基于深度学习的中文文本错误识别与纠正模型总结¶
中文写作是许多人工作和生活的重要内容之一,在写作中使用准确的用词和清晰的句法,能够帮助文本的阅读者快速且正确地理解作者所表达的意思。如果一段中文文本存在大量错字(例如由于书写错误导致出现不存在的汉字)、别字(每个汉字都存在,但由于字音、字形相似但意义不同而混淆了搭配)和语法错误,这将使读者感到十分困惑,影响阅读体验。
在错别字层面,现代数字化的文本大多由用户通过输入法进行编辑,输入法内置词典的正确性使得文本不易形成错字,但由于输入时选中文字的疏忽、对词语搭配具有错误的认知等原因,别字的问题依然经常出现。在正式的书面写作中,使用未经组织的、口语化的文本也经常导致语法错误的出现。在语法层面,由于用户在文本输入法,语音输入法使用上的随意性,后续又缺少审核,极易产生语法错误内容。近年来随着自媒体的热潮,人人都是信息的生产者,互联网上语法错误的内容暴增,但语法不通顺的文本极大影响了用户体验。
为实现中文文本纠错、提高汉语使用的正确性,同时减少人工校验的成本,本文初步探讨了基于深度学习的中文文本错误识别与纠正模型,包括它的核心目标、从输入数据到输出数据的流程、训练模型需要用到的数据来源、使用的前沿模型以及现有论文的测试效果等。
核心目标¶
针对中文文本,模型的核心目标是:
- 识别输入的中文文本是否有错误,即二分类目标;
- 若有错误,进一步给出错误类型,例如错别字、语序不当、成分残缺等;
- 给出识别出错误的文本位置;
- 给出纠正后的正确文本。
垂直领域应用¶
现有大语言模型在通用领域的表现已经十分令人满意,我们可以针对某些垂直领域构建特定任务的语言模型。例如,法律、医疗等专业领域具有大量的语料知识库,且这些专业领域对文本正确性的要求较高,因此后续研究适合对这些垂直领域进行训练,以求使用更小的模型、更少的训练和推理速度,达到与通用大语言模型接近甚至更好的效果。
应用流程¶
当模型构建完成后,用户需要输入一段不超过一定长度限制(例如不超过 512 个字符)的中文文本,模型将对字符进行嵌入编码和位置编码,经过深度网络模型后输出纠正后的正确文本对应的编码,最后将编码转换成对应的中文字符。
