使用 Web Scraper 爬取私募排排网的基金数据¶
私募排排网的数据仅针对部分人群开放,因此在获取数据时有诸多不便。例如,网站需要用户登录才能访问、数据 CSS 样式类别名称被加密等,这些障碍使得我们无法通过常规的爬虫手段方便地获取数据。
本文尝试了多种方法爬取私募排排网的数据,包括 selenium、浏览器工作流自动化的 Automa 插件和嵌入在浏览器开发者工具的 Web Scraper 插件。最终可行且易用的方法是使用 Web Scraper 插件,它在制作和使用爬虫程序时都十分简便。

注意事项
本爬虫脚本的编写和分享仅旨在简化工作流程和促进计算机技术交流。该脚本并不具备对网站服务器造成破坏或干扰的能力。任何人在使用该脚本时所产生的后果与本人无关。请注意,使用爬虫工具可能涉及法律风险。在使用本脚本之前,请确保您已经详细了解并遵守适用的法律法规和相关规定。您应当自行承担使用本脚本所带来的任何法律责任和风险。
失败方法简述¶
selenium¶
selenium 可以模拟人类浏览器时的动作,配合 BeautifulSoup 等库,就可以实现对网页信息进行提取和解析。这篇帖子 曾介绍过使用 selenium 爬取豆瓣数据的方法。
在爬取私募排排网时,遇到的第一个问题就是需要用户登录。本文最初的实现思路是:先手动登录一次,将 cookie 信息保存到本地,后续即使用已有的 cookie 信息进行登录。但是,私募排排网也许能够识别出用户当前使用的是开发测试用的 chromedrive,它并不允许用户在这类不正常的环境下登录,具体体现为:用户名和密码登录时的右滑验证永远失败、手机扫描二维码登录时提示二维码无效等等。
Automa¶
Automa 是一款浏览器工作流自动化的插件。它可以在浏览器中做许多重复的工作,也包括爬虫,例如 YouTube 教程——新手如何零代码爬取天天基金网 | AutoMa 插件教程 01。
我按照该视频教程中的方法,确实可以在天天基金网中获取到干净的表格数据,但应用到私募排排网时就失效了。具体体现为:在获取文本时,需要指定数据所对应的 CSS 样式类别,用 Automa 获取到的 CSS 样式类别很难调试到正确。在执行工作流时,总会卡在“获取文本”这一步,其根本原因就是 Automa 不知道对应元素的位置。

Web Scraper¶
Web Scraper 是一款专门用于爬虫的浏览器插件。使用它时需要按 F12 打开开发者模式,在最右侧找到“Web Scraper”选项。

