每月底买入行业内 PB 较低的股票:一个简单的选股策略回测¶
本文回顾了量化投资策略设计与分析课程的一次课前练习。本练习给定的数据都比较整洁、规范,选股逻辑也比较简单清晰,是一个很好的实现选股回测的练习机会。
策略描述¶
策略描述
请把给定的股票数据,根据行业分类(申万一级行业),分别对每一行业的股票按 PB 由低到高分为 5 组,每月第一个交易日买入那些上月 PB 处于所在行业排名最低 20% 分位组(即 PB 由低到高排序的第一组)的股票,持有 1 个月,每月换仓一次,计算该投资组合的持仓年化收益率和夏普比率,并画出累计净值曲线。
数据描述¶
行业数据¶
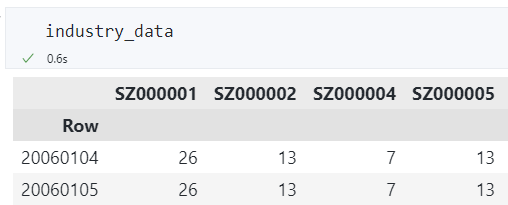
下图中每行代表一个交易日,每列代表一只股票,每个单元格代表该股票在该交易日所处的申万一级行业代码。
市净率 PB 数据¶
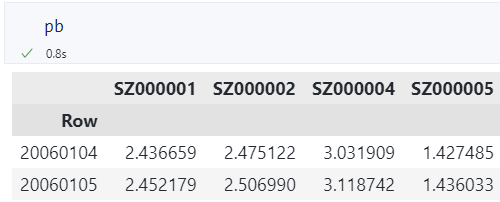
下图中每行代表一个交易日,每列代表一只股票,每个单元格代表该股票在该交易日的市净率 PB 值(Price-to-book ratio)。
个股收益率数据¶
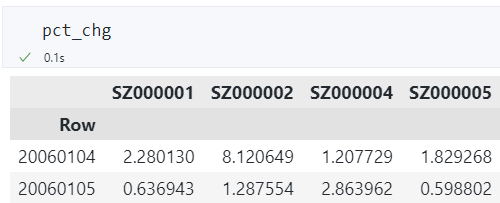
下图中每行代表一个交易日,每列代表一只股票,每个单元格代表该股票在该交易日的日收益率。
回测代码¶
导入包¶
import pandas as pd
import numpy as np
import ast # 用于解析字符串
import swifter # 用于加速 .apply() 函数,并显示进度条
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
读取数据¶
# 读取数据
# 个股行业数据
industry_data = pd.read_csv("../../data/Q4/Q4_industry_data.csv", index_col=0)
# 个股 PB 数据
pb = pd.read_csv("../../data/Q4/Q4_PB.csv", index_col=0)
# 个股日收益率数据
pct_chg = pd.read_csv("../../data/Q4/Q4_pct_chg.csv", index_col=0)
经过上述代码读入的数据如下图所示,注意我们将日期作为了索引。
数据转换,将宽型数据框转换为长型序列¶
# 将宽型数据框转换为长型序列
industry_data = industry_data.stack()
pb = pb.stack()
pct_chg = pct_chg.stack()
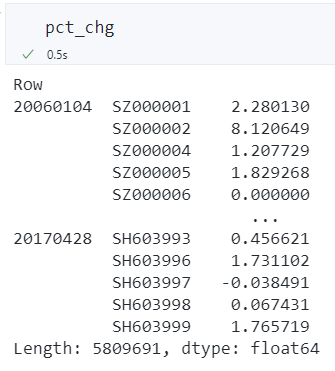
数据如下图所示,注意日期和股票代码组成了双重索引,且股票代码的索引没有名字。
修改双重索引的名称¶
# 指定 multiindex 的名称
industry_data.index.names = ["date", "code"]
pb.index.names = ["date", "code"]
pct_chg.index.names = ["date", "code"]
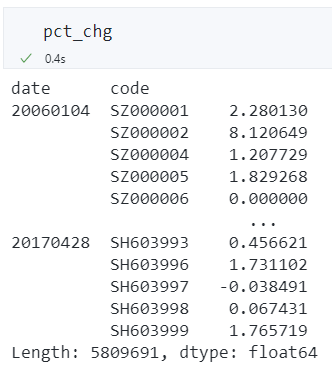
数据如下图所示,我们为 multiindex 指定了名称。
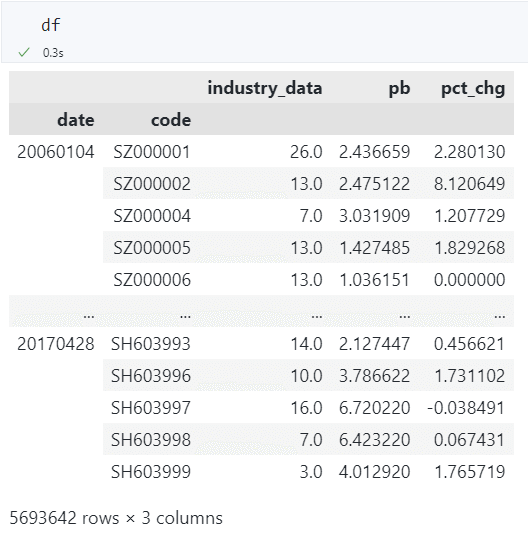
合并序列为数据框¶
使用 .join() 和 .concat()都可以,实测 .join() 速度稍快一些,需要 30 秒。
# 将三个序列合并为一个数据框
df = (
industry_data.rename("industry_data")
.to_frame()
.join(pb.rename("pb").to_frame(), how="inner")
.join(pct_chg.rename("pct_chg").to_frame(), how="inner")
)
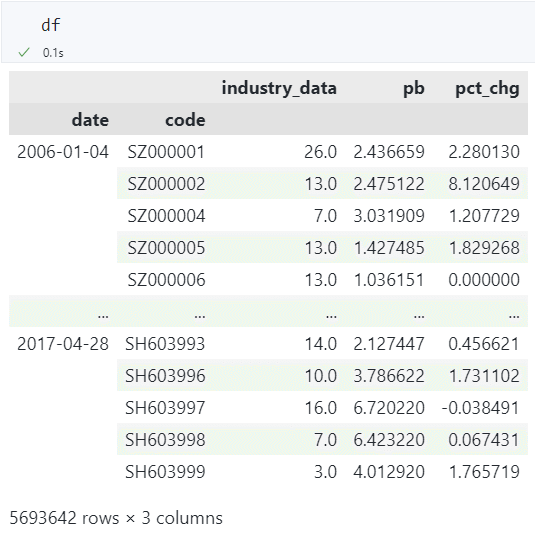
修改索引为日期格式¶