将原始输入文本与纠正后的文本进行对比,即完成了对文本的错误识别与纠正。关于错误类型的分类问题,可能还需要模型具有多任务学习能力,即同时输出错误类型中的一种或多种。
数据¶
在训练阶段,使用有标注或无标注的数据训练深度学习模型。
对于有标注的数据,其数据格式为:
- 标注:0 表示该语句无错误,1 表示该语句有错误;
- 源语句:原始语句;
- 目标语句:正确的语句。若标注为 0,则目标语句与源语句相同。
现有结构化的中文文本错误与纠正数据集一般只包含数千至数万条样本,而大量的中文预料是无标注的。对无标注的中文语料,我们可以进行如下数据增强操作:
- 删除一个字符的概率 10%;
- 增加一个字符的概率为 10%;
- 使用字典中任意一个字符替换字概率为 10%;
- 重新排列字的顺序,通过对每个原始字的位置编码增加一个标准差为 0.5 的正态分布权重,然后将新的位置编码从小到大排序,提取出原始位置编码列表的索引位置作乱序后的字排列。
使用上述的文本错误生成方法所产生的错误句子与原句子配对,这在某种程度上可以算作一条纠错语料,因为该错误语句与人为错误语句都是由字的增、删、替换和重新排列操作所造成的。
已有文献使用的训练数据有:
| 训练语料 | 类型 |
|---|---|
| CGED(2016-2018) | 标注数据 |
| SIGHAN(2014 2015) | 标注数据 |
| NLPCC2018 | 标注数据 |
| Lang-8 | 非标注数据 |
| 中文维基百科 | 非标注数据 |
此外,还有一些文献构造了“易混淆词语集”进行纠错。
模型¶
Transformer 模型¶
当前自然语言处理领域的前沿模型是 Transformer 模型,它摒弃了传统序列到序列模型中 CNN 或 RNN 的方法和模块,开创性地将自注意力机制作为编解码器的核心,不仅训练速度快,而且解决了 RNN 处理长距离文本可能导致语义丢失的问题。
Transformer 模型开创性地使用自注意力机制对句子进行建模。输入文本向量中通常包含大量信息,但是某些文本可能会比其他部分对决策更有帮助,我们希望模型多关注与该单词相关的信息,并忽略其他不相关的信息。自注意力机制可以通过计算句子中词语之间的相关性来捕捉句子内部的相关性,并解决长程依赖的问题。