详细的工作流程可以参考:
- Web Scraper 官方示例——爬取多元素(强烈建议观看,只有 1 分钟的教程,但关键步骤讲解得非常清楚)
- Bilibili 教程——Web Scraper 爬取数据教程【不用写代码的爬虫,快速获取数据】
- YouTube 教程——用爬虫工具从网页中扒数据并导入 Excel 表格
观看完这些教程后,我的一些经验是:
选中大表格¶
对一个大表格,选中它的 selector 的 Type 为 Element,并且要勾选 Multiple。假设这个 selector 名字叫做 fund-data,它的 Parent Selector 是默认的 _root。
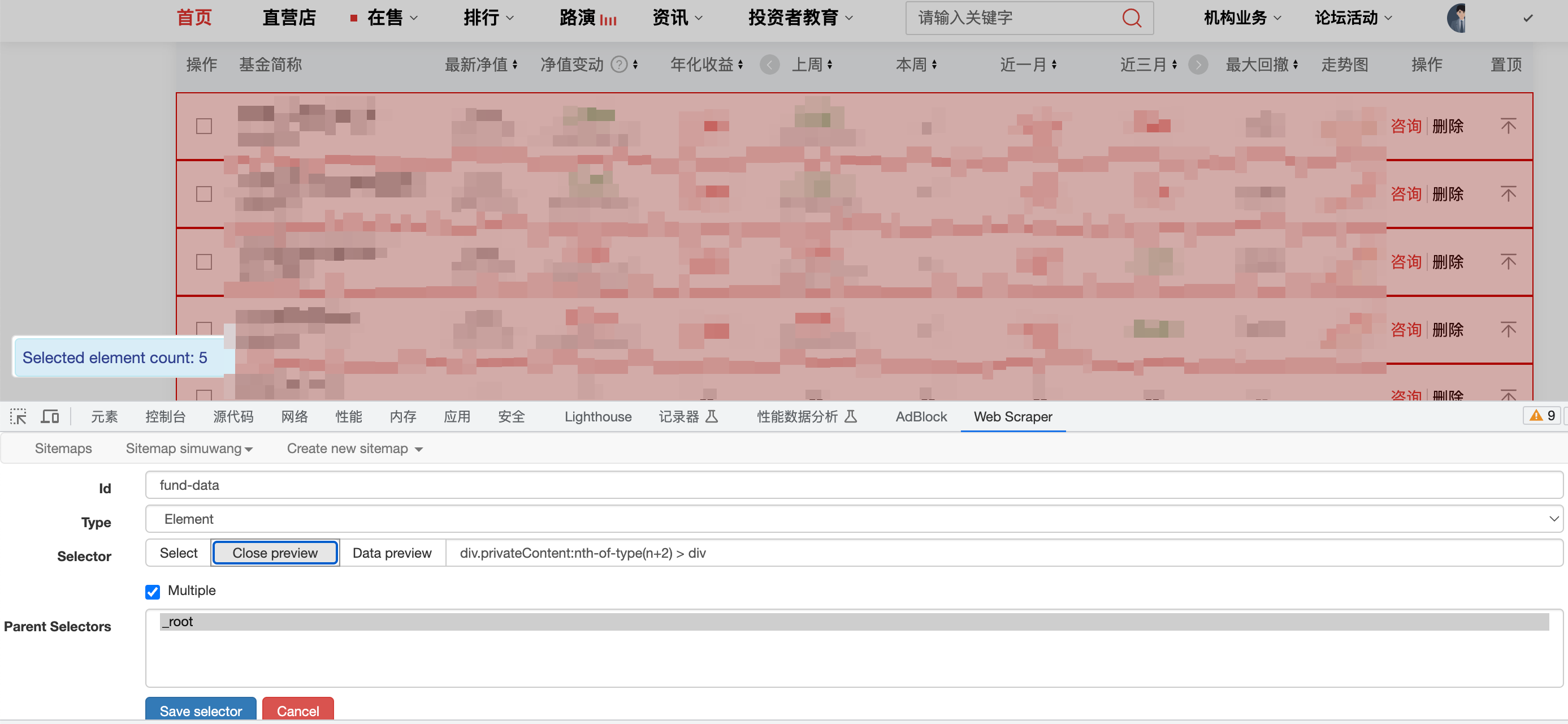
针对表格中的每一行¶
对于一个大表格内部的每一行,我们应该先进入 fund-data 这个 selector 内部,再新建子 selector。否则,如果接下来新建的 selector 与 fund-data 这个 selector 同级的话,那么最终爬取到的数据并不是并排、干净的。

对于每一行数据,对每个需要的字段(即每一列)分别新建一个 selector。这时可以选择 Type 为 Text,不需要勾选Multiple,也不需要点击其他行,只需要点击第一行的一个元素即可。
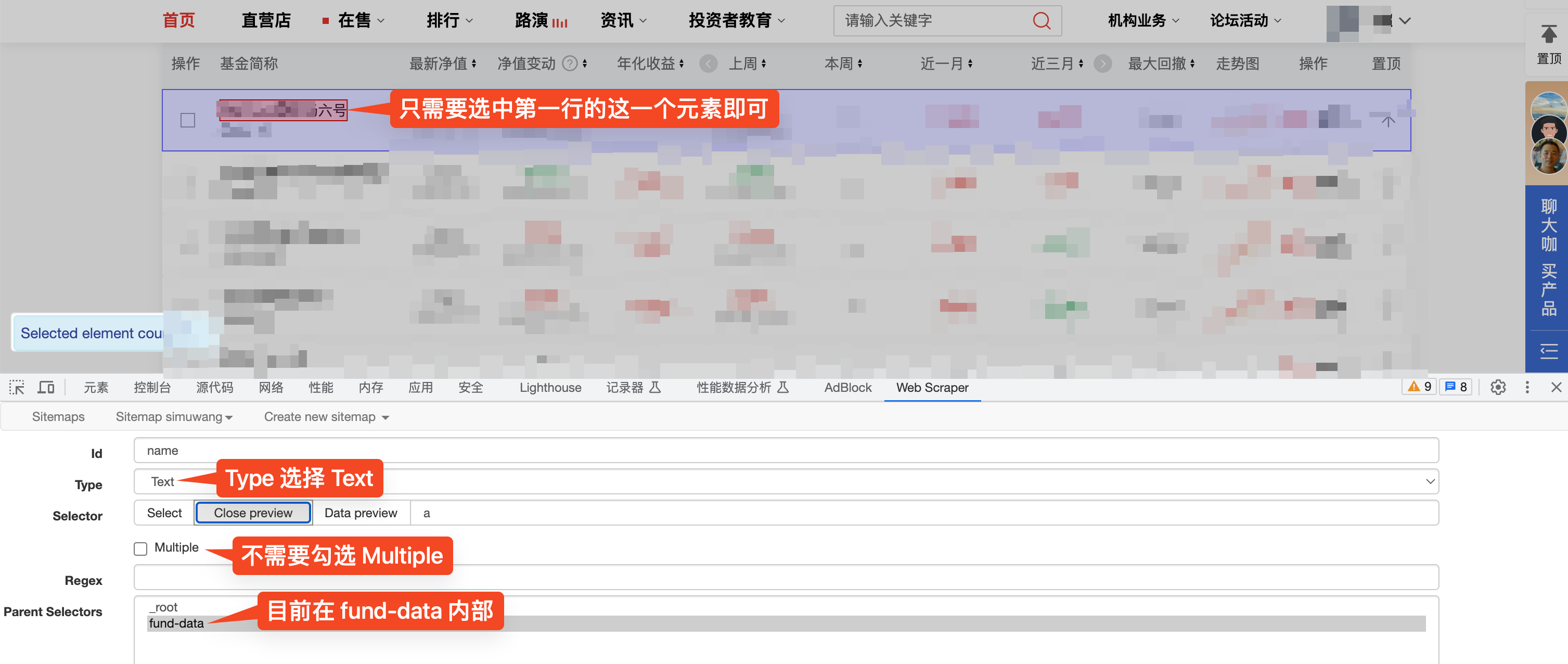
重复编写多个子 selector,将所有需要的字段都纳入。这里需要注意的是,Web Scraper 在识别元素时,有可能会识别出错。例如,我选中了表格中的一个单元格,它位于第 3 列,并且字体是绿色的。起初,Web Scraper 使用 green 来为元素定位的,这导致后续批量爬虫的时候错误地将其他位置的绿色文本放入第 3 列。因此,我们要仔细检查,出现错误时可以手动修改 selector 的参数值。