为了对日期数据进行判断(例如判断是否为一个月的最后一天),我们可以将字符串格式的日期转换为 datetime 格式。
只需要修改 data 索引,所以 df.index.levels[1] 保持不变即可。
# 修改索引为日期格式
df.index = df.index.set_levels(
[pd.to_datetime(df.index.levels[0].astype(str)), df.index.levels[1]]
)
在每月最后一个交易日进行条件选股判断下月持仓¶
判断某个交易日是否为当月的最后一个交易日¶
逻辑为:先对所有交易日排序,比较某个交易日 A 与它的下一个交易 B,如果两个交易日的月份不同,则说明交易日 A 是 其所在月份的最后一个交易日。
# 判断日期是否为所在月份的最后一个交易日
def is_last_trading_day_of_month(date):
try:
# 获取下一个交易日
next_date = dates_list[dates_list.get_loc(date) + 1]
# 判断下一个交易日是否为下一个月份的第一个交易日
return next_date.month != date.month
except:
# 如果出现异常,说明当前日期为所有交易日中的最后一个交易日
return True
# 获取所有交易日
dates_list = df.index.get_level_values(0).unique().sort_values()
# 计算每个月的最后一个交易日
last_trading_day_of_month = dates_list[dates_list.map(is_last_trading_day_of_month)]
得到的日期如下所示,可以看到有 136 个月份。

提取出每月最后一个交易日的行业和市净率 PB 值数据¶
# 选取最后一个交易日的 industry 和 pb 数据
df_last_trading_day = df.loc[last_trading_day_of_month][["industry_data", "pb"]]

对月底的市净率 PB 值进行判断¶
按照策略的逻辑,选出每个行业中 PB 值最小的 20% 的股票。
def select_stock(x):
"""
选出每个行业中 pb 值最小的 20% 的股票
Args:
x (pd.DataFrame): 一天的数据,包含 industry_data 和 pb 两列
Returns:
stock (pd.Series): 该天选出的股票
"""
# 提取所有的 industry_data
all_industry = x["industry_data"].unique()
# 用于存储选出的股票
selected_stocks = []
# 对每个 industry_data 进行循环
for industry in all_industry:
# 提取该 industry 的数据
industry_data = x[x["industry_data"] == industry]
# 筛选出 pb 值最小的 20% 的股票
industry_data = industry_data[
industry_data["pb"] < industry_data["pb"].quantile(0.2)
]
stocks = list(industry_data.index.get_level_values(1))
selected_stocks.extend(stocks)
return selected_stocks
# 选出每个月底的 pb 最低的 20% 的股票
selected_stocks = df_last_trading_day.groupby(level=0).apply(lambda x: select_stock(x))

得到了一个 Series,它的每一个单元格是当月选出的股票 List,将作为下月的持仓。
如何将字符串形式的列表解析成真正的列表对象
如果我们此时将 selected_stocks 这个 Series 导出到本地,如果今后用 pd.read_csv() 读取它时,会发现读进来的数据是字符串形式的列表,它不是真正的列表!