自注意力的计算公式为:
其中,\(Q\)、\(K\) 和 \(V\)分别代表查询、键和值,三者在自注意力机制中均为输入句子向量本身。
Transformer 模型由若干部件组成,其中最关键的组件是编码器和解码器。
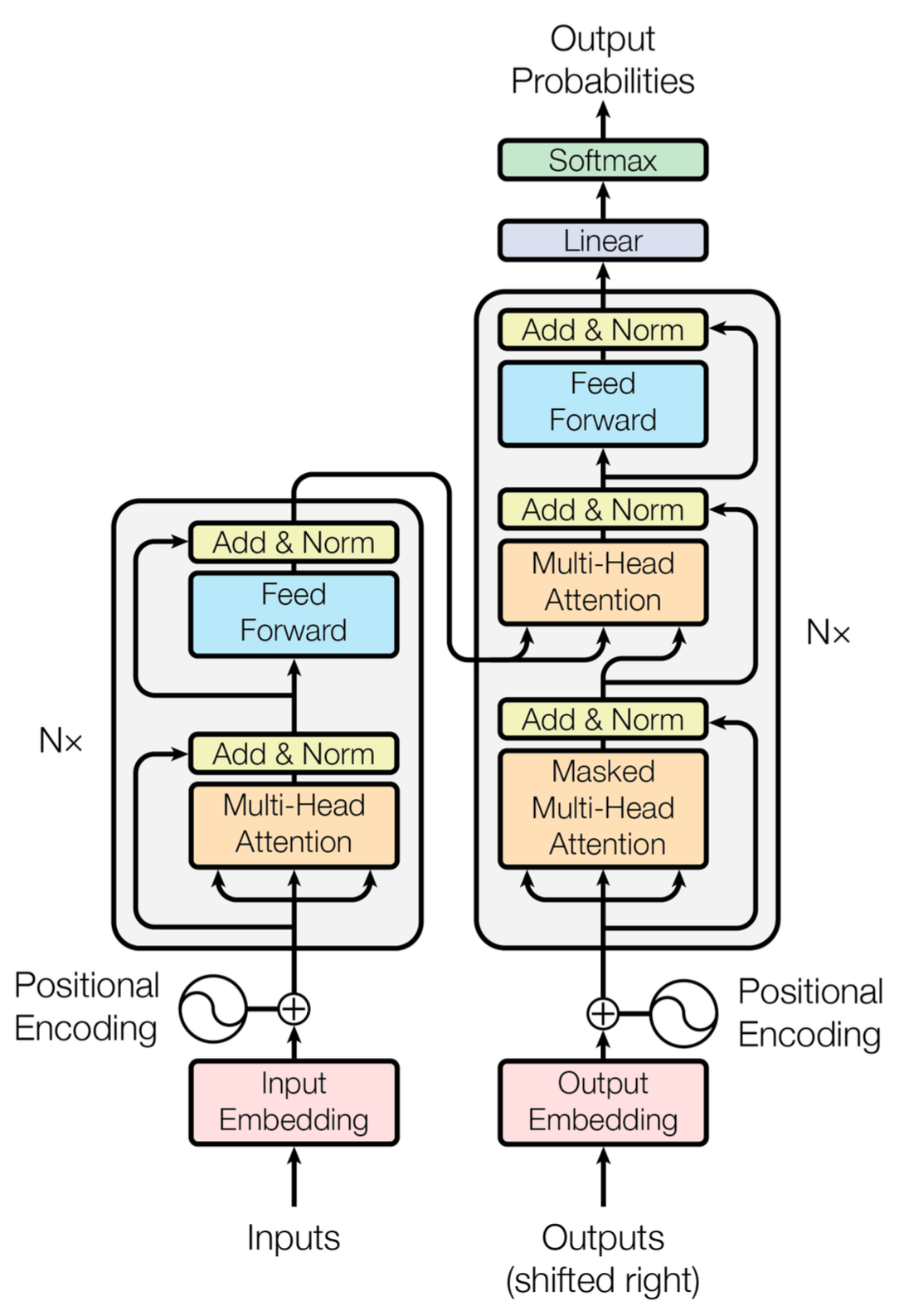
首先将输入的文本字符串通过词嵌入(Embedding)转换为 512 维的词向量,再加上位置编码(这篇帖子介绍了位置编码),即可利用每个数据的位置信息。
编码器¶
编码器部分由 N 个编码器(Encoder)构成。这 N 个编码器结构相同,互相独立,不共享参数。词嵌入只发生在底层的编码器,也就是说只有最底层编码器接收的输入是由输入部分传来的词向量列表,其他编码器的输入都是上一层编码器的输出。编码器可分为两层:多头注意力层和前馈网络层。多头注意力层里包含了多头注意力(Multi-Head Attention)和求和与归一化(Add&Norm);前馈神经网络层包含了前馈神经网络(Feed Forward)和求和与归一化(Add&Norm)。
解码器¶
解码器部分由 N 个解码器(Decoder)堆叠而成,这里的 N 与解码器部分的 N 保持一致。解码器中的网络层与编码器中的编码层大致相同,只有多头自注意力层的操作方式与编码器中的多头自注意力层的操作方式不太相同。在解码器中,自注意力层只能处理输出序列中更靠前的位置,这是因为在 softmax 步骤前会加入掩码,把后面的位置隐去。之所以加入掩码是因为在一些生成的自注意力张量中,张量的值可能是由未来信息计算得到。未来信息被看到是因为训练时会把整个输出结果都一次性进行嵌入,但在预测时只能看到出现在当前字符之前的历史信息。
预训练模型¶
在自然语言处理任务中,预训练模型能够提升下游任务的表现。较为知名的中文预训练模型有Chinese-LLaMA-Alpaca、ChatGLM-6B、Chinese-BERT-wwm、Chinese-Word-Vectors、Chinese-XLNet等。
微调¶
大语言模型具备潜在的通用任务解决能力,微调 (Fine-tuning) 等技术能够挖掘大语言模型的能力,在特定任务上拥有更好的表现。1
