LightGBM 的用法¶
LightGBM 是一种基于决策树的梯度提升机(GBM)算法,它是一种快速、准确的机器学习算法,可以用于分类和回归问题。
本文介绍了 LightGBM 的使用方法和代码示例,并记录了自定义损失函数、打印训练过程、迭代次数参数等问题的解决方法。
![]()
导入包¶
读取数据¶
# 读取数据
data = pd.read_pickle("./data.pkl")
# 划分特征和标签
X = data[["feature_1", "feature_2"]]
y = data["label"]
# 划分训练集和测试集
train_X, test_X, train_y, test_y = train_test_split(
X,
y,
test_size=0.2,
shuffle=False,
)
# 转换为 Dataset 数据格式
lgb_train = lgb.Dataset(
train_X,
train_y,
free_raw_data=False, # (1)!
)
lgb_eval = lgb.Dataset(
test_X,
test_y,
reference=lgb_train,
free_raw_data=False,
)
-
lgb.Dataset(free_raw_data=False)代表转换为 Dataset 数据格式后仍然保留原始数据。默认free_raw_data=True。如果后续需要用到原始数据的索引、列名等信息,可以保留它,后续可用train_data.get_data()提取原始数据。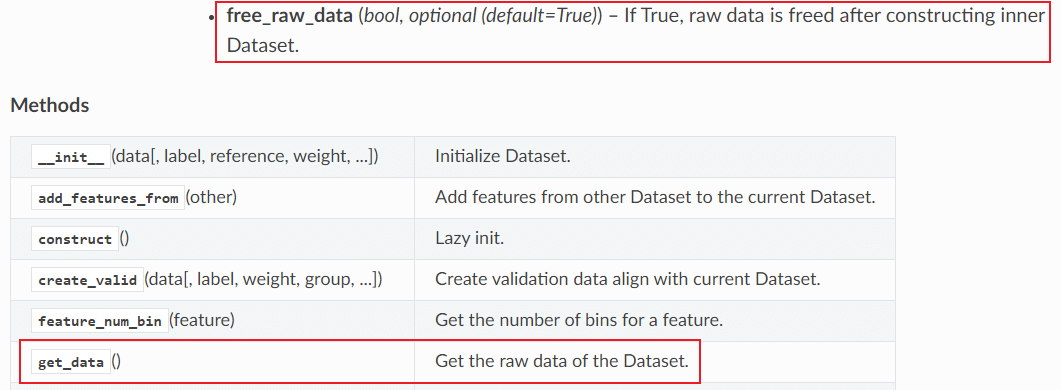
训练模型和预测¶
lightGBM 可以使用两种方式训练模型:
- 原生的
lgb.train()接口; - 类似于的
sklearn的lgb.LGBMRegressor()接口。
下面分别介绍两种接口的使用方式。
使用 lgb.train() 接口进行训练¶
先定义参数:
params = {
"task": "train",
"boosting_type": "gbdt", # 设置提升类型
"objective": "regression", # 目标函数
"metric": "mse", # 评估函数
"num_leaves": 31, # 叶子节点数
"learning_rate": 0.1, # 学习速率
"feature_fraction": 0.9, # 建树的特征选择比例
"bagging_fraction": 0.8, # 建树的样本采样比例
"bagging_freq": 5, # k 意味着每 k 次迭代执行 bagging
"verbose": 1, # <0 显示致命的,=0 显示错误(警告), >0 显示信息
}
再使用 lgb.train():
model = lgb.train(
params,
lgb_train,
num_boost_round=100,
valid_sets=lgb_eval,
callbacks=[
lgb.early_stopping(stopping_rounds=20, verbose=True), # (1)!
lgb.log_evaluation(), # (2)!