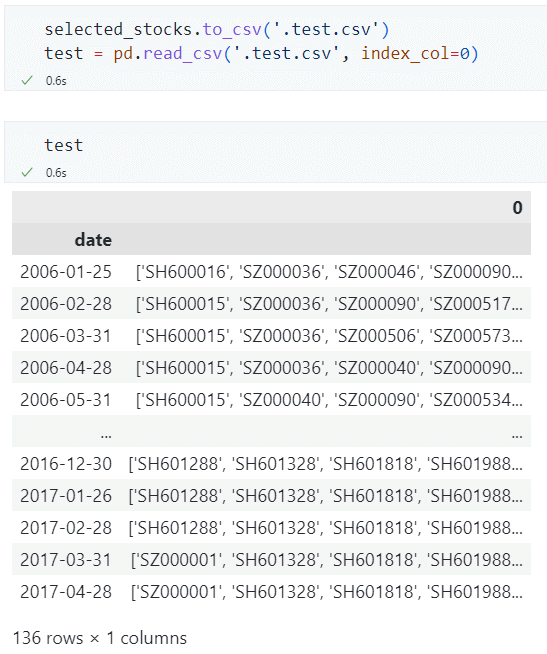
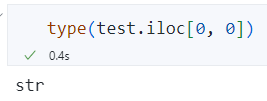
如果想要将字符串形式的列表解析成真正的列表对象,可以用 ast 这个包。
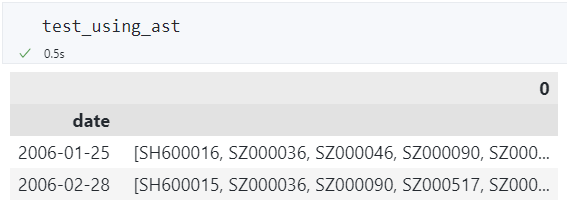
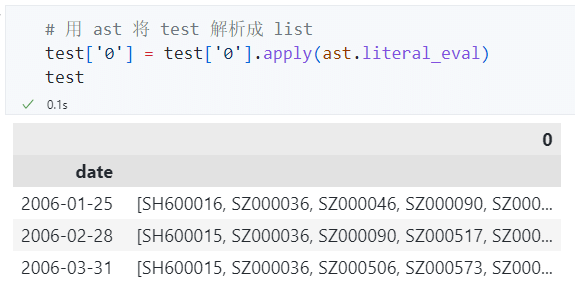
或者在读取数据之后再用 ast 解析成 List:
将选股结果下移一格,变为持仓数据¶
将数据向下移动一格,即可得到每月的持仓数据。
date
2006-01 None
2006-02 [SH600016, SZ000036, SZ000046, SZ000090, SZ000...
2006-03 [SH600015, SZ000036, SZ000090, SZ000517, SZ000...
2006-04 [SH600015, SZ000036, SZ000506, SZ000573, SZ000...
2006-05 [SH600015, SZ000036, SZ000040, SZ000090, SZ000...
...
2016-12 [SH601288, SH601328, SH601818, SH601988, SZ000...
2017-01 [SH601288, SH601328, SH601818, SH601988, SZ000...
2017-02 [SH601288, SH601328, SH601818, SH601988, SZ000...
2017-03 [SH601288, SH601328, SH601818, SH601988, SZ000...
2017-04 [SZ000001, SH601328, SH601818, SH601988, SZ000...