运行爬虫程序¶
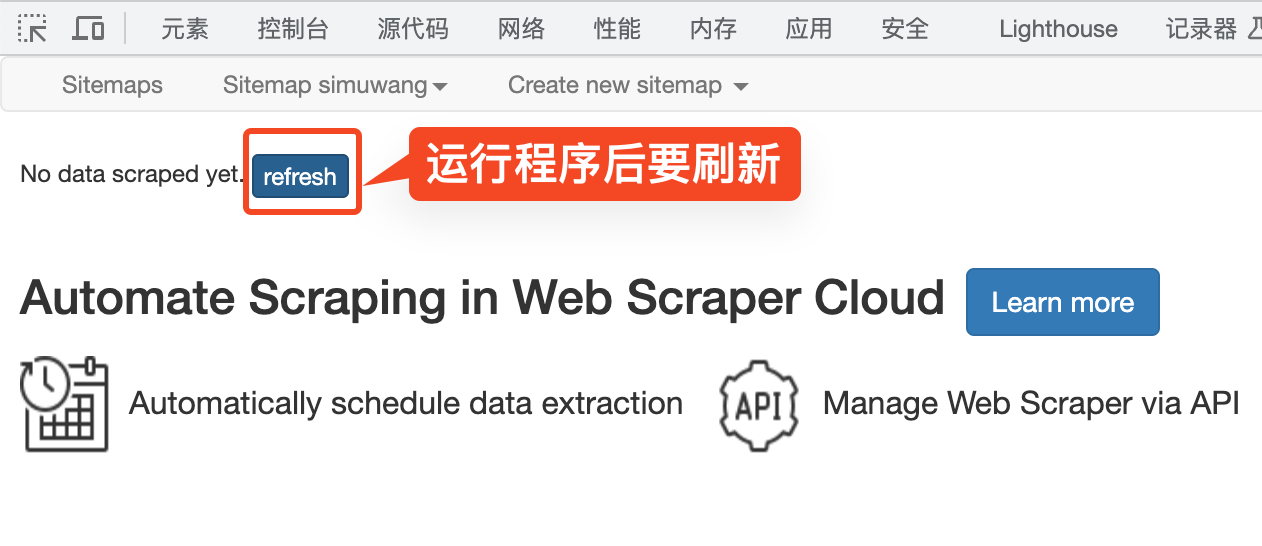
编写完成后,可以点击 Scrape 运行爬虫程序。
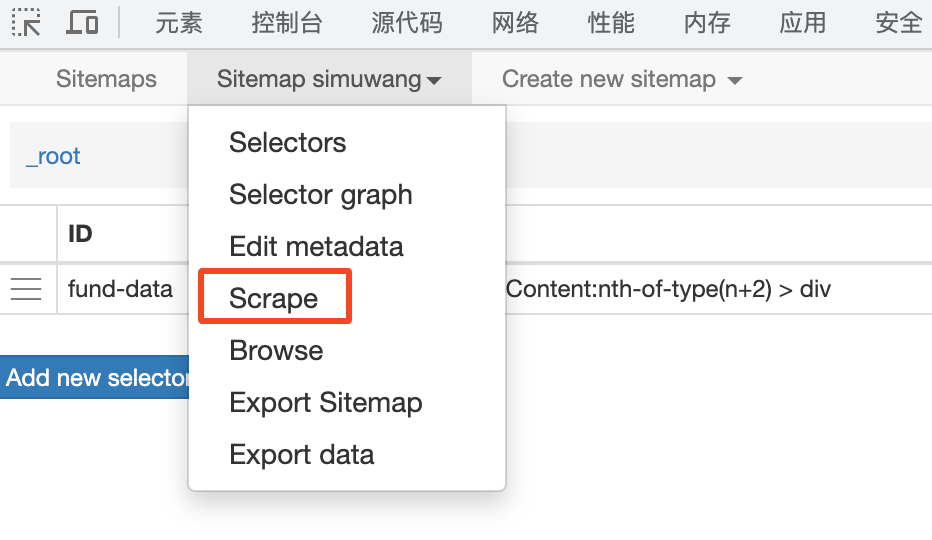
运行成功后,刷新即可看到最新获取的表格数据。
导出数据¶
可以将最新获取到的数据导出为 xlsx 或 csv 表格。