],
)
-
设置提前停止的判断标准:若验证集上的评价指标超过 20 轮没有变好,则停止迭代。参考:lightgbm.early_stopping()
-
打印每轮迭代的验证集评价指标。参考:lightgbm.log_evaluation() 和 GitHub Issue: 不能输出每轮迭代的评价指标
预测¶
使用 lgb.LGBMRegressor() 接口进行训练¶
先创建一个 LGBMRegressor:
model = lgb.LGBMRegressor(
boosting_type="gbdt",
objective="regression",
num_leaves=31,
learning_rate=0.1,
n_estimators=100,
)
再调用 LGBMRegressor.fit():
model.fit(
train_X,
train_y,
eval_set=[(test_X, test_y)],
callbacks=[
lgb.early_stopping(stopping_rounds=20, verbose=True),
lgb.log_evaluation(),
],
)
lgb.early_stopping() 和lgb.log_evaluation() 的使用方法和 使用lgb.train()接口进行训练时一样,这里不在赘述。
预测¶
高阶用法¶
自定义损失和评估函数¶
fobj¶
可以编写一个函数作为 fobj传入到 lgb.train() 中,或传入 params 中的 objective(具体使用方法取决于 lightGBM 的版本,v3.3.2是前者):

fobj 接受预测的标签值 preds 和训练数据 train_data 作为参数。
我们可以从 train_data 中获取真实的标签值 trues ,再基于预测的标签值 preds和真实的标签值trues 计算一阶导数 grad 和二阶导数 hess 作为返回值。
下面是一个示例,它计算了 MSE 损失函数的一阶导数和二阶导数。
自定义损失函数,以 MSE 为例
def custom_objective(preds, train_data):
# 提取真实标签值
trues = train_data.get_label()
# 计算一阶导数和二阶导数
diff = preds - trues
# 一阶导数
grad = diff
# 二阶导数
hess = np.ones_like(diff)
return grad, hess
参考:
feval¶
模型在验证集上的评估值影响了 early_stopping 的判断。如果我们自定义了损失函数,还可以自定义评估函数,在每次迭代时输出自定义的评估函数值。
仍然以 MSE 损失函数为例,计算损失值。
自定义评估函数,以 MSE 为例
将 fobj 和 feval 传入 lgb.train() 中:
model = lgb.train(
params,
lgb_train,
num_boost_round=100,
valid_sets=lgb_eval,
callbacks=[
lgb.early_stopping(stopping_rounds=20, verbose=True),
lgb.log_evaluation(),
],
fobj=mse_objective,
feval=mse_metric,
)
细节理解¶
num_boost_round 和 n_estimators¶
上文我们已经提到,lightGBM 可以使用两种方式训练模型。这两种训练方式的参数写法并不一致,例如:
lgb.train()接口通过在lgb.train()中指定num_boost_round=100来指定最大迭代次数。lgb.LGBMRegressor()接口通过在lgb.LGBMRegressor()中指定n_estimators=20来指定最大迭代次数。
许多讨论都表明,这两个参数的作用是一致的。参考:GitHub Issue: inconsistent parameter names: "n_estimators"
我们可以测试:当同时指定两个参数时,它们使用的优先级是怎样的。
使用 lgb.train() 接口:
- 先在
params中指定"n_estimators": 20; - 再在
lgb.train()中指定num_boost_round=80。
看看训练的信息:
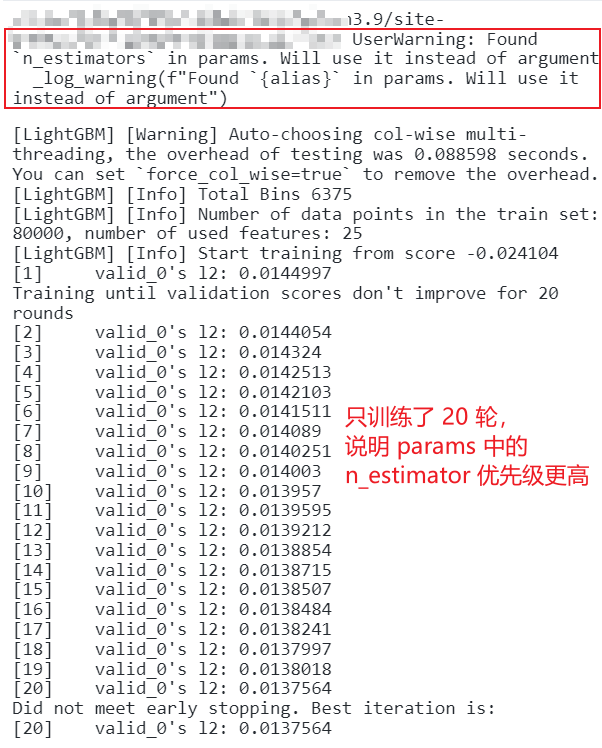
只训练了 20 轮,说明 params 中的 n_estimator 优先级更高。
个人理解
num_boost_round 和 n_estimators 都是别名,我们指定了一个就行。如果指定了两个(也就是在 params 和 train() 中都指定),那么会以 params 中的为准。