Length: 136, dtype: object
提取个股收益率,构造投资组合¶
多重索引使得数据的列数很少,但行数很多。对几百万行的数据进行索引筛选是非常耗时的,我们可以将数据先转成宽型,即每只股票对应一列。

计算投资组合收益率¶
先生成一个空的数据框,用于存放投资组合每日的收益率
# 生成每日的组合收益率
portfolio_daily_return = pd.DataFrame(
index=df.index.get_level_values(0).unique(),
columns=["daily_return"],
)
用每日持仓股票的收益率均值,作为投资组合的收益率。这一算法较为简便,但并不准确。我在 这篇文章 中有讨论过这个问题。
# 计算每日的组合收益率
def calculate_portfolio_daily_return(date):
"""
计算每日的组合收益率
Args:
date (pd.Timestamp): 日期
Returns:
daily_return (float): 组合收益率
"""
# 获取当天的股票代码
stocks = selected_stocks.loc[date.strftime("%Y-%m")]
# 如果股票代码为空,说明当天没有持仓,收益率为 0
if stocks is None:
return 0
# 获取当天的收益率
daily_return = pct_chg.loc[date.strftime("%Y-%m-%d"), stocks].mean()
return daily_return
使用swifter 包,加速 .apply() 函数的运行,并显示进度条。
import swifter
portfolio_daily_return["daily_return"] = portfolio_daily_return.swifter.apply(
lambda x: calculate_portfolio_daily_return(x.name), axis=1
)
Pandas Apply: 100%|██████████| 2750/2750 [00:02<00:00, 944.27it/s]
将每日收益率除以 100,得到每日收益率。
# 将每日收益率除以 100
portfolio_daily_return["daily_return"] = portfolio_daily_return["daily_return"] / 100
第一个月的收益率都是 0,因为首月没有持仓,要到第二个月初才能基于第一个月底数据进行选股。
绩效评价¶
计算年化收益率、年化波动率和夏普比率¶
# 计算年化收益率
def annualized_return(returns, periods_per_year=250):
return (1 + returns).prod() ** (periods_per_year / len(returns)) - 1
# 计算年化波动率
def annualized_volatility(returns, periods_per_year=250):
return returns.std() * np.sqrt(periods_per_year)
# 计算夏普比率
def sharpe_ratio(returns, risk_free_rate=0, periods_per_year=250):
return (
annualized_return(returns, periods_per_year) - risk_free_rate
) / annualized_volatility(returns, periods_per_year)
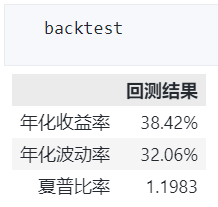
print(f"年化收益率:{annualized_return(portfolio_daily_return['daily_return']) * 100:.2f}%")
print(
f"年化波动率:{annualized_volatility(portfolio_daily_return['daily_return']) * 100:.2f}%"
)
print(f"夏普比率:{sharpe_ratio(portfolio_daily_return['daily_return'])}")
年化收益率:38.42%
年化波动率:32.06%
夏普比率:1.1982897843149716
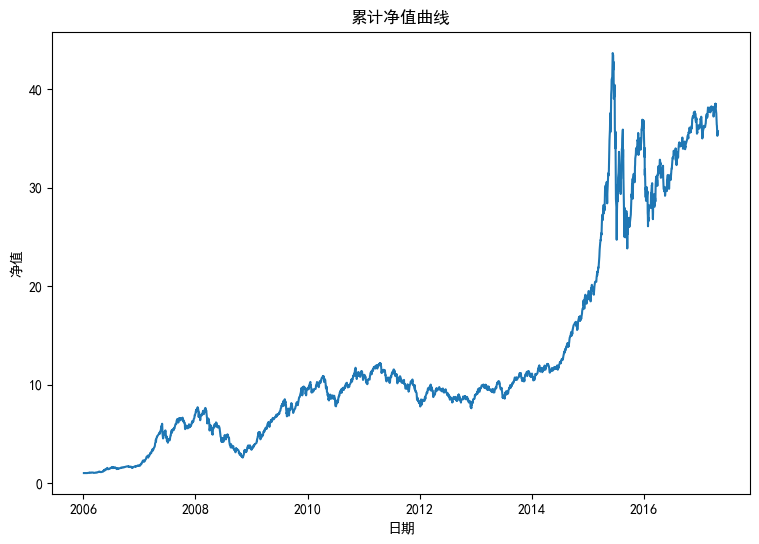
绘制累计净值曲线¶
# 绘制累计净值曲线
net_value = (portfolio_daily_return["daily_return"] + 1).cumprod()
fig = plt.figure(figsize=(9, 6))
ax = fig.add_subplot(1, 1, 1)
ax.plot(net_value)
ax.set_title("累计净值曲线")
ax.set_xlabel("日期")
ax.set_ylabel("净值")
plt.show()
# 保存图片
fig.savefig(
"../result/Q4_data_backtest.png",
format="png",
facecolor="white",
bbox_inches="tight",
)
将绩效评价结果导出到本地¶
注意将小数转换为百分比的字符串形式,方便在本地表格中查看。
backtest = pd.DataFrame(
index=["年化收益率", "年化波动率", "夏普比率"],
data=[
str(round(annualized_return(portfolio_daily_return["daily_return"]) * 100, 2))
+ "%",
str(
round(
annualized_volatility(portfolio_daily_return["daily_return"]) * 100, 2
)
)
+ "%",
str(round(sharpe_ratio(portfolio_daily_return["daily_return"]), 4)),
],
columns=["回测结果"],
)