分享与导入爬虫程序¶
我们编写的程序本质上是一段 JSON 格式的数据。(推荐使用 jsoncrack 查看数据的组织结构。)将这段 JSON 格式的数据分享给他人,就可以方便地分享爬虫程序了。
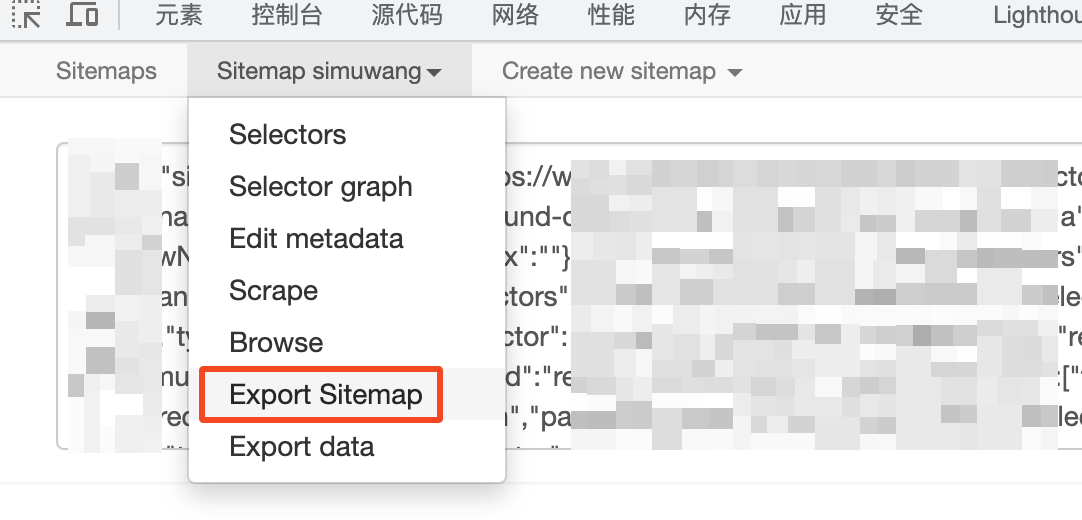

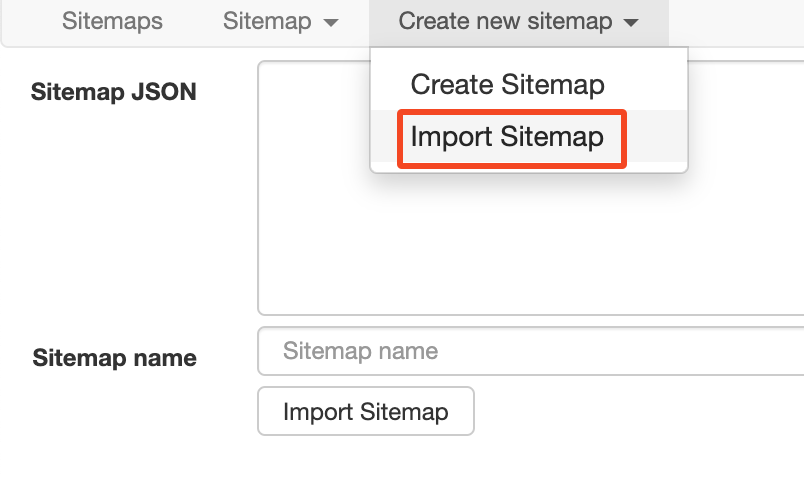
若有现成的 JSON 文件,可以直接导入。