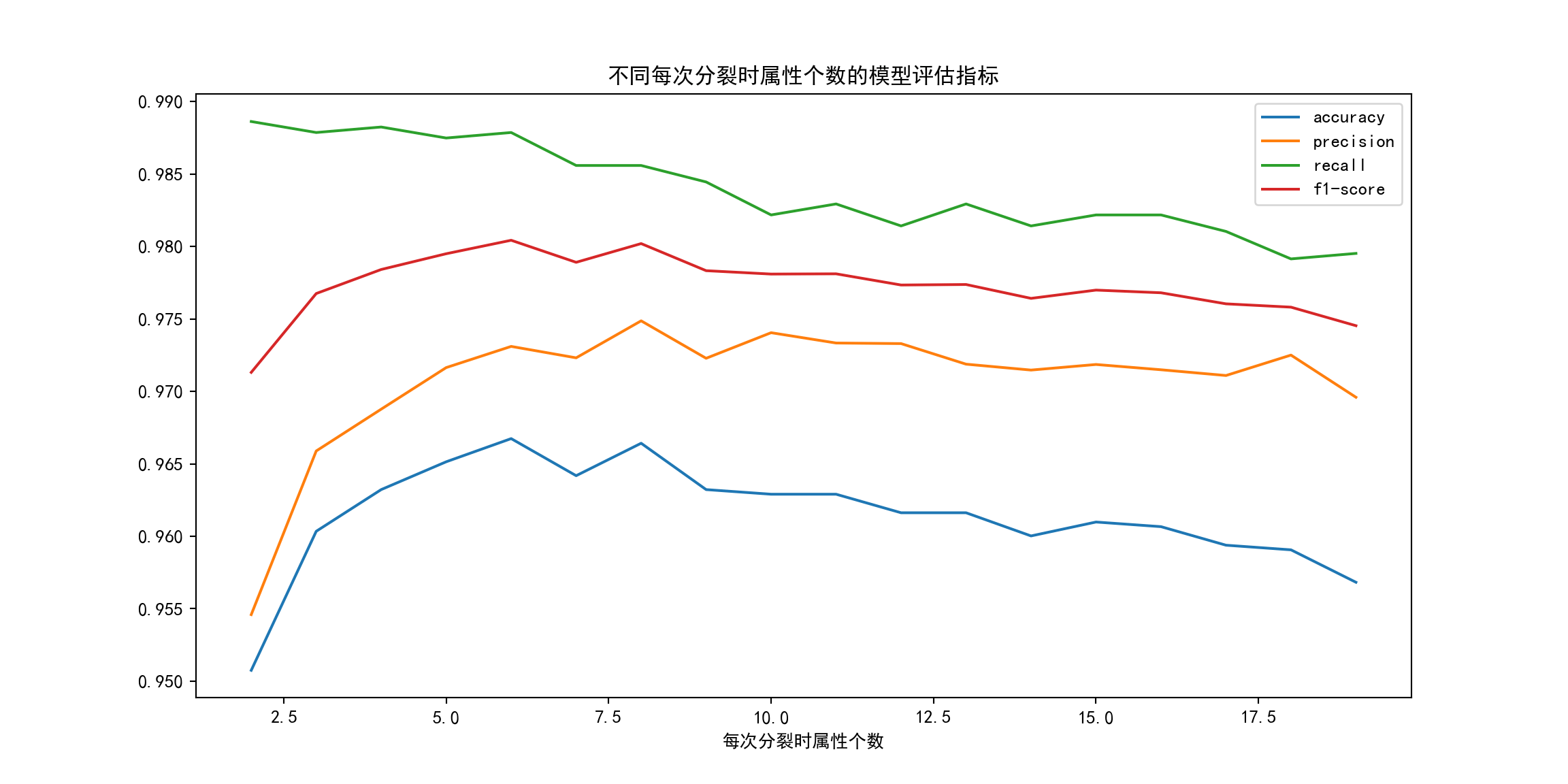
每次分裂时属性个数 m¶