微调阶段的目标是减少训练参数的规模,常见的微调方法有:
- 添加新参数层,例如 Adapter 层;
- 重参数化,例如 Lora;
- 对原有参数进行选择。
模型效果评价¶
对于中文文本错误识别与纠正问题,常见的评价指标包括准确率(Precision)、召回率(Recall)及\(F_{0.5}\)。假设 \(e\) 是模型对错误文本纠错建议的集合,\(ge\) 是该错误文本的标准的纠错建议集合,具体的计算方式如下:
语法纠错任务选择 \(F_{0.5}\) 作为评价指标而非 \(F_{1}\) 值的原因在于,对于模型纠正的错误中,纠错的准确性大于纠错建议数量,所以将准确率的权重定为召回率的两倍大小,以期得到一个更加优质的纠错模型。换句话说,我们希望模型给出的纠错建议确实是需要被纠正的。
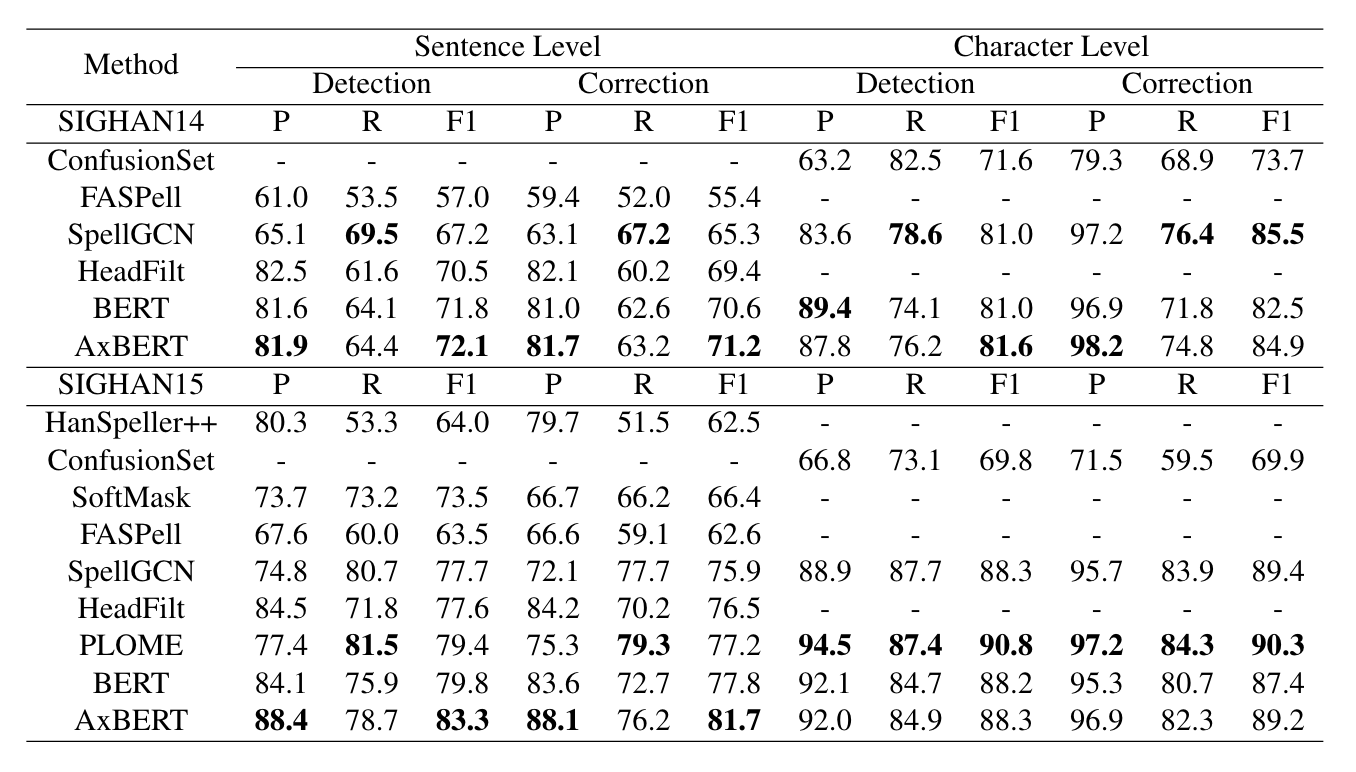
Zhao et. al. (2022) 整理了 2021 年中文文本纠错的模型效果排行榜单:https://destwang.github.io/CTC2021-explorer/,其中最优模型的准确率、召回率和 \(F_{1}\) 值均超过 \(60\%\)。Wang et. al. (2022)2 使用 AxBERT 模型在中文数据集上取得了接近 \(80\%\) 的精确率、召回率和 \(F_{1}\) 值。
-
Zhao W X, Zhou K, Li J, et al. A survey of large language models[J]. arXiv preprint arXiv:2303.18223, 2023.MLA ↩
-
Wang, Fanyu, Huihui Shao, and Zhenping Xie. “AxBERT: An Explainable Chinese Spelling Correction Method Driven by Associative Knowledge Network,” September 29, 2022. https://openreview.net/forum?id=nZGu4Ltnl5. ↩