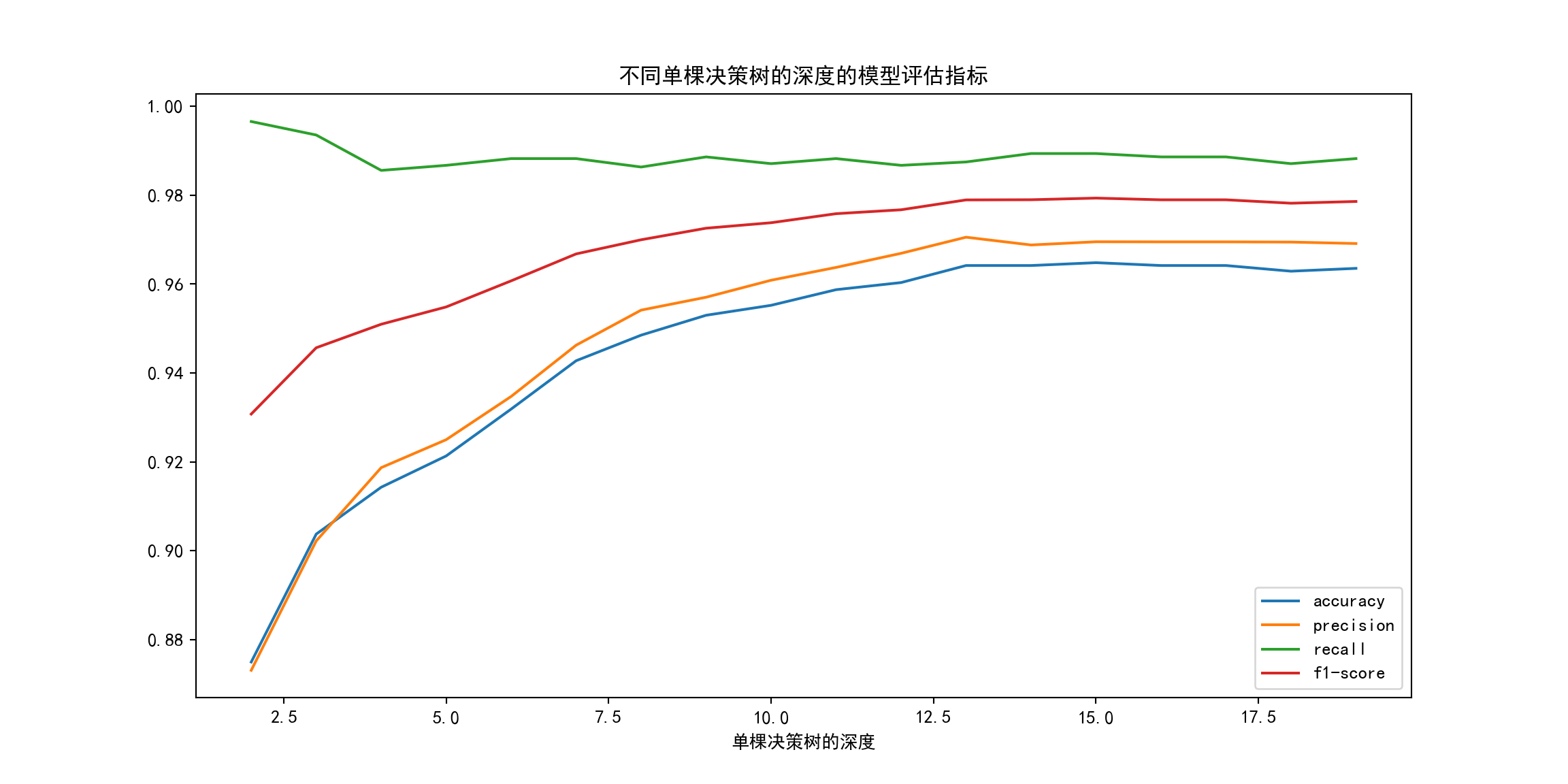
单棵决策树的深度¶